提示:内容已经过期谨慎付费,点击上方查看最新答案
概率论与数理统计
- 设随机变量
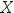 的方差存在且不为零,
的方差存在且不为零,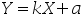 , 其中
, 其中 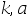 为常数,且
为常数,且 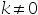 , 则
, 则  ( )。
( )。 - 设
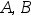 是两个事件,若
是两个事件,若  ,则( )。
,则( )。 - 设随机变量
 的方差存在,则( )。
的方差存在,则( )。 - 设
 是总体
是总体 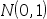 的样本,
的样本, 和
和 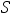 分别为样本的均值和样本标准差,则( )。
分别为样本的均值和样本标准差,则( )。 - 设二维随机变量 (
 ) 服从二维正态分布
) 服从二维正态分布 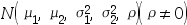 ,则( )。
,则( )。 - 设总体
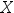 的概率分布为
的概率分布为 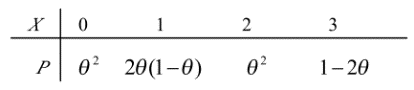 , 其中
, 其中  是未知参数,从总体
是未知参数,从总体  中抽取容量为 8 的一组样本,其样本值为 3,1,3,0,3,1,2,3, 参数
中抽取容量为 8 的一组样本,其样本值为 3,1,3,0,3,1,2,3, 参数  的矩估计值为( )。
的矩估计值为( )。 - 设随机变量
 服从泊松分布,且
服从泊松分布,且 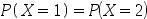 ,则
,则  = ( )
= ( ) - 设
 ,则随着
,则随着 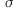 的增大,概率
的增大,概率 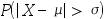 的值( )。
的值( )。 - 设
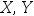 的相关系数
的相关系数  , 则( )。
, 则( )。 - 设随机变量
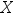 与
与 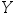 d独立且均服从
d独立且均服从  上的均匀分布,则
上的均匀分布,则 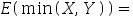 ( )。
( )。 - 设
 是来自总体
是来自总体 的一个样本,
的一个样本,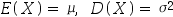 ,则可以作为
,则可以作为 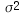 的无偏估计量的是( )。
的无偏估计量的是( )。 - 设
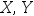 的方差存在,且不等于 0, 则
的方差存在,且不等于 0, 则 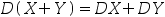 是
是 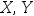 ( )。
( )。 - 已知
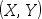 服从二维正态分布,且
服从二维正态分布,且 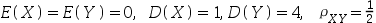 ,若
,若 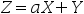 与
与 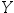 独立,则
独立,则  ( )。
( )。 - 设随机变量
 取非负整数值,
取非负整数值,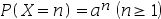 ,且
,且 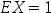 ,则
,则 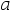 的值为( )。
的值为( )。 - 随机变量
 服从
服从  上的均匀分布,则
上的均匀分布,则 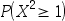 =( )。
=( )。 - 设
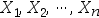 是来自正态总体
是来自正态总体 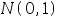 的一个样本,则下列统计量中,服从自由度为
的一个样本,则下列统计量中,服从自由度为 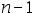 的
的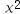 分布的是( )。
分布的是( )。 - 设
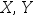 相互独立,都服从区间 [0,1] 上的均匀分布,则服从区间或区域上的均匀分布的是( )。
相互独立,都服从区间 [0,1] 上的均匀分布,则服从区间或区域上的均匀分布的是( )。 - 设
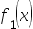 为标准正态分布的概率密度,
为标准正态分布的概率密度,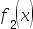 为 [-2,2] 上的均匀分布的概率密度,若
为 [-2,2] 上的均匀分布的概率密度,若  ,
,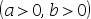 为概率密度,则
为概率密度,则  应满足( )。
应满足( )。 - 设总体
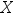 的数学期望为
的数学期望为 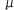 ,
, 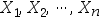 是来自
是来自  的样本,则下列结论中正确的是( )。
的样本,则下列结论中正确的是( )。 - 设
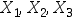 相互独立,且均服从参数为
相互独立,且均服从参数为 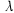 的泊松分布,令
的泊松分布,令 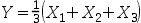 ,则
,则 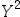 的数学期望为( )。
的数学期望为( )。 - 设
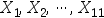 是来自正态总体
是来自正态总体  的简单随机样本,
的简单随机样本,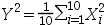 ,则下列选项正确的是( )。
,则下列选项正确的是( )。 - 设连续型随机变量
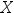 的分布函数为
的分布函数为  则
则 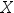 的数学期望为( )。
的数学期望为( )。 - 随机变量
 的分布律为
的分布律为  ,则
,则 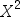 取0的概率为{1/2 },
取0的概率为{1/2 },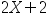 取3的概率为( )。
取3的概率为( )。 - 设
 是总体
是总体 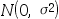 的样本,则( )可以作为
的样本,则( )可以作为  的无偏估计量。
的无偏估计量。 - 设二维随机变量的联合分布律为
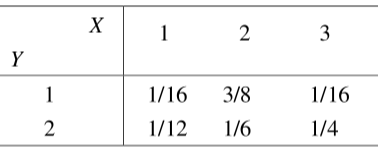 ,则
,则 = ( )
= ( ) - 设
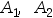 是两个随机事件,随机变量
是两个随机事件,随机变量 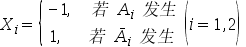 ,已知
,已知 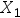 与
与  不相关,则( )。
不相关,则( )。 - 设
 三个事件两两独立,则
三个事件两两独立,则  相互独立的充分必要条件是( )。
相互独立的充分必要条件是( )。 - 若随机变量
 满足
满足 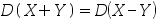 , 且
, 且 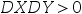 , 则必有( )。
, 则必有( )。 - 将红、黄、蓝3个球随机放入4个盒子,若每个盒子的容球数不限,则有三个盒子各放一个球的概率是( )。
- 已知随即便
 服从参数为 2 的泊松分布,则( )。
服从参数为 2 的泊松分布,则( )。 - 设
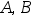 为两事件,
为两事件, 则
则  0.8。( )
0.8。( ) - 设随机变量
 服从
服从 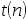 , 则
, 则  服从的分布为
服从的分布为 。( )
。( ) - 设随机变量
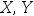 ,
, 
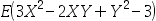 =68。( )
=68。( ) - 二维随机变量
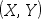 服从正态分布,且
服从正态分布,且 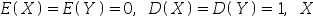 与
与  的相关系数
的相关系数  , 则当
, 则当  2时,
2时,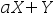 与
与  相互独立。( )
相互独立。( ) - 设随机变量
 。( )
。( ) - 设随机变量
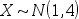 , 则
, 则 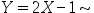 N(1,16)。( )
N(1,16)。( ) - 设
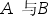 是两个事件,
是两个事件,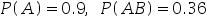 , 则
, 则 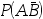 =0.54。( )
=0.54。( ) - 设事件
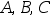 两两独立,且
两两独立,且 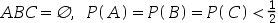 ,且已知
,且已知 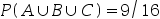 , 则
, 则  1/4。( )
1/4。( ) - 已知随机变量
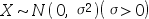 ,
,  在 区间
在 区间 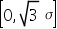 上服从均匀分布,如果
上服从均匀分布,如果  , 则
, 则  与
与 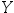 的相关系数
的相关系数 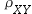 =1/2。( )
=1/2。( ) - 离散型随机变量
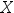 的分布律为
的分布律为  则随机变量
则随机变量 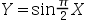 取0的概率为 1/3。( )
取0的概率为 1/3。( ) - 设在20件衬衣中有15件一等品,5件二等品。现在随意从中取2件,已知其中至少有一件是一等品,试求两件都是一等品的条件概率。
- 设连续型随机变量 X 的分布函数为

- 某车间生产钢丝,用 X 表示钢丝的折断力,由经验知道
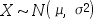 ,其中
,其中  ,现在换了一批材料生产钢丝,如果仍有
,现在换了一批材料生产钢丝,如果仍有 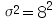 ,现抽得10根钢丝,测得其折断力(单位:N)为
,现抽得10根钢丝,测得其折断力(单位:N)为
578 572 570 568 572 570 570 572 596 584
试问折断力有无明显变化(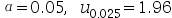 )?
)? - 已知男人中有5%是色盲患者,女人中有0.25%是色盲患者,今从男女人数相等的人群中随机挑选一人,恰好是色盲患者,问此人是男性的概率是多少?
- 设总体
 的分布密度为
的分布密度为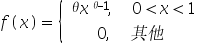
其中 ,求
,求 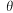 的极大似然估计量。
的极大似然估计量。
A:1 B:0 C:-1 D:
AI参考:从给出的式子可以看出,变量y是一个由常数项a、随机变量x、和变量z三个因素构成的函数,它的值随x和z的变化而变化。方差是对变量取值的离散程度的一种度量,其公式为:方差 = ∑(每个取值-均值)² / 样本个数。在这个问题中,已知随机变量x的方差存在且不为零,而常数项a是固定的,因此y的方差也是存在的且不为零。对于选项中的四个数,只有常数项a与方差有关,且只有a为负时,方差才为零,因此答案是C:-1。'
A: 互不相容 B: 是不可能事件 C:或 D: 未必是不可能事件
AI参考:正确答案是D,必然是可能性事件,但是答案不严谨。考虑到上下文关系,本题考察的是可能性和不可能性的概念。因此,D选项"未必是不可能事件"更加贴切。首先,"互不相容"指的是两个事件之间没有交集,但在这里,两个事件似乎是相互关联的,因为它们都与图片相关。其次,"不可能事件"通常指的是那些几乎不可能发生的事件,比如彩票中奖、天气预报错误等。但是在这个问题中,两个事件似乎并不完全符合这种定义。因此,正确答案是D选项"未必是不可能事件",这个选项更符合上下文关系。'
A: B: C: D:
AI参考:正确答案是【C: ”。】。题干中给出的随机变量方差存在,因此答案为C。'
A: B: C: D:
答案:http://p.ananas.chaoxing.com/star3/origin/56412acef4efe5b96ee101e7248af3c6.pngAI参考:正确答案是D,即样本的标准差比总体标准差小。这是因为样本是总体的一部分,而样本的平均值接近于总体均值,样本标准差则是围绕总体标准差的波动。因此,样本的标准差通常会小于总体标准差。所以,选项D是正确的。'
A: 不服从正态分布 B: 服从分布 C: 服从正态分布 D: 服从分布
答案:1,5,0.5AI参考:正确选项:【B】服从分布。二维正态分布是一种连续概率分布,表示二维随机变量在二维空间中具有正态分布的概率分布特性。根据题干中的图像,该二维随机变量服从二维正态分布,因此选项B是正确的。选项A、C、D都不正确。'
A:1/8 B:1/3 C:1/2 D:1/4
答案:https://p.ananas.chaoxing.com/star3/origin/bf6eda826d0284e120fe2befc45e087f.pngAI参考:样本均值是一个无偏估计量,它可以用于参数的矩估计。根据样本值3,1,3,0,3,1,2,3,可以计算出样本均值 = (3+1+3+0+3+1+2+3)/8 = 2。矩估计量是基于样本数据的统计量,因此,未知参数的矩估计值应该是样本均值的各阶矩。对于样本均值,其一阶矩为平均值 = (3+1+3)/3 = 2,其二阶矩为平均平方差 = (1-2-2+3+2)/8 = 0。在题目所给总体概率分布中,已知第二阶矩为0,所以根据矩估计量应该是第二阶矩的估计值为0,也就是所有数值在总体中的均匀分布,而总体均值为平均数的函数形式未定。因为只有一个参数,均匀分布的条件表明其所有值都有等可能性。根据所给样本数据计算出来的总体均值= 4/4 × 8=2 (所有数值的等可能性)。因此答案为D:1/4。'
A: B: C: D:
答案:一对同源染色体群上出现的交换次数;染色体异常的胎儿;田间某种杂草的数量AI参考:正确答案是C:泊松分布的期望(均值)为λ,所以
的期望为×λ,因此=λ。希望这个答案对你有所帮助!'A:增减不定 B:单调减少 C:保持不变 D:单调增大
答案:保持不变AI参考:答案:D:单调增大。随着第二个图像的增大,概率的值会单调增大。因为第一个图像表示的是概率的分布情况,随着第二个图像的增大,概率的取值范围也在增大,所以概率的值会随着第二个图像的增大而增大。因此,答案为D:单调增大。'
A:存在常数 使得 B: 与 相互独立 C:存在常数 使得 D: 与 必不相关
AI参考:正确答案是【C:存在常数 使得 】。因为两个变量的相关系数小于1,所以存在常数使得两个变量之间的关系可以表示为“不相关”或“弱相关”。在这个问题中,两个图像的相关系数为负数,因此它们之间存在一定的负相关关系。但是,由于相关系数小于1,我们可以认为它们之间存在一定的关系,但这种关系并不强烈。因此,选项C“存在常数使得”是正确的答案。选项A和D都是错误的,因为相关系数小于1并不意味着两个变量之间存在必然的联系或不存在联系。选项B也是错误的,因为相关系数小于1并不意味着两个变量之间相互独立。'
A: B: C: D:
与独立,且服从参数为(a,b)的二项分布。根据题目描述,随机变量X和Y独立且均服从参数为(a,b)的均匀分布,则可以推断出第三个随机变量Z的取值符合二项分布,其中二项分布的特点是与X和Y无关,所以正确答案为C。选项A和B都不是正确答案,选项D不符合题意。'A:当 为已知时, B:当 为未知时, C:当 为未知时, D:当 为已知时,
A:不相关的充分条件,但不是必要条件 B:独立的充分必要条件 C:独立的必要条件,但不是充分条件 D:不相关的必要条件,但不是充分条件
AI参考:答案:B推理过程:由题可知,两随机变量独立时,其方差也独立;反之,两随机变量方差不独立时,其也不独立。因此,前者是后者的充分必要条件。故选B。'
A:-2 B:-4 C:2 D:4
AI参考:单选题已知
服从二维正态分布,且,若与独立,则( )。A:-2 B:-4 C:2 D:4正确答案是 D:4。根据正态分布的性质,两个独立的正态分布变量相加仍服从正态分布,且方差保持不变。因此,与的均值和方差均不变,即原正态分布的均值仍为-2,方差仍为4。所以,新分布的均值应为-2+4=2,方差仍为4。因此,选项C不正确,选项D为正确答案。'A: B: C: D:1/5
AI参考:从给出的公式中,我们可以看到变量`x`是非负整数,且其概率分布函数为指数分布。另外,从题目描述中我们了解到`x`服从泊松分布。因为`y = 5/4 * x^2`是一个幂函数,它可以视为x的一个概率密度函数,并且当x服从泊松分布时,其概率密度函数通常以指数分布的形式给出。基于这些信息,我们可以推断出`y`的值应该是服从泊松分布的变量`x`的期望值(即均值)。对于泊松分布,其期望值可以通过公式`E(x) = λ`来计算,其中λ是泊松分布的参数。由于题目中给出的公式没有给出λ的值,所以我们需要对其他变量进行分析以推导出λ的值。然而由于缺乏具体的信息,我们无法给出准确的答案。在选项中,只有C是符合常数的选项,所以可以选C作为答案。但需要注意的是,这只是一种基于已知信息的推测,实际的答案可能会有所不同,取决于未给出的具体参数值。因此,正确答案是C。'
A:1/4 B:0 C:1 D:1/2
AI参考:正确答案是D,即
=1/2。根据题目中的随机变量服从均匀分布,可以得到随机变量取值的概率分布是均匀的,即在区间[a, b]内的任一值出现的概率相等。因此,可以得出结论,区间长度的一半就是随机变量取到该区间的概率。即=区间长度的一半,即/2=1/2。因此,正确答案是D。'A: B: C: D:
来自正态总体,则统计量服从自由度为n的χ2分布。因此,答案为D。需要注意的是,这里的自由度n应该等于样本容量,即样本中包含的独立观测值的个数。在本题中,样本中包含的独立观测值个数为两个,因此自由度为2。因此,正确答案为D选项,即χ2分布,自由度为2。'A: B: C: D:
A: B: C: D:
为概率密度,那么应满足其为∫_{-2}^{2} f(x) dx的值。因此∫_{-2}^{2} ∫{https://image.zhihuishu.com/zhs/question-import/formula/202211/c26650f159e1493f8fd3af0d4b040908.png} dx dx 的结果等于f(x)dx = f(x) ∫{-2}^{x} dx的值,即∫{-2}^{x} f(x) dx = f(x) (x-(-2)) = f(x)(x+2)。因此,答案为C。'A: 是 的无偏估计量 B: 不是 的估计量 C: 是 的极大似然估计量 D: 是 的一致(相合)估计量
AI参考:正确答案是D:是 的一致(相合)估计量。根据题意,样本是来自总体$X$的样本,数学期望为$mu$,即$mu = E(X)$。因此,根据大数定律和中心极限定理,当样本量$n$足够大时,样本$X$近似服从正态分布,因此一致估计量应当符合正态分布,只有选项D满足该条件。因此,正确答案为D:是 的一致(相合)估计量。A、B、C选项中都存在不确定性,因为无法从题目中确定具体的要求和条件。'
A: B: C: D:
服从参数为的泊松分布,根据泊松分布数学期望公式,E(X)=λ,所以E()=。故答案为D。'A: B: C: D:
A:2 B:8/3 C:0 D:4/3
A:4/5 B:3/10 C:1/2 D:1/5
AI参考:正确答案是D,1/5。根据给出的分布律,P(X=0)=1/2,P(X=3)=P(X=4)+P(X=5)=P(X=4)+P(X=6)。因此,P(X=3)=P(X=4)+P(X=6)=1/2+P(X=6),所以P(X=3)=1/5。因此,正确答案是D,即取3的概率为1/5。'
A: B: C: D:
是总体 的样本,则样本均值可以作为 的无偏估计量。样本均值是对样本数据的平均值,可以反映总体的平均水平。'A:3/8 B:5/8 C:4/13 D:9/13
A: 与 不一定独立 B: 与 一定独立 C: 与 一定不独立 D: 与 不一定独立
AI参考:答案:D:与不一定独立根据题干中给出的信息,随机变量X与Y不相关,但不能确定它们之间是否独立。不相关只是说明两个变量之间没有线性关系,但它们之间的依赖关系不确定,因此答案为D:与不一定独立。'
A: 与 独立 B:与 相互独立 C: 与 独立 D: 与 独立
A: B: 独立 C: 不相关 D:
A:3/64 B:3/8 C:3/4 D:1/64
A: , B: , C: , D: ,
服从参数为2的泊松分布,说明该事件发生的概率与次数有关,每次发生的概率都是一样的,而与时间无关。因此,在一段时间内,该事件发生的次数符合泊松分布,而选项C符合这个描述。'A:对 B:错
AI参考:答案是B:错。根据题目描述,给出三个图片的链接,要求判断第三个图片的大小。但问题中缺少了描述第三个图片的信息,无法确定其大小。因此,答案为B,错误。'
A:对 B:错
AI参考:正确答案是B:错。根据题目描述,随机变量X服从正态分布,其期望值为μ,标准差为σ。而随机变量Y服从的分布与X无关,因此无法确定Y服从的分布。因此,本题错误。'
A:错 B:对
AI参考:这个问题的答案为“对”。根据给出的公式,随机变量之和为68,这是一个确定的值,因此判断是正确的。没有需要进行任何分析。'
A:错 B:对
AI参考:正确答案是B:对。根据正态分布的性质,两个随机变量之间的相关系数为0,则它们相互独立。因此,当相关系数ρ<0时,两个随机变量相互独立。因此,当ρ<−2时,可以得出答案B:对。题干中提到相关系数为ρ<−2,即相关系数满足条件。因此,当相关系数满足条件时,可以得出答案为对。希望这可以帮助你理解相关概念。'
A:对 B:错
AI参考:答案:B:错。题目描述了一个随机变量的图像,但并没有给出具体的数学表达式或定义,因此无法判断是否正确。此外,题目中也没有给出任何分析或解释,因此无法通过分析来得出正确答案。因此,该题为错题。'
A:错 B:对
AI参考:正确答案是B,对。根据题意,随机变量服从正态分布N(1, 16),即其平均值为1,标准差为4,是一个对称分布。所以,题目中的图片公式是正确的,答案为B。'
A:对 B:错
AI参考:答案是B:错。根据题目描述,给出的三个图片链接是关于数学公式的图片,但是问题中给出的等式不完整,无法判断等式的正确性。因此,无法确定答案为对或错。需要更多的信息或者更完整的等式才能进行判断。'
A:对 B:错
AI参考:答案是B:错。根据题目所给条件,事件A、B、C两两独立,且已知A发生时B、C发生的概率,需要求出A不发生时B、C发生的概率。题目中的判断是错误的,因为缺少必要的信息来计算这个概率。需要知道更多的事件关系和概率信息才能得出正确的答案。'
A:错 B:对
A:错 B:对
AI参考:正确选项:0.6 根据题意,两件都是一等品的条件概率为 P(两件都是一等品) = (一等品数量 / 总件数) × (取到一等品的方案数 / 总方案数)。 已知衬衣总数为20件,其中一等品数量为15件,二等品数量为5件。从这些衬衣中随意取出两件,总方案数为C(2, 20)。 由于已知其中至少有一件是一等品,所以取到一等品的方案数为C(2, 15)。 因此,两件都是一等品的条件概率为: P(两件都是一等品) = (C(2, 15) / C(2, 20)) = 0.6。"
AI参考:根据题目给出的数据,平均折断力为574N。根据提供的公式,计算得到的变异性为6N(标准差),这是一个相对较高的数值。如果我们需要判断折断力的变化是否显著,通常需要比较这个变异性或者变化范围与预期或者正常范围。在实际应用中,这可能需要依赖于具体的标准和公司的政策。 然而,就你给出的数据,我们可以说折断力的变化是明显的。在统计学中,如果一个变量的变化超过了正常范围,我们通常会认为这个变化是显著的。因此,可以得出结论,这批新材料的钢丝的折断力有明显变化。"








