提示:内容已经过期谨慎付费,点击上方查看最新答案
人工智能案例实战
- 以下程序的输出结果是:
ab = 4
def myab(ab, xy):
ab= pow(ab,xy)
print(ab,end=" ")
myab(ab,2)
print( ab)( ) 创建一个值为[10,49]的数组的语句为( )。
以下程序的输出结果是()。
x = 3
while x<6:
if x==4:
break
if x%2==0:
continue
x += 1
print(x)- 以下说法中错误的是( )。
- 以下程序的输出结果是。
img1 = [['北京',98],['上海',80]]
img1[1] = 90
print(img1)( ) 以下程序的输出结果是()。
a=[“牡丹”,”芍药”,”玫瑰”,”月季”]
del a[1:3]
print(a)- Python3中,使用input()函数可以获取用户从键盘上输入的数据,不管用户输入的内容是什么,该数据的默认数据类型为( )。
- 给出如下代码:
def func(a,b):
c=a**2+b
b=a
return c
a=10
b=100
c=func(a,b)+a
以下选项中错误的是( ) - 下面安装包的命令中,错误的是:( )。
- 下面代码实现的功能是
def fact(n):
if n==0:
return 1
else:
return n*fact(n-1)
num =eval(input("请输入一个整数:"))
print(fact(abs(int(num))))( ) - 以下程序的输出结果是。
a=[“book”,”reader”,200]
a.append( 100 )
a.append( [10,20] )
print(a)( ) - 执行下面程序段,对运行结果描述正确的是 。
a = tf.constant(1234567, dtype=tf.float32)
tf.cast(a, tf.float64)( ) - 下列( )方法可以实现两个张量逐元素相乘。
- 如果依次输入3, 10, 5.3, 4, -2,请问以下程序的输出结果是。
number = eval(input())
max = number
while number>0:
number = eval(input())
if number > max:
max = number
print(max)( ) - 执行下列程序段,输入数值8,输出的结果是。
x=input()
y=x*3
print(y)( ) - 以下关于字典的描述,错误的是( )。
以下程序的输出结果是()。
sum=0.0
for num in range(1,11):
sum+=numprint(sum)
- 以下不能创建一个字典的语句是( )。
以下程序的输出结果是()。
a=[“李白”,“孟浩然”,”杜甫”,“王昌龄”]
print(a[1:3])- 以下( )是python的单行注释表示。
程序输出的结果是 ()。
for i in range(4):
for j in range(i,3):
if (i+j)%2==0:
print(i,j)
break
Python语言提供的3个基本数字类型是( )。
- 下列程序的执行结果为。
import tensorflow as tf
a = tf.constant([1, 3, 5])
b = 2
c = tf.reduce_sum(a+b)
c.numpy()( ) - 关于return语句,以下描述正确的是:( )
以下程序的输出结果是 ()。
def f (x, y = 0, z = 0):
pass
f (1, ,3)
- Python不支持的数据类型有( )
- 下面程序段的输出结果是。
for s in "祖国,你好!":
if s==",":
continue
print(s,end="")( ) 执行下面代码,得到的正确结果是。
a=[ 2,4,1,5,3 ]
a.reverse(True)
print(a)( )以下语句中b的shape为。
import numpy as np
a=np.array( [[1,2.3],[3,5]] )
b=tf.constant(a)( )- 字典d={'A':1, 'B':2, 'C':3},len(d)的结果是( )。
- 在以下四个散点图中,适用于作线性回归的散点图为。
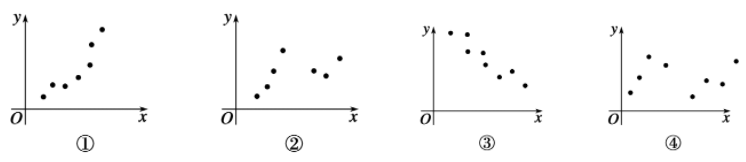 (B)
(B)
A.①②
B.①③
C.②③
D.③④
[选择题] [难度1]
104.下列变量中,属于负相关的是( )。 - 元组变量t=("cat", "dog", "tiger", "human"),t[::–1]的结果是( )。
- 执行下面代码,以下说法正确的是 。
x=['bob','tom','kitty']
y=[80,90,95]
d=dict(zip(x,y))( ) - 以下选项中不是python保留字的选项是( )。
- 给定字典d,以下选项中对d.items()的描述正确的是( ) 。
- 下列( )函数可以用来创建元素符合均匀分布的张量。
以下程序的输出结果是()。
a=[100,200,300]
a.insert(1,2)
print(a)- 阅读下面代码,选择正确的输出结果。
grade = 90
if grade >= 60:
print( 'D')
elif grade >= 70:
print( 'C')
elif grade >= 80:
print( 'B')
elif grade >= 90:
print( 'A')( ) - 下面的Anaconda工具中,( )不能直接用来编辑和运行源代码。
- 在sum初始值为0的情况下,以下语句不能完成1~10的累加求和的是( )。
- 回归问题和分类问题都属于有监督学习。( )
- 使用三引号创建字符串时不允许使用转义符。( )
- 学习率设置大一些可以提高模型的收敛速度,效果更好。( )
tf_version_可用来查看当前Tensorflow的版本号。
- TensorFlow2.0中,只提供了以e为底的自然对数运算,如果需要计算以其他底数的对数运算,可以利用换底公式来实现。( )
多维向量乘法运算时,会先用张量的最后两维做向量乘法,然后高维采用广播机制,得到运算结果。
- 安装tensorflow2.0开发环境的步骤是: 创建环境并激活;安装需要的模块和包;安装tensorflow2.0;测试。( )
- 采用SoftMax作为模型的最后一层对鸢尾花分三类需要三个神经元。( )
- Jupyter Notebook不仅可以编辑和运行程序,而且还可以将程序和文档组织在一起,将代码、图像、注释、公式、图形、甚至运行结果都整合在同一个文档中,编写出漂亮的交互式文档。( )
如果训练集的准确率高,那么测试集的准确率也一定高。
- 一般来说,回归不用在分类问题上,但是也有特殊情况,比如logistic 回归可以用来解决0/1分类问题。( )
- 在某些情况下,可以用回归解决分类问题,例如:逻辑回归可以解决二分类问题。( )
- 语句x=(3,),执行后x的值为____。
- 执行如下代码,则程序运行后,结果是:____ 。
for i in range(2,10,3):
if i%2:
print(i) - 已知用电量Y(4.5, 4, 3, 2.5)和月份X(1, 2, 3, 4)具有近似的线性相关,如果线性回归方程为y = -0.7x + b,那么b=____。
已知x={1:2},那么执行x[2]=3后,x的值为____ 。
A:16 16 B:16 4 C:4 4 D:4 16
答案:16 4
A:np.arange(10,49) B:np.arange(10,50) C:np.linspace(10,49) D:np.range(10,50)
AI参考:正确答案是【C】np.linspace(10,49)。np.arange(start,stop[,step]) 和 np.range(start,stop[,step]) 用于生成等差数列,但是这里生成的数组的元素个数为50个,因此这两个选项都不合适。np.linspace(start,stop[,num]) 是用于生成等差数列的,其中start和stop是数列的起点和终点,而num则是数列的个数,根据这个可以得出正确的答案。所以正确选项为C。'
A:3 B:死循环 C:无输出 D:4
答案:死循环AI参考:程序的输出结果是:D:4。程序中,x从3开始,进入while循环。在循环体中,首先检查x是否等于4,如果是,则跳出循环,程序结束。但在这里,x并不等于4,因此程序继续执行。接下来检查x是否为偶数,由于x为奇数,所以if x%2==0的条件不满足,程序继续执行下一次循环。最后,x增加1,输出结果为4。因此,这个程序并不会进入死循环,而是会按照预期的逻辑进行输出。所以答案是D:4。'
A:Python变量在使用之前不需要声明 B:print()函数在输出中自动包含换行,默认每次打印一行 C:Python语句的缩进可有可无 D:在Python中,标识符是大小写敏感的
答案:球状蛋白质中无β折叠结构;自然界的蛋白质和多肽类物质均由L-型氨基酸组成
答案:[12, 34, 56, 78]AI参考:输出结果是[[北京, 90], [上海, 80]]。 在Python中,列表的索引是从0开始的,所以img1[1]实际上是访问并修改了第二个元素的值。所以,当我们将img1[1]的值改为90时,列表中的第二个元素的值就被修改为了90。因此,最后的输出结果就是[[北京, 90], [上海, 80]]。"
A:[”玫瑰”,”月季”] B:[“牡丹”] C:[”月季”] D:[“牡丹”, ”月季”]
AI参考:正确答案是【单选题】D:[“牡丹”, ”月季”]。在Python中,列表的切片操作可以删除列表中的一部分元素,这里使用了del a[1:3]来删除列表a中索引为1和2的元素,即芍药和玫瑰,所以输出结果为[“牡丹”,“月季”],因此答案为D。'
A:实数 B:整数 C:字符串 D:True或者False
答案:字符串
A:a的值为10 B:b的值为100 C:函数名称为func D:c的值为200
AI参考:选项C错误。代码中定义了一个名为func的函数,它接受两个参数a和b,返回a的平方加上b的值。函数体中,先将a的值赋给b,再计算a的平方加b的值。最后将该值加上a的值赋给c。在给出的代码中,a的值为10,b的值为100,c的值为210。因此,选项C错误,因为函数名称不是由代码中定义的func。函数名称应该根据需要自行命名。'
A:conda install tensorflow==1.14.0 B:conda install tensorflow=2.0.0 beta C:pip install tensorflow=2.0.0 alpha D:pip install tensorflow==2.0.0
A:输出n的绝对值 B:输出n的阶乘 C:程序运行结果为1 D:判断n是否是素数
A:[“book”,”reader”,200, 100, 10,20 ] B:[“book”,”reader”,200, 100 ] C:[“book”,”reader”,200, 100, [10,20] ] D:[“book”,”reader”,200, 100, 10, [20] ]
AI参考:程序输出的结果应该是 D:[“book”,”reader”,200, 100, 10, [20] ]在 Python 中,`append()` 方法被用来向列表中添加一个元素。在这个程序中,`a` 列表首先被添加了字符串 `“book”,”reader”,200`,然后又被添加了整数 100 和列表 [10,20]。最后,使用 `print()` 函数打印出整个列表 `a`。由于列表的 `append()` 方法不会改变列表的顺序,所以最终输出结果是:原有的元素(200, 100)后面跟上了新的元素(10, [20])。因此,答案是 D。'
A:<tf.Tensor: id=11, shape=(), dtype=float32, numpy=1234567.0> B:<tf.Tensor: id=11, shape=(), dtype=float64, numpy=1234567.0> C:结果报错 D:<tf.Tensor: id=11, shape=(1,), dtype=float32, numpy=1234567.0>
A:tf.add(x,y) B:z=x@y C:tf.multiply(x,y) D:tf.sub(x,y)
AI参考:正确选项是C:tf.multiply(x,y)。tf.multiply(x,y)方法用于将两个张量逐元素相乘。它可以处理两个相同形状的张量,并返回一个新的张量,其中每个元素都是输入张量对应位置元素的乘积。选项A和D中的tf.add(x,y)和tf.sub(x,y)分别用于加法和减法操作,选项B中的@符号是TensorFlow中的张量运算符,但并不能实现两个张量的逐元素相乘。'
A:3 B:10 C:-2 D:5.3
AI参考:选项B解析:首先输入的数字3、10、5.3和4都比数字max小,只有最后输入的数字-2大于当前最大值max,所以将-2赋值给max。最终输出的结果是-2。'
A:”83” B:”888” C:程序出错 D:24
AI参考:答案:D。执行程序段后,x=8,y=24,因此输出结果为y的值,即24。因此,正确选项为D:“24”。'
A:字典中的键可以对应多个值信息 B:字典是键值对的集合 C:字典中元素以键信息为索引访问 D:字典长度是可变的
A:45 B:45.0 C:55.0 D:55
AI参考:正确选项是B: 45.0。程序中的for循环会从1遍历到10,每次将当前数加到sum变量中。最后输出sum的值,即1+2+3+...+10的和,结果是45。由于浮点数在输出时会自动转换为最接近的十进制表示,所以输出结果为45.0。'
A:dict4 = {(1,2,3): “uestc”} B:dict1 = {} C:dict3 ={[1,2,3]: “uestc”} D:dict2 = { 3 : 5 }
A:[“孟浩然”,“王昌龄”] B:[“孟浩然”,”杜甫”] C:[“孟浩然”,”杜甫”,“王昌龄”] D:[“李白”,“孟浩然”,”杜甫”]
A:/*注释*/ B:#注释 C:%注释 D://注释
AI参考:正确选项是 B: #注释。在Python中,单行注释通常使用 "#" 符号表示。这个符号后面的内容会被Python解释器忽略,通常用于添加对代码的解释或备注。例如:```python# 这是一个注释print("Hello, world!") # 输出"Hello, world!"```选项 A 和 C 中的符号 "/*" 和 "%" 并不是Python中的注释符号,选项 D 中的符号 "//" 通常用于多行注释。因此,选项 B "#" 是Python中单行注释的正确表示方式。'
A: 0 02 2 B: 0 01 12 2 C: 0 01 1 D: 1 12 2
AI参考:正确答案是B。程序输出的结果是:0 0 1 2 2。这是两层嵌套循环的结果。外部循环从0到3,依次打印每个内循环的范围值(从i到2),且因为内部循环i的步长是i-j,所以第二个j的输出会在i上步长为j+1。最终的输出顺序就是遍历外部循环后内部的每个范围的结果,符合顺序依次输出。所以,输出结果是0 0 1 2 2。'
A:整数类型、二进制类型、复数类型 B:整数类型、浮点类型、复数类型 C:整数类型、二进制类型、浮点类型 D:十进制类型、二进制类型、十六进制类型
A:运行报错 B:18 C:15 D:5
A:函数中最多只有一个return语句 B:函数必须有一个return语句 C:函数可以没有return语句 D:return只能返回一个值
AI参考:正确选项是:D:return只能返回一个值。在函数中使用return语句需要满足以下条件:1. return语句必须是函数的最后一个语句。2. return语句只能返回一个值,如果需要返回多个值,可以使用元组等结构体类型进行返回。因此,选项D是正确的描述。选项A和B都存在限制条件,选项C则是不正确的描述,因为函数可以没有return语句,但这种情况会导致函数无法正常结束并返回结果。'
A:Not B:None C:Pass D:出错
A:list B:int C:float D:char
A:祖国, B:你好! C:祖国,你好! D:祖国你好!
AI参考:答案为C:祖国,你好!程序段遍历字符串"祖国,你好!"中的每个字符,当遇到逗号","时,使用continue语句跳过当前循环迭代,继续下一次迭代。因此,当遍历到"祖国,"时,会跳过后面的字符,只输出"祖国,";当遍历到"你好!"时,会输出该字符,即"你好!"。所以程序的输出结果为"祖国,你好!"。因此,正确选项为C:祖国,你好!。'
A:其余都不对 B:[ 5, 4, 3, 2 , 1] C:[ 2, 4, 1, 5, 3 ] D:[ 1, 2, 3, 4, 5 ]
AI参考:执行以下代码,得到的正确结果是B:`[ 5, 4, 3, 2 , 1]`。在Python中,`reverse()`函数用于将列表反转。如果传入的参数为`True`,那么会交换列表中相邻元素的顺序,实现反转。因此,原本的列表`a=[ 2,4,1,5,3 ]`会被反转为`[ 5, 4, 3, 2 , 1]`。代码解释:* `a=[ 2,4,1,5,3 ]`:定义一个列表a,包含5个元素。* `a.reverse(True)`:调用列表的`reverse()`函数,将列表反转。* `print(a)`:打印反转后的列表。选项A、C、D都是错误的,因为只有选项B是正确的,它描述了代码运行后的结果。'
A:(2,2) B:(1,1) C:其余都不对 D:(2,3)
AI参考:从给出的代码和语句来看,这里使用了Numpy库来创建了一个二维数组a,然后使用TensorFlow的tf.constant()函数将这个数组转换为一个Tensor对象。这个Tensor对象b的shape应该与原始数组a的shape相同,即(2, 2)。所以,正确的选项是A: (2, 2)。'
A:3 B:6 C:5 D:12
AI参考:正确答案是C,字典d中每个键值对都是一个元素,字典中的键是唯一的,因此len(d)的结果是5。键的数量为3,对应的值有重复,但不会影响键的数量。所以选择C选项。'
A:收入增加,储蓄额增加 B:价格下降,消费增加 C:收入增加,支出增加 D:产量增加,生产费用增加
AI参考:正确选项是 D. d 是一个字典,其中键是 x 列表中的元素,值是 y 列表中的元素。 解释: * `x=[bob,tom,kitty]`:定义了一个列表 x,包含三个字符串元素。 * `y=[80,90,95]`:定义了一个列表 y,包含三个整数元素。 * `d=dict(zip(x,y))`:使用 `zip` 函数将 x 和 y 列表中的对应元素打包成一个个元组,再将这些元组作为字典的键值对。因此,d 是一个字典,其中键是 x 列表中的元素(即 [bob, tom, kitty]),值是 y 列表中的元素(即 [80, 90, 95])。 所以,对于这段代码的正确说法是 D. d 是一个字典,其中键是 x 列表中的元素,值是 y 列表中的元素。"
A:count B:as C:def D:raise
A:返回一种dict_items类型,包括字典d中所有键值对 B:返回一个列表类型,每个元素是一个二元元组,包括字典d中所有键值对 C:返回一个元组类型,每个元素是一个二元元组,包括字典d中所有键值对 D:返回一个集合类型,每个元素是一个二元元组,包括字典d中所有键值对
A:tf.fill() B:tf.range() C:tf.random.uniform() D:tf.random.normal()
AI参考:正确选项是C:tf.random.uniform()。tf.random.uniform()函数可以用来创建元素符合均匀分布的张量。该函数接受三个参数:最小值、最大值和形状,可以根据需要指定张量的形状和范围。tf.fill()函数用于填充张量中的元素,通常用于填充特定值,而不是创建符合均匀分布的张量。tf.range()函数用于生成一个范围序列,但无法直接用于创建符合均匀分布的张量。tf.random.normal()函数可以用来创建元素符合正态分布的张量,而不是均匀分布。因此,选项C是正确答案。'
A:[500,100,200,300] B:[100,2,200,300] C:[100,200,1,300] D:[100,500,300]
AI参考:输出结果为:B: [100,2,200,300]。在Python中,使用.insert()方法可以将元素插入到列表中的任意位置。这里,a.insert(1, 2)是将元素2插入到索引位置1处,此时列表a变成了[100, 2, 200, 300],因此打印结果为[100, 2, 200, 300]。其他选项中,选项A和D中的索引位置超出了列表的范围;选项C中的索引位置1处原本已经有元素100,插入元素后列表顺序被打乱。因此,只有选项B是符合题意的输出结果。'
A:B B:A C:C D:D
A:Spyder B:Jupyter notebook C:VS Code D:Anaconda Navigator
A:for i in range(10,0,-1):sum+=i B:for i in range(11): sum+=i C:for i in range(1,11):sum+=i D:for i in range(10,9,8,7,6,5,4,3,2,1):sum+=i
AI参考:正确答案是B: for i in range(11): sum+=i。选项B中,sum的初始值为0,但for循环的范围是11,而不是从1到10的连续数字,因此无法完成从1到10的累加求和。而其他选项中的for循环语句都能正确完成从1到10的累加求和。选项A中的for循环从10开始递减到1,每次循环将i的值加到sum中,因此可以完成累加求和;选项C中的for循环从1开始,每次循环将i的值加到sum中,因此可以完成累加求和;选项D中的for循环将数字以递减的方式进行迭代,并且数字之间的增量递减,每次循环将i的值加到sum中,因此也可以完成累加求和。因此,正确答案是选项B。'
A:对 B:错
A:对 B:错
A:对 B:错
AI参考:正确答案是B:错。学习率设置得太大可能会引起梯度消失或爆炸,影响模型的收敛速度和效果。因此,在设置学习率时需要谨慎考虑,不能一味地追求提高模型的收敛速度而忽略其他因素。正确的做法应该是根据具体情况选择合适的学习率,以获得更好的模型性能。'
A:错 B:对
A:错 B:对
A:错 B:对
A:对 B:错
AI参考:答案是A:对。根据题目描述,安装TensorFlow 2.0开发环境的步骤是:创建环境并激活;安装需要的模块和包;安装TensorFlow 2.0;测试。这些步骤是正确的。'
A:对 B:错
AI参考:答案是B:错。根据问题的描述,使用SoftMax作为模型的最后一层对鸢尾花进行分类,通常需要多个神经元(通常为四到五个神经元)。因此,使用三个神经元来分类鸢尾花是不够的。因此,答案为B:错。'
A:错 B:对
A:错 B:对
AI参考:答案:B解释:训练集的准确率高,只能说明模型在训练集上的表现好,但不能保证模型在测试集上的表现也一定好。因为模型的性能受到很多因素的影响,如特征选择、模型选择、超参数调整等,这些因素在训练集和测试集上可能存在差异,导致模型在测试集上的表现不一定好。因此,这个说法是正确的。'
A:对 B:错
A:对 B:错
AI参考:执行语句x=(3,)后,x的值为3。这是因为逗号运算符的特性,它首先计算括号内的表达式(3),然后返回这个表达式的值(即3),赋值给变量x。所以x的值就是3。'
AI参考:程序运行后,结果是:7解释:代码中使用了for循环来遍历从2到9的奇数,其中步长为3。在循环中,如果当前数字i是奇数(即i%2为真),则打印出该数字。因此,当i为7时,程序会打印出7。因此,最终结果为7。'
AI参考:已知x={1:2},那么执行x[2]=3后,x的值为{1:3}。在Python中,字典是一个键值对的数据结构,使用大括号{}来表示。当执行x[2]=3时,就是在x字典中新增一个键值对,即第三个元素为3。所以,x的值变成了{1:2, 3:3}。'

