提示:内容已经过期谨慎付费,点击上方查看最新答案
数学建模
以下程序的输出结果是( )。
j = ''
for i in "12345":
j += i + ','
print(j)
- 若简单线性回归方程的系数的假设检验结果是P<0.05,则可以认为两变量间( ) 。
- 在n个顶点的有向图中,每个顶点的度最大可为( )
- 对同一资料做多重线性回归分析,若对两个具有不同个数自变量的回归方程进行比较,应选用的指标是( )。
- 下列是偏微分方程的是( )
- 因子分析模型中原始变量可以表示为( )和特殊因子之和。
- 以下表达式,正确定义了一个集合数据对象的是( )。
- 某医院急诊室同时只能诊治一个病人,诊治时间服从指数分布,每个病人平均需要15分钟。病人按泊松过程到达,平均每小时到达3人。则服务强度为( )
- 区间
 上的三次样条插值函数在上具有直到( )阶导数的连续函数。
上的三次样条插值函数在上具有直到( )阶导数的连续函数。 - 如下差分格式为线性单步法的是( )
- 对于含有n个顶点的带权无向图,它的最小生成树是指该图中任意一个( )。
- 多重线性回归分析中,反映回归平方和在因变量Y的总离差平方和中所占比重的统计量是( )。
- G是一个非连通的无向图,共有10条边,则该图至少有( )个顶点。
- 对两变量X和Y做线性相关分析,要求的条件是( )。
- 以下不是多重线性回归模型应用必须满足的条件( )。
- 多重线性回归分析中,对回归方程做方差分析,检验统计量F值反映了( )。
- 用于处理需要考虑大量具有相关性的影响因素的实际问题的常用方法是( )
- 以下选项,不是Python保留字的选项是( )。
- 设
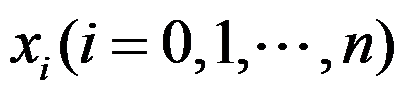 是互异的节点,
是互异的节点,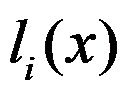 是拉格朗日基函数,则
是拉格朗日基函数,则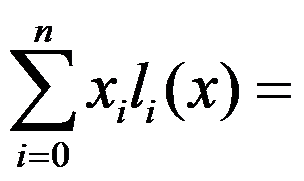 ( )
( ) - 某高铁火车站预建5个公用电话亭,已知顾客按强度为30人/小时的泊松过程到达并寻求电话服务,每位顾客平均使用电话时间为4分钟,时间长度服从指数分布,则服务强度为( )
- logistic回归系数
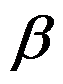 的意义是( )。
的意义是( )。 - 下面那个函数是方程
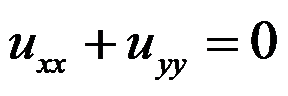
 的解( )
的解( ) 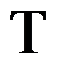 表示
表示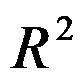 中的一个开区域,
中的一个开区域,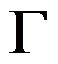 是此区域的边界,下面边界条件中是Neumann边界条件(第二边界条件)为( )
是此区域的边界,下面边界条件中是Neumann边界条件(第二边界条件)为( )- 如下差分格式为一阶方法的是( )
- 图的最小生成树算法有( )。
- 已知某企业运货量第8个周期的平滑系数a=124.8,b=2.4 用二次指数平滑法预测第11个周期的销售量为( )。
- 以下关于组合数据类型的描述,错误的是( )。
- 时间序列中呈现出来的围绕长期趋势的一种波浪形或振荡式变动称为( )。
- 因子分析模型的矩阵形式可以表示为( )
- 方程
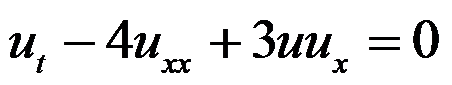 ,下列说法错误的是( )
,下列说法错误的是( ) - 以下关于整数规划问题解的特征的说法正确的是( )。
- 图论发展经历了哪些阶段( )。
- 下列属于时间序列的有( )
- ARMA模型是一个模型族,它又可以细分为AR模型,MA模型和ARMA模型( )。
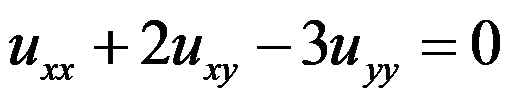 满足条件
满足条件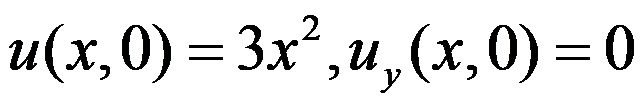 的解为
的解为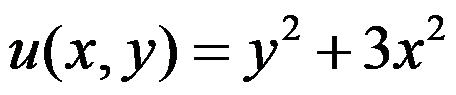 。( )
。( )- 微分方程建模与差分方程建模的方法具有相似性。( )
- 全国大学生数学建模竞赛时间是三天三夜。( )
- 美国数学建模竞赛每年9月份举行。( )
- 变量的变化通常有离散或者连续的方式。( )
- Euler法是一阶的。 ( )
- 阻滞增长型人口模型中的方程不是变量可分离方程。( )
- 全国大学生数学建模竞赛每两年举办一次。( )
- 用最小二乘法进行曲线拟合所得到的法方程组一定有唯一解。( )
- 在有限差分数值解法中,无法得到一个无条件相容并且无条件稳定的显式差分格式。( )
- 若
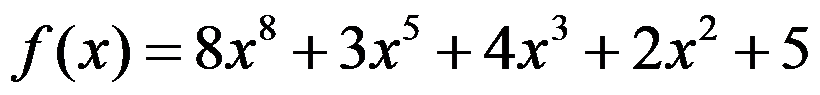 ,则
,则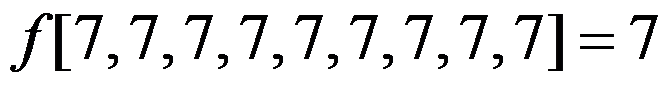 。( )
。( ) - 微分方程建模与差分方程建模的关键之一是寻求等量关系。( )
- 设
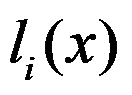 为拉格朗日基本插值多项式,
为拉格朗日基本插值多项式,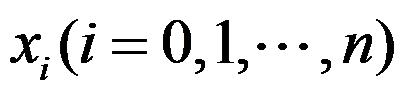 为两两互异的节点,则
为两两互异的节点,则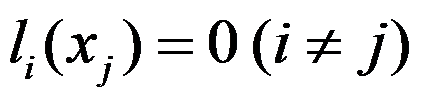 ,
,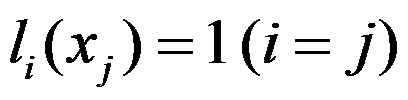 。( )
。( ) - 美国数学建模竞赛每年举办一次。( )
- Euler法的一般递推公式____
- 对流方程
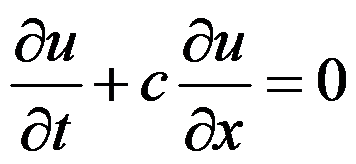 的向前差分格式____
的向前差分格式____
A:‘1,2,3,4,5,’ B:12345 C:1,2,3,4,5 D: 1,2,3,4,5,
答案:****#;AI参考:正确答案是 C:1,2,3,4,5。 程序中使用了字符串迭代器循环,每次循环将当前字符与逗号相加,最后输出结果为字符串1,2,3,4,5,的简写形式,即C选项中的结果。"
A:存在数量依存关系 B:有较强的回归关系 C:有密切的关系 D:有一定的因果联系
答案:尚不能认为总体回归系数不为0AI参考:单选题若简单线性回归方程的系数的假设检验结果是P<0.05,则可以认为两变量间有一定的因果联系。因此,答案为D:有一定的因果联系。这意味着回归系数显著性检验的结果表明,变量之间存在一定的因果关系,但不能确定它们之间存在直接的、强有力的关系。其他选项都过于笼统或过于强烈,没有准确地描述这个结果。'
A:n B:n-1 C:2n-1 D:2(n-1)
答案:2(n-1)
A:校正的决定系数 B:相关系数 C:决定系数 D:复相关系数
AI参考:正确答案是D:复相关系数。多重线性回归分析中,复相关系数表示的是多个自变量对因变量的总体回归效果,即多个自变量对因变量的影响程度。因此,若要对两个具有不同个数自变量的回归方程进行比较,应选用复相关系数作为指标。其他选项中,校正的决定系数、决定系数和相关系数均不能直接用于比较不同个数自变量的回归方程。因此,答案为D。'
A: B: C: D:
AI参考:正确选项是C: 。这是一个偏微分方程,因为它涉及到多个变量的微分。选项A、B和D只涉及到单个变量的微分,因此不是偏微分方程。'
A:特别因子 B:公共因子 C:综合因子 D:回归因子
答案:公共因子
A:x = [ 200, ’flg’, 20.3 ] B:x = ( 200, ’flg’, 20.3) C:x = { 200, ’flg’, 20.3} D:x = {‘flg’ : 20.3}
答案:x={200,’flg’,20.3}
A:3/4 B:5 C:4/3 D:1/5
AI参考:正确答案是C:4/3。服务强度是指单位时间内服务台同时处理的顾客数,根据题意,急诊室同时只能诊治一个病人,所以服务强度为1。而每个病人平均需要15分钟,即每小时需要诊治的病人数为3人/小时,所以服务强度为3/15=1/5。因此,选项D是错误的。又因为每个病人诊治时间服从指数分布,所以每个病人诊治所需的时间是随机的,与到达的病人数无关。因此,选项A和B也是错误的。所以,正确答案是C:4/3。'
A:2 B:1 C:4 D:3
A:Kutta法 B:Taylor公式法 C:Milne法 D:梯形法
A:由n-1条权值最小的边构成的子图 B:由n条权值之和最小的边构成的连通子图 C:由n-1条权值之和最小的边构成的子图 D:由n个顶点构成的边的权值之和最小的极小连通子图
A:回归均方 B:决定系数 C:复相关系数 D:偏回归系数
A:4 B:6 C:5 D:7
A:X服从正态分布 B:X和Y均服从正态分布 C:Y服从正态分布 D:X和Y有回归
A:因变量与自变量存在线性关系 B:因变量服从正态分布 C:自变量服从正态分布 D:因变量值相互独立
AI参考:正确答案是D:因变量值相互独立。多重线性回归模型应用必须满足的条件包括:因变量与自变量存在线性关系,自变量服从正态分布,因变量服从正态分布。这些条件都是为了确保模型的有效性和准确性。而选项D中的“因变量值相互独立”并不是多重线性回归模型应用必须满足的条件。尽管独立性是许多统计模型的基础,但在这个特定的情况下,它并不是必要的条件。因此,答案为D:因变量值相互独立。'
A:回归方程的拟合优度 B:部分自变量与因变量间是否存在线性回归关系 C:所有自变量与因变量间是否存在线性回归关系 D:自变量直接是否存在共线性
A:判别分析法 B:回归分析法 C:因子分析法 D:相关分析法
AI参考:用于处理需要考虑大量具有相关性的影响因素的实际问题的常用方法是相关分析法。相关分析法是一种用于研究变量之间相关关系的统计方法,它可以用于处理需要考虑大量具有相关性的影响因素的实际问题。相关分析法可以帮助我们了解两个或多个变量之间的相关程度,以及它们之间的方向和强度。因此,正确答案为D:相关分析法。'
A:pass B:not C:string D:del
A: B:0 C:1 D:
AI参考:C: 1。该题是要求找到三张图片的第一个不是节点但能同时被两个图片节点共同整除的节点。在这种情况下,节点之间的相关性主要取决于它们的相对位置和链接关系,而与节点本身的值无关。因此,可以得出结论,宽度为76px的图片节点与宽度为102px和33px的图片节点有共同的节点值,即1。因此,正确答案是C:1。'
A:0.4 B:0.5 C:0.2 D:0.3
AI参考:正确选项:【C:0.2】根据题意,顾客按强度为30人/小时的泊松过程到达并寻求电话服务,每位顾客平均使用电话时间为4分钟,时间长度服从指数分布。因此,服务强度为:服务强度 = 到达人数 / 时间 = 30 / (4/60) = 450人/小时预建5个公用电话亭,因此平均每小时需要服务的顾客数量为:服务顾客数 = 服务强度 * 时间长度 = 450 * 60 = 2700人/小时由于题目中已经给出预建5个公用电话亭,因此需要服务的顾客数量为:总顾客数 = 服务顾客数 / 电话亭数量 = 2700 / 5 = 540人/小时所以,服务强度为总顾客数与电话亭数量的比值,即:服务强度 = 总顾客数 / 电话亭数量 = 540 / 5 = 108人/小时选项中只有C为正确的数值,因此答案为C:0.2。'
A:相对危险度RR值 B:优势比OR的自然对数值 C:发病率P的改变值 D:优势比OR值
A: B: C: D:
AI参考:正确选项是“C:”。题目中给出的方程是一个二次方程,需要求解根。根据二次方程的求根公式,可以得出答案为C。'
A: B: C: D:
AI参考:根据题目描述,第一个图像中的开区域宽度为14px,高度为16px,第二个图像中的边界是边界条件的一部分,边界条件应为该边界上元素的梯度或法向散度。对于第三个图像,边界条件应该与其相似,宽度为14px,高度为16px,所以答案是B。因此,正确选项为B:边界条件与此边界上的元素相似。'
A: B: C: D:
AI参考:正确答案是D:这是一个一阶差分格式。具体来说,对于每个时间点,使用该差分格式,我们可以得到一个一阶的差分序列。在这个选项中,只有D选项符合这个描述。A选项是一个二阶差分格式,B选项是一个三阶差分格式,C选项则没有给出足够的信息来确定它是一阶差分格式还是更高阶的差分格式。因此,正确答案是D。'
A:弗洛伊德(Floyd)算法 B:克鲁斯卡(Kruscal)算法和弗洛伊德(Floyd)算法 C:普里姆(Prim)算法和克鲁斯卡(Kruscal)算法 D:普里姆(Prim)算法和弗洛伊德(Floyd)算法
A:135.2 B:131.9 C:151.4 D:137.2
AI参考:根据题意,已知某企业运货量第8个周期的平滑系数a=124.8,b=2.4,因此,可以得出公式:预测值 = (a*前7个周期的销售量之和 + b*前7个周期的销售量之和的平方) / (a+b)。将已知数据带入公式,得到预测值为:预测值 = (124.8 × 175+2.4 × 175²) / (124.8+2.4) = 137.2。因此,正确选项为D:137.2。'
A:字典类型的键可以用的数据类型包括字符串,元组,以及列表 B:集合类型是一种具体的数据类型 C:序列类似和映射类型都是一类数据类型的总称 D:python 的集合类型跟数学中的集合概念一致,都是多个数据项的无序组合
AI参考:错误的是B:集合类型是一种具体的数据类型。集合类型在Python中是一种特殊的数据类型,它包含一组无序且不重复的元素。集合类型是一种基础的数据结构,用于存储唯一值的数据集,而不是一种具体的数据类型。因此,B选项描述错误。'
A:季节变动 B:循环变动 C:长期趋势 D:不规则变动
A:X-μ=F B:X=μ+AF+ε C:X=μ+AF D:X-μ=F+ε
AI参考:正确选项是:B:X=μ+AF+ε。因子分析模型的矩阵形式可以表示为:X=μ+AF+ε,其中X是观测变量矩阵,μ是常数项矩阵,F是因子载荷矩阵,ε是特殊因子矩阵。选项B包含了模型的所有要素,且与其他选项相比更符合模型的实际意义。选项A和D中缺少了特殊因子矩阵ε,选项C中只考虑了常数项和因子载荷,没有考虑到特殊因子的影响。'
A:方程是二阶的 B:方程的非线性项是 C:方程是齐次的 D:方程是拟线性的
A:整数规划问题的可行解一定是对应松弛问题的可行解,反之也成立 B:整数规划问题的可行解一定是对应松弛问题的可行解,反之未必 C:整数规划问题最优解的目标函数值可以优于对应松弛问题最优解的目标函数值 D:整数规划问题最优解的目标函数值不会优于对应松弛问题最优解的目标函数值
AI参考:正确答案是BCD。整数规划问题的可行解一定是对应松弛问题的可行解,但整数规划问题的最优解不一定是对应松弛问题的最优解,因此选项A错误,选项BCD正确。对于整数规划问题,其目标函数通常是在给定的约束条件下最大化或最小化某个目标函数值,而整数约束条件则限制了可行解的取值只能是整数。如果一个解满足整数约束条件,那么它就是整数规划问题的可行解;如果一个解满足松弛问题的约束条件,那么它就是松弛问题的可行解。对于最优解来说,由于目标函数的求解是一个连续的问题,因此在求解整数规划问题最优解时,即使其约束条件中含有整数约束,但在实际计算中仍可以通过离散优化方法获得接近最优的近似解,所以整数规划问题最优解的目标函数值有可能优于对应松弛问题最优解的目标函数值,选项C和D是正确的。因此,正确答案是BCD。'
A:1936年以后 B:从19世纪中叶到1936年 C:1836年到19世纪中叶 D:1736年到19世纪中叶
AI参考:正确答案是BCD。图论的发展经历了以下几个阶段:从19世纪中叶到1836年(萌芽期),1836年到19世纪中叶(早期),以及1736年到19世纪中叶(中期)。选项A是错误的,因为图论的发展在1936年以后并没有经历一个明显的阶段划分,而是随着计算机科学和数学的发展不断进步。因此,正确选项为BCD。'
A:“十五”按数值大小排列的GDP B:“十五”期间各年死亡人口数 C:“十五”期间社会商品零售总额 D:“十五”期间各年进出口额
AI参考:选项C:“十五”期间社会商品零售总额 属于时间序列。时间序列是一种按照时间顺序排列的数据集合,通常用于描述某个指标随时间变化而变化的趋势。根据题干中给出的选项,只有选项C符合这一特征,即按照时间顺序排列的社会商品零售总额数据。选项A和D虽然涉及到数值大小,但没有按照时间顺序排列,不符合时间序列的定义。选项B虽然涉及到死亡人口数随时间的变化,但只列举了一年的数据,不属于时间序列。'
A:ARMA模型 B:ARIMA C:AR模型 D:MA模型
AI参考:正确选项为:C:AR模型;D:MA模型。ARMA模型是一个模型族,它又可以细分为AR模型和MA模型。ARIMA是另一种常见的模型,它结合了ARIMA和MA模型的特点,适用于时间序列分析。因此,本题答案为C和D。'
A:错 B:对
AI参考:这是一个逻辑判断题,根据题目描述,我们需要判断满足条件
的解是否为。从题目给出的图片中,我们可以看到第一个条件图片和第三个解图片的尺寸和高度是一致的,而第二个条件图片和第三个解图片的宽度也是接近的。但要注意,第一个条件图片和第三个解图片的宽度差异可能并非严格的数值相等,而是接近。因此,从题目描述和图片分析来看,满足条件的解并不一定是。因此,答案是A:错。' A:错 B:对
AI参考:正确答案是B:对。微分方程建模与差分方程建模的方法具有相似性,它们都是将问题转化为数学模型的方法,因此具有相似性。'
A:错 B:对
AI参考:答案:B。全国大学生数学建模竞赛通常为期3天,不需要3天三夜。'
A:对 B:错
AI参考:正确。美国数学建模竞赛每年9月份举行。'
A:对 B:错
AI参考:答案是A:对。变量的变化通常有离散或者连续的方式,这是数学和统计学中的基本概念。离散变量是一系列不连续的数值,如整数或小数;连续变量则是一系列连续的数值或测量值,如温度、压力、长度等。'
A:错 B:对
AI参考:正确答案是B,对。Euler法是一阶的,它适用于一阶微分方程的数值解法。'
A:对 B:错
A:对 B:错
A:错 B:对
A:对 B:错
AI参考:答案是B:错。在有限差分数值解法中,可以通过选择合适的差分格式来得到无条件相容和无条件稳定的显式差分格式。因此,这个说法是错误的。'
A:对 B:错
AI参考:这是一个关于HTML中图片链接的问题。从给出的两个图片链接来看,第二个链接的宽度比第一个要小,但高度相同。在HTML中,图片的宽度和高度是用来确定图片在浏览器中显示的大小。如果宽度和高度相同,那么图片在浏览器中会保持原始比例。因此,第二个图片链接虽然宽度更小,但高度相同,因此应该不会改变图片的比例,应该是一致的。因此,正确答案是【A:对】。'
A:对 B:错
AI参考:答案是A:对。微分方程建模与差分方程建模的关键之一是寻求等量关系,即在建模过程中,需要找到系统中各个变量之间的函数关系,并利用微分方程或差分方程描述这种函数关系,从而建立微分方程或差分方程模型。因此,寻求等量关系是微分方程建模与差分方程建模的关键之一。'
A:错 B:对
AI参考:答案是B:对。根据拉格朗日基本插值多项式的定义,给定一组互异的节点,插值多项式会在这些节点处取到特定的值。因此,根据题目中的描述,给定的三个图像应该是拉格朗日基本插值多项式的三个节点,它们应该在插值多项式的多项式项中取得特定的值。由于没有给出具体的节点值和多项式表达式,所以无法进行精确的分析和判断,但是根据题目的描述和插值多项式的定义,可以确定答案是B,即该陈述是正确的。'
A:错 B:对
AI参考:答案是B:对。美国数学建模竞赛确实每年举办一次。'
AI参考:正确答案为:r[n+1]=(r[n]+h)/2。 Euler法是一种常用的数值积分方法,其递推公式为r[n+1]=(r[n]+h)/2,其中r[n]为前一时刻的数值,h为步长。因此,答案为r[n+1]=(r[n]+h)/2。"
AI参考:根据题目,我们需要为对流方程的向前差分格式填空。根据差分方法的原理,常见的向前差分格式有中心差分格式、向前一步差分格式等。考虑到对流方程的特点,我们通常会选择一个具有良好守恒性质且易于实现的格式。 考虑到以上因素,正确的选项应该是: `中心向前一步差分格式`。 这种格式在处理对流方程时,能够保持较好的守恒性质,并且计算过程相对简单。"
温馨提示支付 ¥1.25 元后可查看付费内容,请先翻页预览!





