北华大学
- 原始集set1中含有10个元素,由隐式方式可以定义为set1/1…10/. ( )
- 不联网时也可以安装库。 ( )
- ( ) Matlab中生成一个3阶方阵A,A(:,3) 表示取矩阵A的第3列.
- read_excel中的参数skiprows,用来指定要跳过的行索引组成的列表。( )
- 在Python中,discriminant_analysis是进行判别分析的模块。( )
- Lingo中对变量x取整数,使用函数@gin(x).( )
- ( ) Matlab中C=eye(3) 产生一个3阶的全1矩阵.
- pip命令也支持扩展名为.whl的文件直接安装Python扩展库。( )
- 派生集中的父集合不允许使用两个相同的原始集合. ( )
- Lingo中@free(x)表示取消对变量x的默认下界为0的限制,即x可以取任意实数.( )
- 6人接种流感疫苗一个月后测定抗体滴度为 1:20、1:40、1:80、1:80、1:160、1:320,求平均滴度应选用的指标是( )
- 下列函数中不能用于隐函数绘图的是( )。
- Matlab命令A=magic(3)创建一个3阶魔方矩阵,求A的特征值的绝对值的最小值用( ).
- 下四分位数(Q1),中位数(Q2),上四分位数(Q3),则四分位间距(IQR)为( )。
- Matlab中用赋值语句给定x的数据,计算
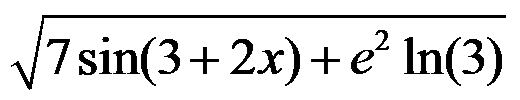 对应的matlab语句是( ).
对应的matlab语句是( ). - 查看二维数组df第4、6行,第1、2列的命令是( )。
- 图形窗口(Figure)显示网格的命令是( )
- 查看二维数组df中姓名为“张三”数据的命令是( )。
- 查看二维数组df的'姓名'和'交易额'列的命令是( )。
- 下列哪条指令是求矩阵的最大值( )。
- 计算乙肝疫苗接种后血清学检查的阳转率,分母为( )
- 下列Matlab命令中是构造3×1阶均值为0,方差为1的标准正态分布随机矩阵的命令的是( )
- 查看二维数组df中张三‘交易额’数据的命令是( )。
- 查看二维数组df第2行,2列单值的命令是( )。
- 查看二维数组df中交易额高于1700元数据的命令是( )。
- 两样本均数比较,检验结果
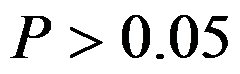 说明( )
说明( ) - 将二维数组df中交易额中存在缺失值的行删除,命令是( )。
- 将二维数组df中重复行直接删除的命令是( )。
- 假设检验的目的是( )
- 在图形指定位置加标注命令是( )
- 下列变量名中合法的是( )
- 查看二维数组df第2、5行的命令是( )。
- 如果矩阵A不是方阵,则下列Matlab命令中是求A的伪逆矩阵的命令是( )
- 利用pandas读取csv文件的命令是( )。
- 查看二维数组df的'姓名'列的命令是( )。
- Lingo中的逻辑运算符不包括( )
- 下列哪个函数为插值函数( )
- 显示二维数组df中重复行的命令是( )。
- 由两样本均数的差别推断两总体均数的差别, 其差别有统计学意义是指( )
- 将DataFrame写入到Excel文件的命令是( )。
A:对 B:错
答案:错
A:对 B:错
答案:对
A:错 B:对
答案:错
A:错 B:对
答案:对
A:对 B:错
答案:对
A:对 B:错
答案:对
A:错 B:对
答案:错
A:对 B:错
答案:对
A:对 B:错
答案:错
A:对 B:错
A:均数 B:几何均数
C:倒数的均数
D:百分位数
E:中位数
A:plot3
B:ezmesh C:ezplot D:ezsurf
A:
B:
C:
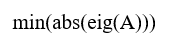
D:
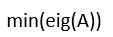
A:Q3-Q1
B:Q3-Q2
C:Q1-Q3
D:Q2-Q1
A:sqrt(7sin(3+2x)+exp(2)log(3))
B:sqrt(7*sin(3+2*x)+exp(2)*log(3)) C:sqr(7*sin(3+2*x)+exp(2)*log(3)) D:sqr(7sin(3+2x)+exp(2)log(3))
A:df[[3,5],[0,1]]
B:df.iloc[[4,6],[1,2]]
C:df.iloc[[3,5],[0,1]]
D:df[[4,6],[1,2]]
A:axis on B:hold on
C:grid on D:box on
A:df[df['姓名']='张三']
B:df[df['姓名']=='张三']
C:df['姓名']=='张三'
D:df['姓名']='张三'
A:df[['姓名','交易额']]
B:df[姓名,交易额]
C:df['姓名','交易额']
D:df[[姓名,交易额]]
A:inv B:diag C:eig
D:max
A:乙肝疫苗接种人数 B:平均人口数
C:乙肝患者人数
D:乙肝疫苗接种后的阳转人数
E:乙肝易感人数
A:ones(3) B:rand (3, 1) C:其他都不对
D:randn(3, 1)
A:df[df['姓名']=='张三']
B:df[df['姓名']='张三']['交易额']
C:df[df['姓名']='张三']
D:df[df['姓名']=='张三']['交易额']
A:df.iat[2,2]
B:df[1,1]
C:df.iat[1,1]
D:df[2,2]
A:df[df['交易额']>1700]
B:df['交易额']>=1700
C:df['交易额']>1700
D:df[df['交易额']>=1700]
A:不支持两总体有差别的结论
B:两总体均数的差别较小 C:可以确认两总体无差别
D:两总体均数的差别较大
E:支持两总体无差别的结论
A:df.fillna(subset=['交易额'])
B:df.dropna()
C:df.dropna(subset=['交易额'])
D:df.fillna()
A:df[df.duplicated()]
B:df[df.drop_duplicates()]
C:df.drop_duplicates()
D:df.duplicated()
A:检验样本统计量是否不同
B:检验样本的P值是否为小概率
C:检验样本统计量与总体参数是否不同 D:检验参数估计的准确度 E:检验总体参数是否不同
A:legend(x,y,’y=sin(x)’); %添加图例的标注,
B:title(x,y,’y=sin(x)’); C:text(x,y,’y=sin(x)’); D:xlabel(x,y,’y=sin(x)’);
A:
B:
C:
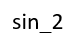
D:
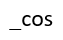
A:df[[2,5]]
B:df.iloc[[1,4]]
C:df[[1,4]]
D:df.iloc[[2,5]]
A:
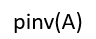
B:
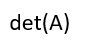
C:

D:
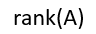
A:to_csv()
B:read_excel()
C:to_excel()
D:read_csv()
A:df[姓名]
B:df['姓名']
C:df.iloc[姓名]
D:df.iloc['姓名']
A:#>#
B:#ge#
C:#lt#
D:#and#
A:[Y,I]=sort(A,dim) B:P=polyfit(X,Y,3) C:R=corrcoef(X)
D:Y1=interp1(X,Y,X1,'method')
A:df[df.duplicated()]
B:df.duplicated()
C:df.drop_duplicates()
D:df[df.drop_duplicates()]
A:两样本均数的差别具有实际意义
B:两总体均数的差别具有实际意义
C:有理由认为两总体均数有差别
D:两样本和两总体均数的差别都具有实际意义
E:有理由认为两样本均数有差别
A:to_excel()
B:to_csv()
C:read_excel()
D:read_csv()
温馨提示支付 ¥5.00 元后可查看付费内容,请先翻页预览!
