提示:内容已经过期谨慎付费,点击上方查看最新答案
应用数理统计
- 设
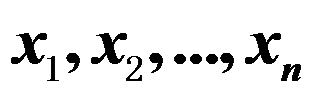 是取自正态总体
是取自正态总体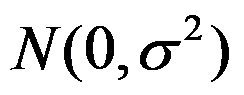 的样本,则参数
的样本,则参数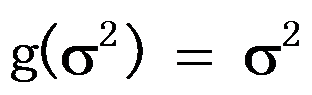 的C-R方差下界为( )。
的C-R方差下界为( )。 - 用仪器测量某物理量
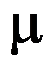 ,其测量值服从正态分布,标准差为
,其测量值服从正态分布,标准差为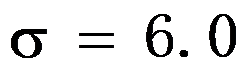 ,
,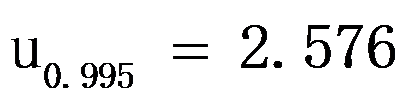 。至少要重复测量( )次,才能使
。至少要重复测量( )次,才能使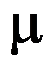 的0.99置信区间长度为8。
的0.99置信区间长度为8。 - 费歇尔信息量的表达式为( )。
- 设是取自正态总体
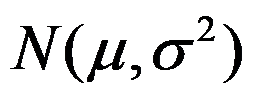 的样本,其中
的样本,其中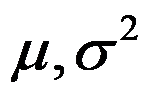 是未知参数,则
是未知参数,则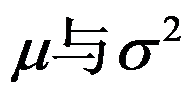 的最大似然估计为( )。
的最大似然估计为( )。 - 设是取自总体的一个样本,总体的密度函数为:
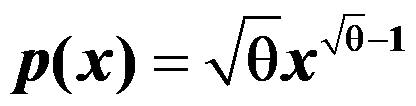
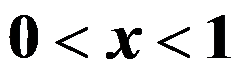 ,则参数
,则参数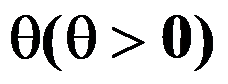 的矩估计为( )。
的矩估计为( )。 - 对于两正态总体,方差已知,但不相等时,检验统计量为( )。
- 设
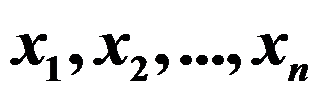 是来自指数分布
是来自指数分布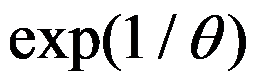 的一个样本,其概率密度为
的一个样本,其概率密度为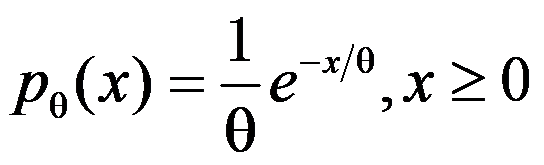 ,其中
,其中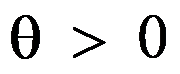 为总体均值,即
为总体均值,即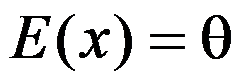 。则
。则 的
的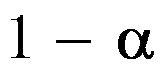 置信区间为( )。
置信区间为( )。 - 设一个物体的重量
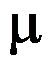 未知,为了估计其重量,可以用天平去称,假定称重服从正态分布。如果已知称重误差的标准差为0.1克,为了使的95%置信区间的长度不超过0.2,
未知,为了估计其重量,可以用天平去称,假定称重服从正态分布。如果已知称重误差的标准差为0.1克,为了使的95%置信区间的长度不超过0.2,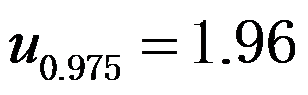 ,那么至少应该称( )次。
,那么至少应该称( )次。 - 判断估计好坏的标准有( )。
- 正态总体
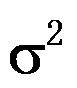 已知的场合,对于假设:
已知的场合,对于假设: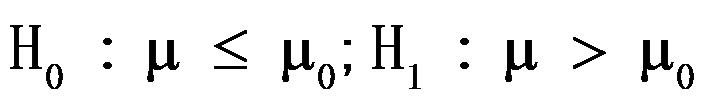 ,
,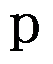 值的计算公式为:
值的计算公式为: 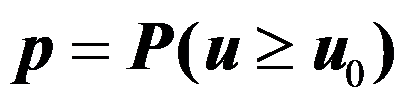 。( )
。( ) - 正态总体
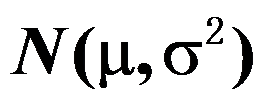 ,
, 未知,为一组样本,对于检验
未知,为一组样本,对于检验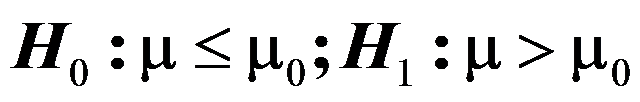 ,其统计量为
,其统计量为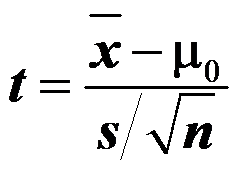 ,拒绝域为
,拒绝域为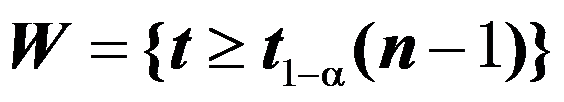 。( )
。( ) - 如两正态总体相互独立,则
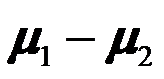 的1-α置信区间为
的1-α置信区间为 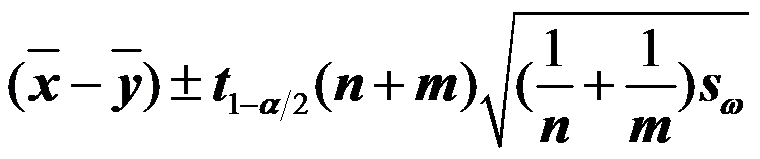 。( )
。( ) - 设
 是来自正态总体
是来自正态总体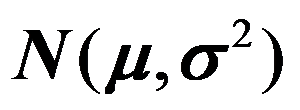 的一个样本, 检验问题
的一个样本, 检验问题 的p值
的p值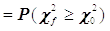 。( )
。( ) - 若总体
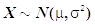 ,
, 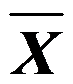 为样本均值,n为样本容量,则
为样本均值,n为样本容量,则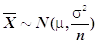 。( )
。( ) - 卡方拟合优度检验的检验统计量为
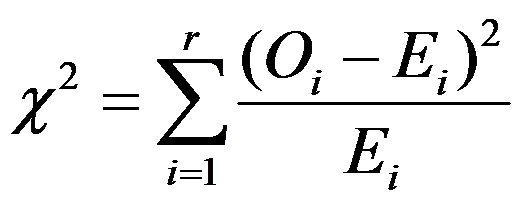 ,其中
,其中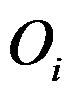 为实际出现的频数,
为实际出现的频数,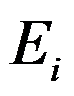 是在服从均匀分布的情况下的次数。( )
是在服从均匀分布的情况下的次数。( ) - 正态方差
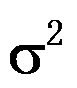 的
的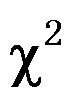 检验,检验统计量为
检验,检验统计量为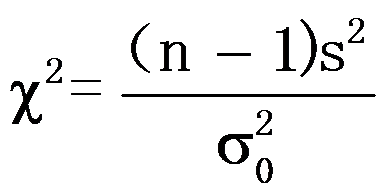 。 ( )
。 ( ) - 某医院用一种中药治疗高血压,记录了50例治疗前后病人舒张压数据之差,得其均值为16.28,样本标准差为10.58,
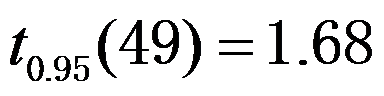 。假定舒张压之差服从正态分布,问在
。假定舒张压之差服从正态分布,问在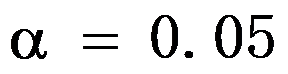 水平上该中药对治疗高血压是否有效,其假设为
水平上该中药对治疗高血压是否有效,其假设为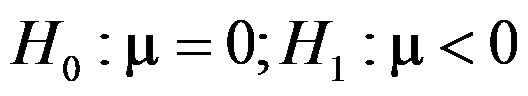 。( )
。( ) - 柯莫哥洛夫检验也是一种拟合优度检验,用完全已知的连续分布去拟合经验分布函数,有精确分布或渐进分布,其p值也可算出。( )
- 在求解贝叶斯可信区间时需要构造枢轴量。( )
- 假设检验问题常用的方法有拒绝域法和P值法。( )
- 写出
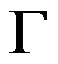 函数的定义:
函数的定义: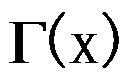 =
=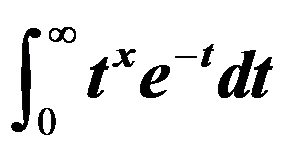 。( )
。( ) - 考察成对数据是在两个正态总体独立的情况下使用的。( )
- 若
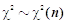 ,则
,则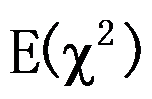 =n 。( )
=n 。( ) - 判断伽玛分布与卡方分布的关系:
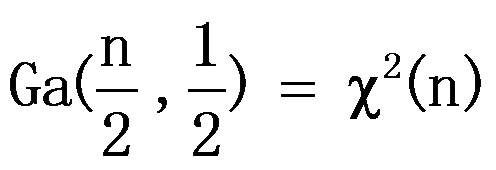 。 ( )
。 ( ) - 设随机变量
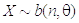 ,
, 为待估参数,若
为待估参数,若 的先验分布为
的先验分布为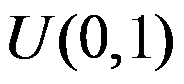 ,则
,则 的
的
后验分布为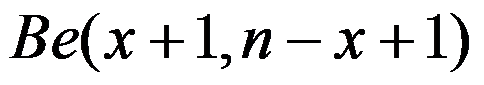 。( )
。( ) - 一般情况下,等尾置信区间比最大后验密度区间的长度短,更为理想。( )
- 卡方拟合优度检验最早用来解释孟德尔的遗传学说。( )
- 在一个检验问题中采用u检验,其拒绝域为
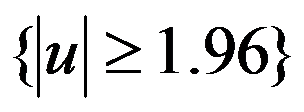 ,据样本求得
,据样本求得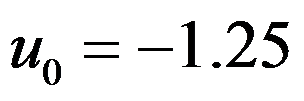 ,则检验的p值=0.1056。( )
,则检验的p值=0.1056。( ) - 正态均值
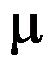 的
的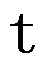 检验,检验统计量为
检验,检验统计量为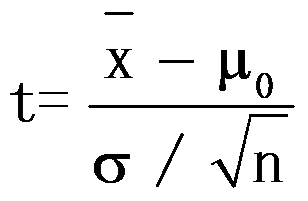 。 ( )
。 ( ) - 构造先验分布的常用方法是共轭先验分布。( )
- 设某电子元件的寿命服从指数分布,其分布函数为:
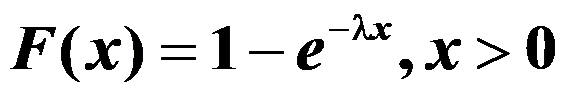 ,从中随机抽取10个元件,测得其寿命
,从中随机抽取10个元件,测得其寿命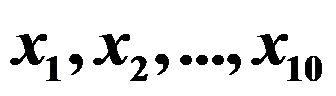 ,则到1000小时没有一个元件失效的概率为
,则到1000小时没有一个元件失效的概率为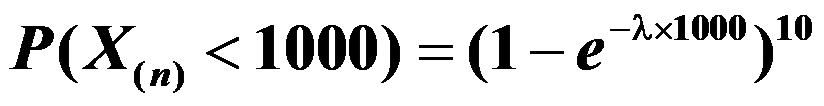 。( )
。( ) - 若条件分布
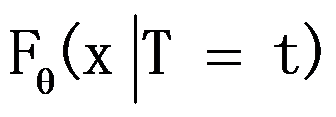 不依赖于参数
不依赖于参数 ,则统计量
,则统计量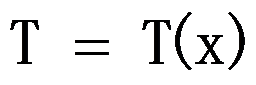 是充分统计量。 ( )
是充分统计量。 ( ) - 一支香烟中的尼古丁含量X服从正态分布
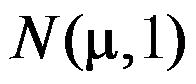 ,合格标准规定
,合格标准规定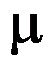 不能超过1.5mg。对于一批香烟的尼古丁含量是否合格作判断,可建立假设:
不能超过1.5mg。对于一批香烟的尼古丁含量是否合格作判断,可建立假设: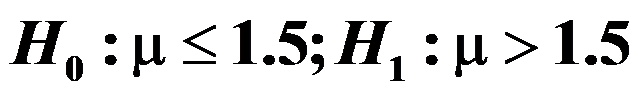 。现随机抽取一盒(20支)香烟,测得平均每支香烟的尼古丁含量为
。现随机抽取一盒(20支)香烟,测得平均每支香烟的尼古丁含量为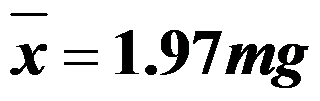 ,取
,取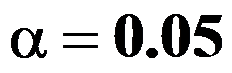 ,则
,则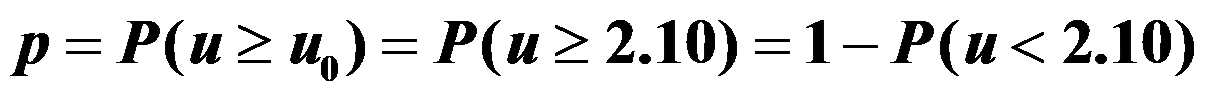
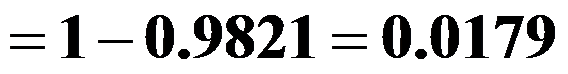 ,因
,因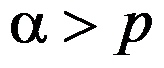 ,故接受原假设,即认为尼古丁的含量合格。( )
,故接受原假设,即认为尼古丁的含量合格。( ) - 统计量
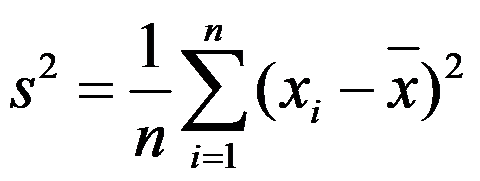 是
是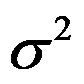 的无偏估计。( )
的无偏估计。( ) - C-R不等式可以用于求出相合估计的方差下界。 ( )
- 在正态总体下,标准差σ的1-α置信区间为
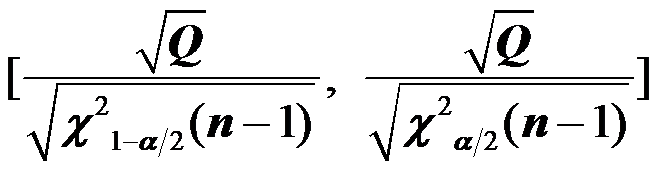 。( )
。( ) - 次序统计量总是充分统计量。( )
- 某化纤强力长期以来标准差稳定在
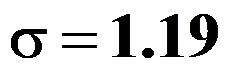 ,现抽取一个容量为
,现抽取一个容量为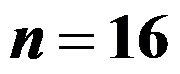 的样本,求得样本均值
的样本,求得样本均值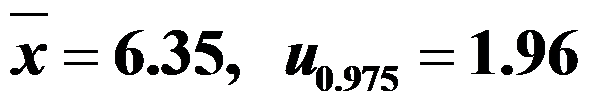 ,则求该化纤强力均值
,则求该化纤强力均值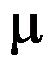 的置信水平为0.95的置信区间为
的置信水平为0.95的置信区间为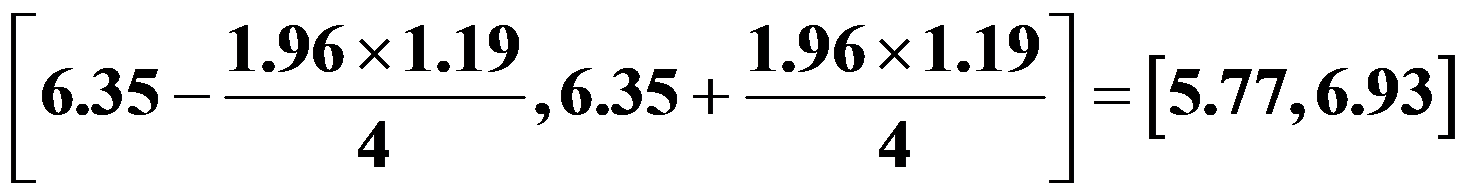 。( )
。( ) - 贝叶斯可信区间使用的是先验分布。( )
- 用
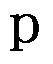 值法进行假设检验时,若
值法进行假设检验时,若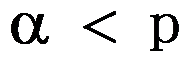 值,则接受原假设
值,则接受原假设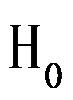 。( )
。( ) - 设是取自正态总体
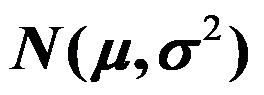 的样本,若
的样本,若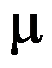 已知,则
已知,则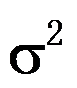 的C-R方差下界为
的C-R方差下界为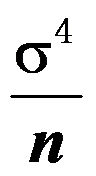 。( )
。( ) - 对于正态总体,当方差未知时,
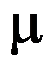 的
的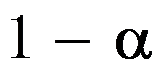 同等置信区间为
同等置信区间为 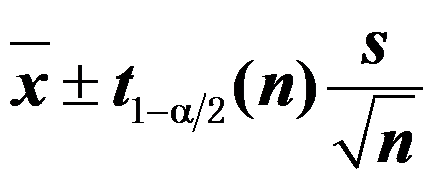 。( )
。( ) - 设
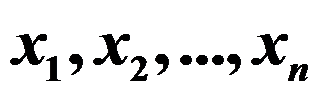 是取自伽玛分布
是取自伽玛分布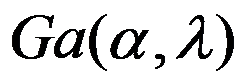 的一个样本,则参数
的一个样本,则参数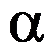 与
与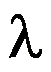 的矩估计分别为
的矩估计分别为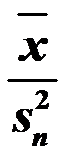 和
和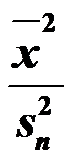 。( )
。( ) - 正态方差
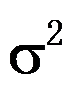 的
的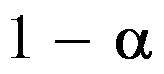 同等置信区间为
同等置信区间为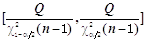 。( )
。( ) - 每克水泥混合物释放的热量X(卡路里)近似服从正态分布
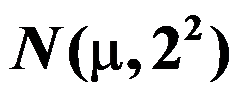 ,用n=9的样本检验
,用n=9的样本检验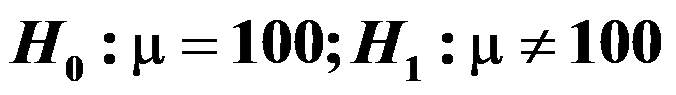 。若取
。若取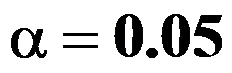 ,则拒绝域为
,则拒绝域为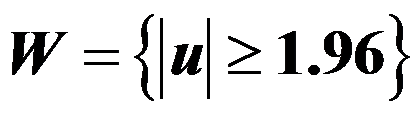 ,而
,而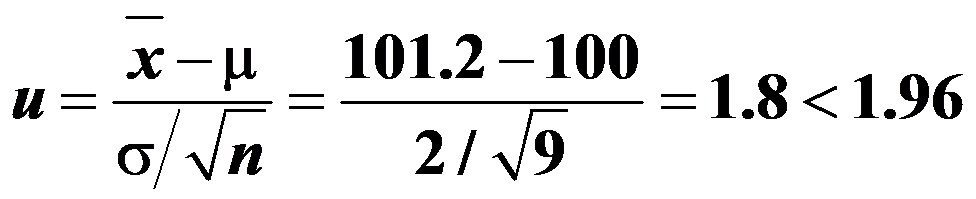 ,故应拒绝原假设。( )
,故应拒绝原假设。( ) - 样本观察值
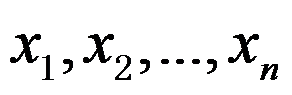 落在接受域
落在接受域 内的概率称为势函数。( )
内的概率称为势函数。( ) - 为了估计不合格品率
 ,从一批产品中随机的抽取n件,其中不合格品率为X,又设的先验分布为贝塔分布
,从一批产品中随机的抽取n件,其中不合格品率为X,又设的先验分布为贝塔分布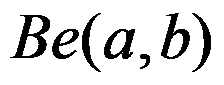 ,其中a,b已知。 则的后验分布为
,其中a,b已知。 则的后验分布为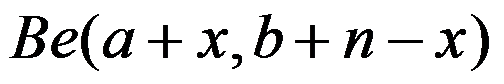 , 的贝叶斯估计为
, 的贝叶斯估计为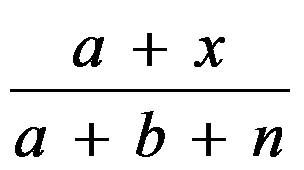 。( )
。( ) - 假设检验中,犯两类错误的概率可以同时增大或同时减小。( )
- 写出样本p分位数的计算公式
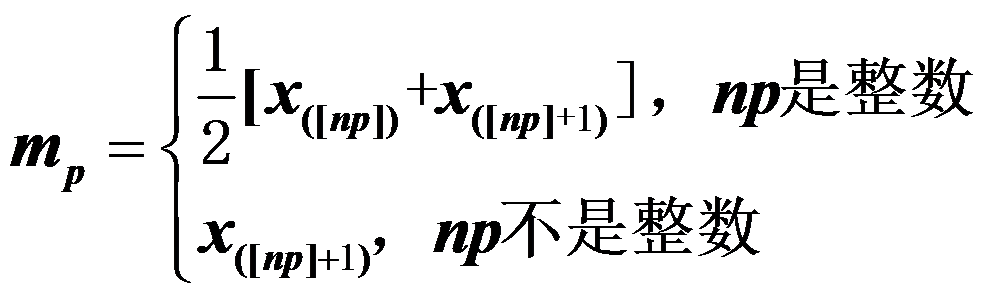 。( )
。( ) - 无偏性、相合性和渐进正态性都是在大样本条件下对一个估计的基本要求。( )
- 考察两种不同的挤压机生产的钢棒的直径,各取一个样本测其直径,其样本量
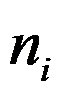 、样本均值
、样本均值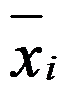 与样本方差
与样本方差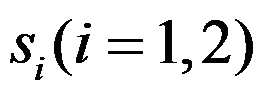 分别为:
分别为: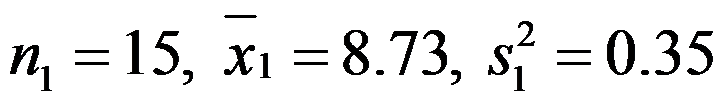
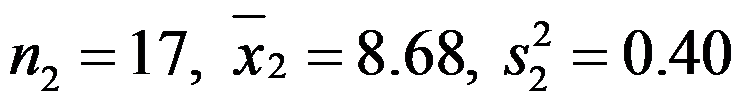
已知两样本均源自方差相等的正态总体,则平均直径差的0.95置信区间为[-0.39,0.49]。( ) - K-S检验中统计量的构造也用到了经验分布函数。( )
- 矩估计和最大似然估计都具有渐进正态性。( )
- 两正态总体
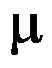 的检验,对于假设:
的检验,对于假设: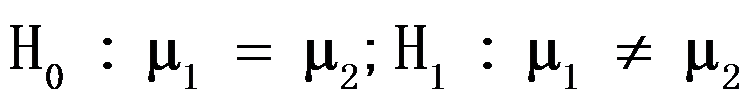 ,拒绝域为:W=
,拒绝域为:W=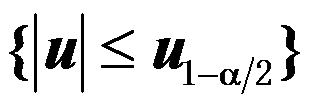 。( )
。( )
A: B: C: D:
AI参考:选项B是正确的答案。根据题干给出的信息,样本是来自正态总体的一部分,因此总体参数未知。C-R方差下界用于估计样本统计量与总体参数之间的差异,因此在这里,由于总体参数未知,无法确定C-R方差下界的具体数值。因此,正确答案为B,即“无法确定”。'
A:14 B:13 C:12 D:15
答案:15
A: B: C: D:
AI参考:正确答案是D:费歇尔信息量 = 概率 × 事件发生的可能性。费歇尔信息量是一种衡量不确定性的指标,用于衡量某个事件是否发生的可能性,通常用分数表示,数值越小说明不确定性越小。因此,费歇尔信息量的表达式应该是简单的乘积,即概率乘以事件发生的可能性,所以选项D“费歇尔信息量 = 概率 × 事件发生的可能性”是正确的。'
A: B: C: D:
AI参考:答案:C推理过程:由题意知,样本值已知,未知参数未知,则属于有放回简单随机抽样,根据简单随机抽样样本平均数的公式求出平均数的最大似然估计量。即得样本均值X(样本中的所有值之和/样本次数)≈(78*2+64*2+37)/(2+2+1)=64,即最大似然估计为C。注:正态分布的图像是钟型曲线,关于平均数对称,标准差σ>0。本题考察的是样本的简单随机抽样以及最大似然估计的应用。答案为C。'
A: B: C: D:
AI参考:答案:C解析:矩估计法是通过样本数据估计总体参数的一种方法。它利用样本数据计算样本矩,再通过比较样本矩和总体矩的数值关系,对参数进行估计。具体来说,我们用样本矩替换总体矩,并采用简单的代数方法求得参数的矩估计。根据给定的总体密度函数和样本,我们需要对参数μ进行矩估计。由题干给出的总体密度函数可得:当自变量x取所有可能的值时,对应的概率密度函数值之和为1。由
可知,总体共有n=7个样本点,所以概率密度函数值之和为7/N。矩估计法的基本步骤为:(1)用样本矩替换总体矩,并求出其样本值;(2)通过观察样本值的变化趋势,根据概率的性质求出样本矩的数学期望,即矩估计值;(3)将求得的矩估计值代入总体参数的公式中,求出参数的矩估计值。已知表示均值μ的样本估计值为:所以的矩估计为:μ=7×。因此选项C是正确答案。请注意:此处仅仅是一个简化版的分析过程,仅适用于问题给出的这种已知密度函数的情况。对于实际问题,需要根据实际情况来考虑使用其他统计方法来处理。'A: B: C: D:
AI参考:正确答案是C:方差相等的假设检验统计量。根据题目中的描述,两正态总体方差已知但不相等,需要进行假设检验,以检验两个总体的方差是否相等。在这种情况下,检验统计量为方差相等的假设检验统计量。因此,选项C为正确答案。选项A、B、D都与题目描述不符,不是正确的选项。'
A: B: C: D:
AI参考:根据所给图片,可以得知样本的概率密度函数为指数分布的概率密度函数。在指数分布中,概率密度函数是恒定的,并且只依赖于随机变量的期望值。对于给定的样本,其总体均值即为概率密度函数的中心点。因此,置信区间的中心点应该与总体均值相等。另外,置信区间是用于估计总体参数的区间范围,通常使用正态分布来计算。根据正态分布的性质,置信区间的上限应该大于下限,并且与总体均值之间存在一个固定的距离。根据所给图片,样本的置信区间应该是正态分布的置信区间。因此,可以得出结论:样本的置信区间为(B)。因此,正确答案是B:B。'
A:5 B:6 C:7 D:4
答案:16
A:均方误差准则 B:有效性 C:一致最小方差无偏估计 D:相合性
答案:有需求(用户)_有优势(竞品)_技术可实现(技术)_有利益(商业)AI参考:正确选项为:A:均方误差准则;B:有效性;C:一致最小方差无偏估计。这个问题的答案可以根据基本概念推断出来。判断估计好坏的标准主要包括均方误差准则(A正确)、有效性(B正确)和一致最小方差无偏估计(C正确)。相合性(D)主要用于描述统计量的极限行为,而不是评价估计优劣的标准。'
A:对 B:错
AI参考:答案是B:错。 根据题目描述,正态总体已知的场合,对于假设值的计算公式应该是一个具体的数学公式,而不是一个简单的图片。因此,该陈述是错误的。"
A:对 B:错
AI参考:答案是B:错。 根据题目描述,正态总体未知,样本为一组数据,要检验一个统计量是否符合某个假设,需要知道总体分布的具体信息,因此无法做出判断。另外,拒绝域也是基于总体分布的信息来确定的,在没有总体分布信息的情况下,无法确定拒绝域。因此,本题是错误的。"
A:对 B:错
AI参考:正确答案是B:错。 根据题意,两正态总体相互独立,但无法确定两个总体的方差是否相等,因此无法确定置信区间的范围。所以该判断题错误。"
A:对 B:错
答案:对AI参考:答案是B:错。 根据问题描述,
是来自正态总体中的一个样本,但并未说明要检验什么问题,因此无法给出该问题的 p 值。因此,答案是 B,错误。"A:对 B:错
AI参考:答案是B:错。 根据题目描述,样本均值是样本中各数据值除以样本容量的结果,而题目中给出的三个图像并没有给出样本容量n的具体数值,因此无法确定样本均值的具体数值。所以,该题是错误的。"
A:对 B:错
AI参考:答案是B:错。 卡方拟合优度检验的检验统计量是根据实际观测频数和理论频数计算的,与均匀分布无关。因此,该题表述错误。"
A:错 B:对
AI参考:答案:B。根据正态分布的性质,其方差恒等于2,所以第一个空填“对”。再根据双侧检验的原理,可判断第三个空填“Z”。根据题目要求,应选B。需要强调的是,这只是一个可能的选择,并不意味着这是一个完全正确的答案,具体情况需要依据题目的实际内容来分析。"
A:对 B:错
答案:计量资料AI参考:答案是B:错。 根据题意,样本数据符合正态分布,因此需要使用正态分布的假设来进行推断。在水平上该中药对治疗高血压是否有效,需要使用假设检验的方法,根据样本数据和假设检验的原理,判断该中药是否具有有效性。 根据题干描述,样本均值为16.28,样本标准差为10.58,这两个数值可以用来计算正态分布的均值和标准差,从而判断假设是否成立。如果样本数据符合正态分布,并且假设成立,那么可以推断该中药对治疗高血压有效;反之,如果样本数据不符合正态分布,或者假设不成立,那么需要重新考虑该中药的有效性。 因此,题干中的陈述只给出了样本数据的统计信息,并没有给出关于假设检验的具体结论,所以不能确定该中药对治疗高血压是否有效。所以选项B“错”是正确的。"
A:错 B:对
A:错 B:对
AI参考:答案:B:对。 在求解贝叶斯可信区间时需要构造枢轴量,因此选项B是正确的。贝叶斯可信区间是一种基于贝叶斯统计推断的方法,它通过构造枢轴量来估计参数的置信区间。"
A:错 B:对
A:错 B:对
AI参考:这是一个对的判断题。 题目中给出的三个图像链接分别代表三个函数的定义,因此,题目描述的内容是正确的。具体来说,第一个图像链接可能代表一个函数原型,第二个图像链接可能代表函数的参数列表,第三个图像链接可能代表函数的实现细节。因此,整个描述是正确的,所以答案是B:对。"
A:对 B:错
AI参考:答案是B:错。考察成对数据通常是在一个或多个变量之间存在关系的情况下使用的,而不是在两个正态总体独立的情况下使用。因此,这个说法是错误的。"
A:对 B:错
AI参考:答案是B:错。 根据题目描述,两个
A:错 B:对
AI参考:B:对。伽玛分布和卡方分布都是概率论中的离散型概率分布,它们之间存在一定的关系。具体来说,当伽玛分布的形状参数和尺度参数相等时,它就转化成了卡方分布。因此,答案是B:对。"
A:对 B:错
AI参考:正确答案是B:错。 根据贝叶斯定理,设随机变量X为待估参数,先验分布为P(X=x),后验分布为P(X=x|数据),其中数据为观测到的数据。因此,如果已知先验分布,但不知道数据的情况下,无法确定后验分布。因此,本题中的判断是错误的。"
A:对 B:错
AI参考:答案是B:错。 等尾置信区间和最大后验密度区间是两种常用的区间估计方法,通常情况下,最大后验密度区间的长度较短,更符合实际情况。而等尾置信区间长度不一定短,所以相对来说不是最理想的。"
A:错 B:对
AI参考:判断题:卡方拟合优度检验最早用来解释孟德尔的遗传学说。(对)"
A:对 B:错
AI参考:答案是B:错。 u检验是一种假设检验方法,其拒绝域为给定的显著性水平下的区间。在这个问题中,样本求得的p值为0.1056,它表示在显著性水平为0.05的情况下,样本数据不拒绝原假设的概率。由于p值小于显著性水平,所以样本数据不能拒绝原假设,因此不能得出统计上的结论。因此,这个判断题是错误的。"
A:对 B:错
AI参考:正确答案是B:错。 正态均值的检验,常用的检验统计量为Z统计量,而非题目中的图片所示的图形。因此,该题表述错误。"
A:对 B:错
AI参考:答案是B:错。构造先验分布的常用方法是贝叶斯方法,它不需要使用共轭先验分布。共轭先验分布是贝叶斯分析中的一种技巧,主要用于简化后验分布的计算,但它并不是构造先验分布的常用方法。因此,这个说法是错误的。"
A:对 B:错
A:对 B:错
AI参考:答案是B:错。 根据题意,条件分布不依赖于参数,而统计量依赖于参数。因此,统计量不是充分统计量。充分统计量应该是独立于样本数据的参数,只依赖于样本数据本身。"
A:对 B:错
AI参考:这是一个判断题,答案是B:错。 根据题目描述,香烟中尼古丁含量的合格标准是不得超过1.5mg,而随机抽取一盒香烟,测得的平均每支香烟的尼古丁含量为1.3mg,低于合格标准,因此不能接受原假设,即认为尼古丁的含量不合格。因此,答案为B。"
A:对 B:错
AI参考:正确答案是B:错。统计量是无偏估计,但是它是其他随机变量的无偏估计不代表它本身就是无偏估计。所以本题判断错误。"
A:错 B:对
AI参考:答案是B:对。C-R不等式是相合估计的方差下界的一个重要不等式,因此该判断题是正确的。"
A:错 B:对
A:对 B:错
A:对 B:错
A:错 B:对
AI参考:正确答案是B:对。 贝叶斯可信区间是在给定数据和先验分布的情况下,通过贝叶斯定理来计算后验分布,进而得到可信区间。因此,贝叶斯可信区间使用的是先验分布,选项B正确。"
A:对 B:错
AI参考:正确答案是A:对。 在进行假设检验时,根据实际观测数据与理论值的比较结果,如果实际观测值落入拒绝域内,则拒绝原假设;反之,如果实际观测值落入接受域内,则接受原假设。根据题干中的图片信息可知,用值法进行假设检验时,若值,则接受原假设。因此,答案为A。"
A:对 B:错
AI参考:正确答案是B:错。 题目中给出的图像无法判断C-R方差下界的具体数值,因此无法得出结论。需要更多的信息才能得出准确的答案。"
A:对 B:错
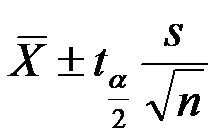
A:对 B:错
AI参考:答案是B:错。 题目中给出的信息不足以确定参数μ和σ的矩估计值。需要更多的样本数据和统计知识来估计参数的矩。因此,无法根据给定的图像信息得出正确答案。"
A:对 B:错
AI参考:这是一个关于统计中的区间估计问题。正态分布的方差是确定的,表示数据分布的离散程度。同等置信区间指的是两个估计区间在统计上具有相同的置信水平。由于正态分布的方差是一个确定的数值,所以正态分布的同等置信区间也是确定的。因此,答案是A:对。"
A:错 B:对
AI参考:B:对 根据题意,每克水泥混合物释放的热量X(卡路里)近似服从正态分布,且样本量为n=9。现在要检验一个假设,即水泥混合物的热量与样本量无关。根据正态分布和样本统计量的性质,当样本量n足够大时,样本均值会逐渐接近总体均值,因此样本量n的大小对水泥混合物的热量影响不大。 现在题干给出了两个样本均值的标准偏差值,分别为μ₁和μ₂。由于μ₁和μ₂都小于总体标准偏差值σ,因此根据正态分布的特点,μ₁和μ₂的差异更小,可以推断出μ₁更接近总体均值。因此,如果样本量为n=9,则可以拒绝原假设,认为水泥混合物的热量与样本量有关。 因此,本题答案为B:对。"
A:错 B:对
AI参考:正确答案是B:对。 样本观察值落在接受域内的概率称为接受概率或势函数。因此,答案为B。"
A:错 B:对
AI参考:根据贝叶斯定理,对于一个参数的后验分布,我们需要已知先验分布以及一个数据或信息来源。在给定的问题中,我们已经知道了参数的不合格品率的一个先验分布(β分布),同时也得到了从样本中得到的不合格品率的数据。根据贝叶斯定理,不合格品率的后验分布将会是这个样本不合格品率的信息被整合到先验分布的结果中。所以,答案是B:对。 这个问题的关键是理解贝叶斯定理的适用条件和步骤,需要用到一些概率论的知识。在回答时需要注意不要遗漏步骤和关键信息。"
A:对 B:错
A:错 B:对
AI参考:答案是B:对。 样本p分位数的计算公式为: Z_p = -1 + p*ln(1 - Φ(p)) 其中,Φ(p)是标准正态分布的累积分布函数,Φ是Φ(p)的简写。Z_p表示样本中第p百分位数对应的分数。 因此,样本p分位数的计算公式是正确的。"
A:错 B:对
A:错 B:对
AI参考:正确答案是B:对。 由于两样本均源自方差相等的正态总体,根据大样本理论可得,样本量越小,样本均值与总体均值越接近;样本量越大,样本均值与总体均值差距越大。由于本题考察直径大小,两样本样本量差距较小,样本均值差距较大,故而置信区间更可能偏向均值较小的样本,故样本均值的差异较样本方差的差异要小,则样本均值之间的差异估计更精确,可以接受α=0.95的置信区间为[-0.39, 0.49]。因此本题答案为B。"
A:对 B:错
AI参考:答案:B:错。 K-S检验是一种用来检验连续型随机变量是否服从某种理论分布的统计方法。其核心思想是通过比较样本累积概率分布与理论累积概率分布之间的差异来判断两个分布之间的相似性。在进行K-S检验时,需要构造统计量来度量这种差异,而在构造统计量时通常需要用到经验分布函数。但在K-S检验中,经验分布函数是用于描述样本数据的概率分布,而非构造统计量。因此,该表述错误。"
A:错 B:对
A:错 B:对
AI参考:答案:B 推理过程:因为已知假设中有不等于零的参数,此时要用双侧检验。此时,拒绝域为{W:U>d*}或{W:V>c*}(这里U、V分别为两个正态分布的标准差)。题中给出了W值和两个正态分布的标准差,可以计算出d*或c*的值,即可确定拒绝域。因此本题选B。 需要注意的是,在进行正态检验时,我们需要明确假设中的参数以及所使用的检验方法,并确定正确的拒绝域。同时,对于双侧检验和单侧检验的区别也需要加以注意。"


