- EM算法一定会收敛,但是可能收敛到局部最优。( )
- ID3决策树学习算法是以信息增益为准则来选择划分属性的。( )
- 逻辑回归LR是参数模型,支持向量机SVM也是参数模型。( )
- 数据集D 的纯度可用它的基尼值来度量,基尼值越大,则数据集D 的纯度越高。( )
- 给定 n 个数据点,如果其中一半用于训练,另一半用于测试,则训练误差和测试误差之间的差别会随着 n的增加而减小。( )
- 在模型中增加更多特征一般会增加训练样本的准确率,减小 bias,但是测试样本准确率不一定增加。( )
- 一般来说,回归不用在分类问题上,但是也有特殊情况,比如logistic 回归可以用来解决0/1分类问题。( )
- 如果自变量 X 和因变量 Y 之间存在高度的非线性和复杂关系,那么树模型很可能劣于经典回归方法。( )
- 选项中哪种方法可以用来减小过拟合?( )
- 变量选择是用来选择最好的判别器子集, 如果要考虑模型效率,我们应该做哪些变量选择的考虑?( )
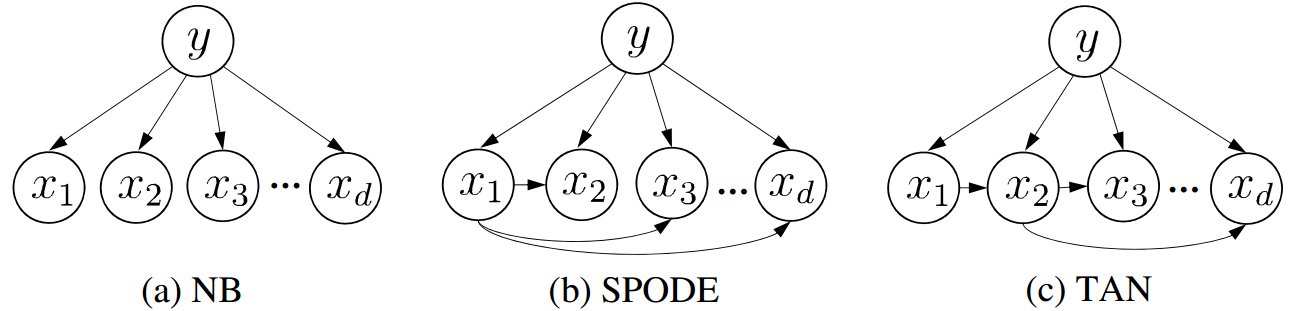
- 关于SVM与感知机,选项中说法正确的是:( )
- 选项中关于 Random Forest 和 Gradient Boosting Trees 说法正确的是?( )
- 假如使用一个较复杂的回归模型来拟合样本数据,使用 Ridge 回归,调试正则化参数 λ,来降低模型复杂度。若 λ 较小时,关于偏差(bias)和方差(variance),下列说法正确的是?( )
- 朴素贝叶斯分类器是一种特殊的Bayes分类器,特征变量是X,类别标签是C,它的一个假定是:( )
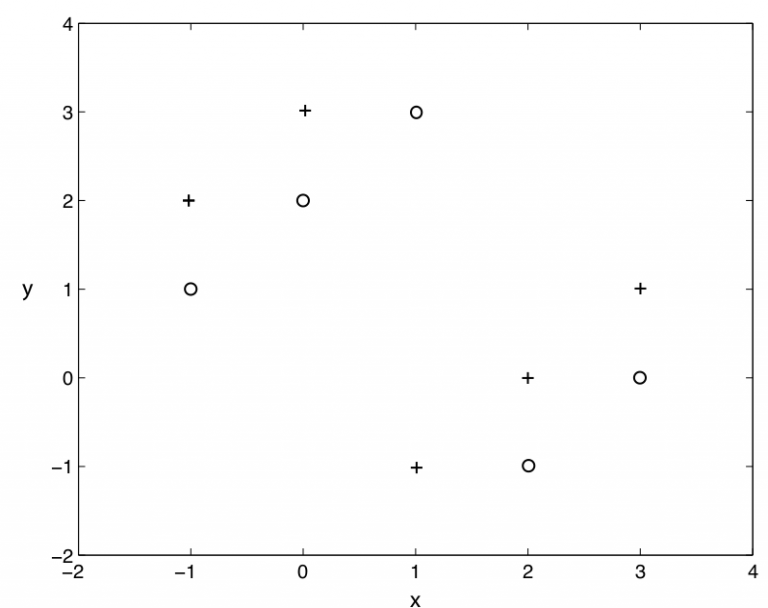
- 在数据预处理阶段,我们常常对数值特征进行归一化或标准化(standardization, normalization)处理。这种处理方式理论上不会对下列哪个模型产生很大影响?( )
- 下面哪句话是正确的?( )

- 假设某地区流行病识别中,正常(w1)和异常(w2)两类的先验概率分别为:正常状态: P(w1)=0.9异常状态: P(w1)=0.1现有一待识别个例,其观察值为x,从类条件概率密度分布曲线上可查得:p(x|w1)=0.2,p(x|w2)=0.4那么该个例的状态是 ( )
- 下列说法错误的是?( )
- 下列哪种方法可以用来减小过拟合?( )
- 回归问题和分类问题都有可能发生过拟合。( )
- k均值算法可看作是高斯混合聚类在混合成分方差相等、且每个样本仅指派给一个混合成分时的特例。( )
- 一个循环神经网络可以被展开成为一个完全连接的、具有无限长度的普通神经网络。( )
- 支持向量机SVM是结构风险最小化模型,而逻辑回归LR是经验风险最大化模型。( )
- L1范数和L2 范数正则化都有助于降低过拟合风险,但后者还会带来一个额外的好处:它比前者更易于获得"稀疏" (sparse)解。( )
- 决策树的分界面是线性的。( )
- 在决策树学习过程中,如果当前结点划分属性为连续属性,那么该属性还可作为其后代结点的划分属性。( )
- K-means算法中初始点的选择对最终结果没有影响,不同的初始值结果都一样。( )
- 监督式学习中存在过拟合,而对于非监督式学习来说,没有过拟合。( )
- SVM对缺失数据敏感,而且当观测样本很多时,SVM方法的效率也不是很高。( )
- 在决策树的划分属性选择中,信息增益准则对可取值数目较少的属性有所偏好,而增益率准则对可取值数目较多的属性有所偏好。( )
- Logistic回归目标函数是最小化后验概率。( )
- 剪枝(pruning)是决策树学习算法对付"欠拟合"的主要手段,其基本策略有"预剪枝" (pre-pruning)和"后剪枝"(post-pruning)。( )
- 对于 PCA 处理后的特征,其朴素贝叶斯特征相互独立的假设一定成立,因为所有主成分都是正交的,所以不相关。( )
- SVM不直接依赖数据分布,而逻辑回归LR则依赖整体数据分布,因为SVM只与支持向量那几个点有关系,而LR和所有点都有关系。( )
- 后剪枝决策树通常比预剪枝决策树保留了更多的分支。一般情形下,后剪枝决策树的欠拟合风险很小,泛化性能往往优于预剪枝决策树。( )
- 关于神经网络,下列说法正确的是?( )
- 以下描述中,对梯度解释正确的是( )
- 建立线性模型时,我们看变量之间的相关性。在寻找相关矩阵中的相关系数时,如果发现 3 对变量(Var1 和 Var2、Var2 和 Var3、Var3 和 Var1)之间的相关性分别为 -0.98、0.45 和 1.23。我们能从中推断出什么呢?( )
- 对于划分属性选择,选项中说法正确的是( )
- 影响聚类算法结果的主要因素有( )。
- 下列方法中,可以用于特征降维的方法包括?( )
- 下列关于 PCA 说法正确的是?( )
- 以下哪种方法属于判别式模型(discriminative model)?( )
- 集成学习中个体学习器多样性增强的主要途径有:( )
- 有一些基学习器对数据样本的扰动不敏感,称为稳定基学习器。下列学习器属于稳定基学习器的是:( )
- 智能化中医望诊时,对一幅舌脉图像(伸出舌头的人脸图像),希望把舌头部分从人脸的其他部分划分出来,可以采用以下方法:将整幅图的每个象素的属性记录在一张数据表中,然后用某种方法将这些数据按它们的自然分布状况划分成两类。因此每个象素就分别得到相应的类别号,从而实现了舌头图像的分割。那么这种方法属于:( )
- 关于 L1、L2 正则化下列说法正确的是?( )
- 已知坐标系中两点A(2,−2)和B(−1,2),这两点的曼哈顿距离(L1距离)是( )
- 模型的bias很高, 我们如何降低它? ( )
- K-Means 算法无法聚以下哪种形状的样本?( )
- k-NN 最近邻方法在什么情况下效果较好?( )
- 假定你在神经网络中的隐藏层中使用激活函数 X。在特定神经元给定任意输入,你会得到输出 -0.01。X 可能是以下哪一个激活函数? ( )
- 如果我们说“线性回归”模型完美地拟合了训练样本(训练样本误差为零),则下面哪个说法是正确的?( )
- 假设我们使用原始的非线性可分版本的 Soft-SVM 优化目标函数。我们需要做什么来保证得到的模型是线性可分离的?( )
- 线性回归能完成的任务是( )
- Dropout技术在下列哪种神经层中将无法发挥显著优势?( )
- 逻辑回归将输出概率限定在 [0,1] 之间。下列哪个函数起到这样的作用?( )
- 选项中关于线性回归分析中的残差(Residuals)说法正确的是?( )
- 机器学习训练时,Mini-Batch 的大小优选为2个的幂,如 256 或 512。它背后的原因是什么?( )
- 如果两个变量相关,那么它们一定是线性关系吗?( )
- 选项中哪些方法不可以直接来对文本分类?( )
- 我们想在大数据集上训练决策树, 为了使用较少时间, 我们可以( )
- 关于欠拟合(under-fitting),下面哪个说法是正确的?( )
- 在 n 维空间中(n > 1),下列哪种方法最适合用来检测异常值?( )
- SVM中核技巧(Kernal trick)的作用包括以下哪项?( )
- 关于特征选择,下列对 Ridge 回归和 Lasso 回归说法正确的是?( )
- 我们希望减少数据集中的特征数量。你可以采取以下哪一个步骤来减少特征?( )
- 下列哪一种方法的系数没有闭式(closed-form)解?( )
- 关于L1正则和L2正则 下面的说法正确的是( )
- 以下哪些方法不可以直接来对文本分类?( )
- 我们想要训练一个 ML 模型,样本数量有 100 万个,特征维度是 5000,面对如此大数据,如何有效地训练模型?( )

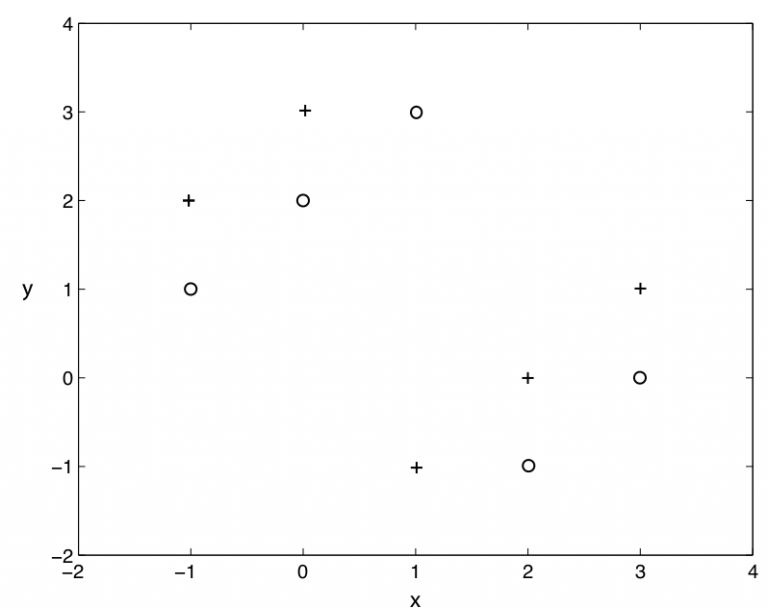
- 下列哪些算法可以用来够造神经网络?( )
- 如何在监督式学习中使用聚类算法?( )
- 向量x=[1,2,3,4,-9,0]的L1范数是 ( )
- k均值算法和"学习向量量化"都是原型聚类方法,也都属于无监督学习方法。( )
- K-Means聚类的主要缺点有:( )
- 下列聚类方法属于原型聚类的是 ( )
- 数据科学家经常使用多个算法进行预测,并将多个机器学习算法的输出(称为“集成学习”)结合起来,以获得比所有个体模型都更好的更健壮的输出。则下列说法正确的是?( )
- 下面关于 Random Forest 和 Gradient Boosting Trees 说法正确的是?( )
- 如果用“三个臭皮匠顶个诸葛亮”来比喻集成学习的话,那么对三个臭皮匠的要求可能是:( )
- 集成学习中个体学习器的多样性不宜高,否则容易顾此失彼,降低系统的总体性能。( )
- 以下方法属于集成学习方法的是( )
- 下列关于极大似然估计(Maximum Likelihood Estimate,MLE),说法正确的是( )
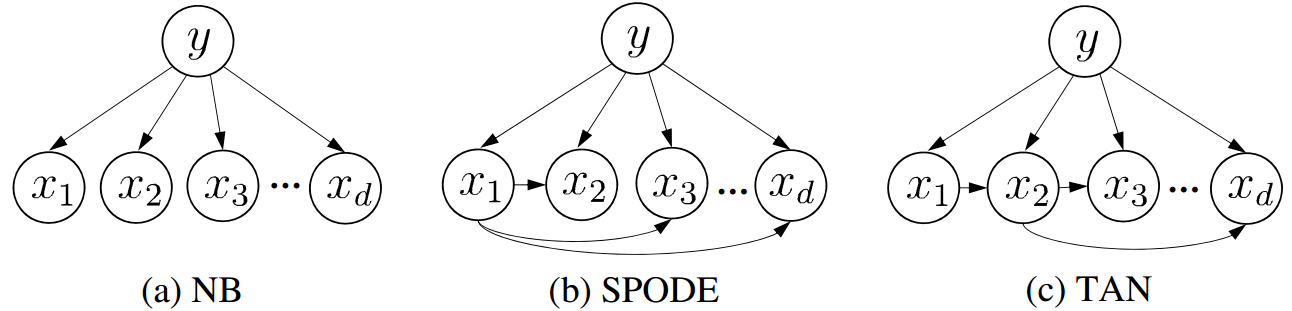
- 朴素贝叶斯分类器有属性条件独立的假设前提。( )
- 朴素贝叶斯属于生成式模型,而SVM和决策树属于判别式模型。( )
- 关于贝叶斯网络,以下说法正确的是:( )
- 逻辑回归LR是参数模型,支持向量机SVM是非参数模型。( )
- 关于SVM与感知机,以下说法正确的是:( )
- 如果SVM模型欠拟合, 以下方法哪些可以改进模型( )
- 支持向量机SVM是结构风险最小化模型,而逻辑回归LR是经验风险最小化模型。( )
- 在训练完 SVM 之后,我们可以只保留支持向量,而舍去所有非支持向量,仍然不会影响模型分类能力。( )
- 关于SVM如何选用核函数,下列说法正确的是:( )
- 深度神经网络中常用Relu函数作为激活函数,其好处是:( )
- 梯度爆炸问题是指在训练深度神经网络的时候,梯度变得过大而损失函数变为无穷。在RNN中,下面哪种方法可以较好地处理梯度爆炸问题?( )
- 在回归模型中,下列哪一项在权衡欠拟合(under-fitting)和过拟合(over-fitting)中影响最大?( )
- 在决策树分割结点的时候,下列关于信息增益说法正确的是( )
- 对于划分属性选择,以下说法正确的是( )
- 在决策树学习过程中,用属性α 对样本集D 进行划分所获得的"信息增益"越大,则意味着使用属性α 来进行划分所获得的"纯度提升"越大。( )
- 数据集D 的纯度可用它的基尼值来度量,基尼值越小,则数据集D 的纯度越高。( )
- 如果自变量 X 和因变量 Y 之间存在高度的非线性和复杂关系,那么树模型很可能优于经典回归方法。( )
- 一般来说,下列哪种方法常用来预测连续独立变量?( )
- 点击率预测是一个正负样本不平衡问题(例如 99% 的没有点击,只有 1% 点击)。假如在这个非平衡的数据集上建立一个模型,得到训练样本的正确率是 99%,则下列说法正确的是?( )
- 加入使用逻辑回归对样本进行分类,得到训练样本的准确率和测试样本的准确率。现在,在数据中增加一个新的特征,其它特征保持不变。然后重新训练测试。则下列说法正确的是?( )

- 下列关于线性回归分析中的残差(Residuals)说法正确的是?( )
- 下列哪些假设是我们推导线性回归参数时遵循的?( )
- 下列关于 bootstrap 说法正确的是?( )
- 评估完模型之后,发现模型存在高偏差(high bias),应该如何解决?( )
- 小明参加Kaggle某项大数据竞赛,他的成绩在大赛排行榜上原本居于前20,后来他保持特征不变,对原来的模型做了1天的调参,将自己的模型在自己本地测试集上的准确率提升了3%,然后他信心满满地将新模型的预测结果更新到了大赛官网上,结果懊恼地发现自己的新模型在大赛官方的测试集上准确率反而下降了。对此,他的朋友们展开了讨论,下列说法正确的是( )
- 对于k折交叉验证, 以下对k的说法正确的是 ( )
- 从归纳偏好一般性原则的角度看,"奥卡姆剃刀" (Occam's razor)准则与“大道至简”说的是相同的道理。( )
- 机器学习学得的模型适用于新样本的能力,称为"泛化"能力,这是针对分类和回归等监督学习任务而言的,与聚类这样的无监督学习任务无关。( )
- 输出变量为有限个离散变量的预测问题是回归问题;输出变量为连续变量的预测问题是分类问题。( )
- 回归和分类都是有监督学习问题。( )
- 关于“回归(Regression)”和“相关(Correlation)”,下列说法正确的是?注意:x 是自变量,y 是因变量。( )
- 机器学习时,我们通常假设样本空间中的全体样本都服从某个未知"分布",并且我们获得的每个样本都是独立地从这个分布上采样获得的。( )
- 归纳学习相当于"从样例中学习",即从训练样例中归纳出学习结果。( )
- 以下方法或系统属于"符号主义" (symbolism)学习技术的是( )
- 以下方法或技术属于统计学习范畴的是( )
- 如果一个经过训练的机器学习模型在测试集上达到 100% 的准确率,这就意味着该模型将在另外一个新的测试集上也能得到 100% 的准确率。( )
答案:对
答案:对
答案:错
答案:错
答案:对
答案:对
答案:对
答案:错
答案:L2 正则化###减小模型的复杂度###L1 正则化###更多的训练数据
答案:多个变量是否有相同的功能###交叉验证###特征是否携带有效信息
答案:(b)###(c)
温馨提示支付 ¥5.00 元后可查看付费内容,请先翻页预览!



