温州医科大学
- 如果Q-Q图中样本点均匀地落在一条直线的附近,可以判断数据服从正态分布。( )
- 在做发展趋势预测问题时,神经网络模型与微分方程模型一样能得到与原始数据相贴合的函数,故都适合做中长期预测。( )
- 用于判别分析模型的检验时,前瞻与刀切混合式比刀切式更加客观。( )
- 神经网络的拓扑结构分为前向、层内互连、全连接三种。( )
- 神经网络模型可以实现无监督的分类以及多分类问题。( )
- 为了更好的促进医学技术进步,当代医学生不仅要掌握专业的医学知识和技能,还应该了解神经网络等现代智能模型进行医学研究和实践应用的特点和流程。( )
- 对于评价判别模型效果的三级指标
 ,
,
其值越大,则该模型效果越好。( ) - 当变量间的量纲不同时,作主成分分析前需要将数据标准化,在matlab中,将数据标准化的函数是score( )。( )
- 用于判别分析模型的检验时,回顾式比前瞻式更加客观。( )
- 一室模型三种用药函数增减性一样。( )
- 若数据的偏度接近0,则可认为数据的分布是对称分布。( )
- 数据中只要有缺失值,不管多或少,都可以采用直接删除的方法,对模型的结果都不造成任何影响。( )
- 距离判别法只能使用欧氏距离判别。( )
- 约翰·麦卡锡(John McCarthy)是首先提出“人工智能”概念的科学家。( )
- 二维插值时,只能对网格型数据点进行插值,无法对散点型数据进行插值。( )
- Matlab中一维插值的命令vq = interp1(x, v, xq, ’method’)当用于数据加密时,则xq往往赋比原始数据中横坐标x更密集的取值。( )
- Logistic模型 告诉我们当人口总数达到极限值的一半时,人口的变化率达到最大值。( )
- 要求连续且光滑函数曲线的最值点,往往先求此函数导数为0的极值点。( )
- “回归”最早是由英国生物学家、统计学家Galton在研究儿子身高与父亲身高之间的遗传问题时提出的。( )
- 如果一时间序列有明显的季节性变动,那么它一定不是平稳时间序列。( )
- 关于支持向量机,下列说法正确的有( )
- 主成分分析的用途有( )。
- SIR模型指出了传染病的以下特征:( )
- 经典的传染病模型有哪些( )
- 数据拟合和数据插值的区别在于( )
- 白噪声{εt }满足的条件是( )。
- 关于判别分析前对用于判别的数据指标的准备正确的有( )
- 可能合理的血药浓度区间是( )。
- 在线性回归分析中,参数估计所用的方法不正确的是( )
- 支持向量机实现二分类的基本原理是找到一个决策面,使得( )
- 我国在新冠疫苗研制和新冠疫情防控方法的( )方面水平都达到国际先进水平。
- 关于支持向量机的优点,下列说法正确的有( )
- 下列关于回归分析正确的是( )。
- 反映数据的集中趋势的描述性统计量有( )。
- 以下属于无监督的分类方法有( )
- 在Matlab中使用神经网络模型实现分类或判别的方式包括( )
- 下列哪些是首先提出“人工智能”概念的科学家( )
- 数据插值的目的主要在于( )
- 关于神经网络模型的说法错误的是( )
- 合作研究丙型肝炎病毒而获得2020年诺贝尔奖的科学家有( )。
- 中国科学家杨焕明院士团队的研究项目属于( )研究方向的。
- 急救时较好的用药方式是( )。
- 若零均值平稳序列{Xi },其样本ACF和PACF都呈现拖尾性,则对{Xi}可能建立( )。
- 最早研究传染病数学模型的是( )
- 以下是某个疾病诊断模型对100个样本判别结果的误差矩阵(Confusion Matrix),
则该诊断模型的灵敏度为( )
- 下列方法中,属于填充缺失值的方法是( )。
- 率先把模糊数学与生物医学联系了起来的是( )。
- 以下不属于有监督的分类方法有( )
- 在matlab中,距离判别法用的函数为( )。
- matlab中,求平均值的函数是( )。
- 关于医学诊断智能化的描述错误的是( )
- 关于激活函数Sigmoid函数
 下列说法正确的是( )
下列说法正确的是( ) - 在对两个变量x, y进行线性回归分析时,有下列步骤: ①对所求的线性回归方程做出解释;②收集数据(xi , yi), i=1,2,…, n; ③求线性回归方程;④求相关系数;⑤根据收集数据绘制散点图,则下列操作中正确的是( )
-
 是几阶微分方程( )
是几阶微分方程( ) - 能检验数据所在总体服从泊松分布的检验法是( )。
- 若峰度等于0,则数据分布是( )。
- 用微分方程数学模型来描述人口理论的科学家是( ) 。
- 利用自相关图判断一个时间序列的平稳性,下列说法正确的是( )
- 关于医学诊断中判别模型的ROC曲线,下列说法错误的是( )
- 根据n个数据点
 来拟合函数
来拟合函数 中的参数
中的参数 时,以下哪个说法是正确的( )
时,以下哪个说法是正确的( )
A:对 B:错
答案:对
A:对 B:错
答案:错
A:错 B:对
答案:错
A:对 B:错
答案:错
A:错 B:对
答案:对
A:错 B:对
答案:对
A:错 B:对
答案:对
A:错 B:对
答案:对
A:对 B:错
答案:错
A:对 B:错
A:错 B:对
A:错 B:对
A:对 B:错
A:错 B:对
A:错 B:对
A:错 B:对
A:错 B:对
A:错 B:对
A:错 B:对
A:错 B:对
A:它无法进行非线性可分样本的判别分析 B:它属于有监督的判别分析模型 C:当出现异常值时,它将无法建立判别函数 D:它属于机器学习的算法
A:可以消除共线性,做主成分回归 B:可以用来评价 C:可以判别样品属于哪一类 D:可以降维
A:传染病都会消失 B:种群不可能因为某种传染病而绝灭 C:当人群中有人得了某种传染病时,此疾病并不一定流传,仅当易受感染的人数超过阀值时,疾病才会流传起来 D:疾病并非因缺少易感染者而停止传播,相反,是因为缺少传播者才停止传播的,否则将导致所有人得病
A:SIR模型 B:SEIR 模型 C:SIS模型 D:SIRS模型
A:数据拟合许多较少的数据点,数据插值需要较多的数据点 B:数据拟合可用来做长期预测,数据插值适合做对内预测或短期预测 C:数据拟合是使得拟合函数曲线反映数据点的发展趋势,数据插值是使得插值函数曲线穿过数据点 D:数据拟合函数类型少,数据插值函数类型多
A:任意s≠t, 有cov(εs , εt)=0 B:对于任一时刻 t , 有E(εt)=0 C:对于任一时刻 t , 有D(εt)=σ2 D:白噪声是平稳时间序列
A:指标值的获取包括图像识别、文本识别和数据库技术等 B:指标要根据与判别目标的关联性来选取 C:用于判别分析的指标越多越好 D:有时需要对指标消除量纲
A:[10,30] B:[15,35] C:[10,+∞) D:[0,15]
A:贝叶斯估计法 B:最大似然估计法 C:最小二乘估计法 D:EM算法
A:支持向量对应的两个间隔边界的距离尽可能的远,且其中线即为决策面 B:两类样本分别在决策面的两边(侧) C:样本在决策面上 D:所有样本到决策面的距离尽可能远
A:新冠病毒疫苗接种总剂次和覆盖人数。 B:新冠病毒疫苗研制。 C:新冠肺炎发病率低。 D:新冠肺炎死亡人数少。
A:它具有较好的鲁棒性 B:它不仅可进行有监督的分类,还可进行无监督的分类 C:相比于神经网络模型,它可防止出现对训练样本的过度拟合现象 D:它不仅能进行线性分类,还可以进行非线性分类
A:在回归分析中,可用残差平方和判断模型的拟合效果,残差平方和越大,模型的拟合效果越好 B:在回归模型的检验中,t检验法是对回归系数是否为0的检验 C:在回归分析中,可用残差图判断模型的拟合效果,残差点比较均匀地落在水平的带状区域中,说明选用的模型拟合效果好,带状区域宽度越窄,说明拟合精度越高 D:两个变量的相关系数R的绝对值越大,说明两个变量的相关关系越强
A:平均值 B:中位数 C:四分之一分位数 D:众数
A:聚类分析 B:支持向量机SVM C:主成分分析法 D:贝叶斯Bayes判别
A:其他都不对 B:打开分类器或模式识别工具箱(app) C:自编程序搭建网络并设定网络参数以实现运算 D:调用软件自带的各类神经网络对应的函数
A:马文·明斯基(Marvin Minsky) B:赫伯特·西蒙(Herbert Simon) C:艾伦·纽厄尔(Allen Newell) D:克劳德·香农(Claude Shannon)
A:对内预测 B:中长期预测 C:数据加密 D:得到数据规律
A:由于神经网络模型的结构和学习算法等原理模拟了生物神经网络的机制,则可部分实现人脑的认知、联想和信息的综合处理 B:神经网络模型从提出至今一直处于高速发展,没有经历过低潮期 C:神经网络模型只在工业科技领域发挥作用,对于医学研究的应用非常有限 D:人工神经网络就是对生物神经网络的真实写照
A:Rice) B:迈克尔· 霍顿(Michael Houghton) C:莫特拉姆(Mottram) D:哈维· 阿尔特(Harvey James Alter) E:查尔斯·M·赖斯(Charles
A:氨基酸DNA序列的分析 B:流行病的规律与预测 C:心脑血管疾病的预测 D:药效学中的动力学分析
A:恒速静脉注射 B:快速静脉注射 C:肌肉注射 D:口服
A:ARMA(1,1) B:AR(2) C:MA(2) D:MA(1)
A:Bernoull B:Logistic C:Ross D:Malthus
A:82% B:90% C:36% D:72%
A:回归填充 B:3σ原则 C:Q-Q图 D:主成分分析
A:拉特飞·扎德(Lotfi Zadeh) B:威廉·哈维(William Harvey) C:卡尔·皮尔逊(Karl Pearson) D:布莱尔(Blair)
A:BP神经网络 B:距离判别法 C:聚类分析 D:支持向量机SVM
A:classify( ) B:std( ) C:mode( ) D:corrcoef( )
A:mode( ) B:mean( ) C:cov( ) D:var( )
A:医学诊断智能化能一定程度的改善医疗环境、缓解医疗水平的不平衡 B:人工智能在某些疾病的诊断上已经完全不需要专业医生的参与 C:将人工智能应用于医学诊断前,需要应用者先对用于诊断的特征指标进行筛选和设定 D:医学诊断智能化的发展离不开图像识别技术、机器学习算法和医疗信息系统的支持
A:对输入的加权和有放大作用 B:其输出值域在(-1,1) C:由于其导数方便计算,所以当使用反向传播算法时,很容易推导出学习神经网络中的权重的更新方程 D:实现线性变换
A:③②④⑤① B:①②⑤③④ C:②④③①⑤ D:②⑤④③①
A:1 B:4 C:5 D:3
A:P-P图 B:K-S检验 C:S-W检验 D:直方图
A:与正态分布的陡缓程度相同 B:对称峰 C:尖顶峰 D:平顶峰
A:马尔萨斯(Malthus) B:莫特拉姆(Mottram) C:弗朗西斯·哈里·康普顿·克里克(Francis Harry Compton Crick) D:詹姆斯·杜威·沃森(James Dewey Watson)
A:自相关系数衰减为零的速度缓慢 B:自相关系数很快衰减为零 C:自相关系数一直为正 D:在相关图上,呈现明显的三角对称性
A:曲线上的点表示该判别模型在某个阈值时对样本的识别能力 B:曲线上最靠近左上角的点往往称为最佳临界点 C:曲线下方的面积越大,则该判别模型效果越差 D:曲线上的点越靠近左上角,即灵敏度越高、误判率越低,代表该阈值下的判别效果越好
A:要求出合适的参数
 的值,使得偏差平方和
的值,使得偏差平方和 最小
B:要求出合适的参数
最小
B:要求出合适的参数 的值,使得
的值,使得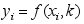 C:要求出合适的参数
C:要求出合适的参数 的值,使得偏差和
的值,使得偏差和 最小
D:其他都不对
最小
D:其他都不对
温馨提示支付 ¥5.00 元后可查看付费内容,请先翻页预览!

