- 机器学习方法由( )等几个要素构成。
- 关于剪枝,以下算法正确的是( )。
- 线性回归中,我们可以使用最小二乘法来求解系数,下列关于最小二乘法说法正确的是( )。

- 关于SVM的描述正确的是:( )
- 以下关于KNN说法正确的是( )。
- 传统机器学习的应用领域有( )。
- 降维的优点有哪些 ( )
- K-means是一种迭代算法,在其内部循环中重复执行以下两个步骤是( )。
- 机器学习的核心要素包括( )。
- 以下关于 PCA 说法正确的是 ( )
- 梯度下降法中,梯度要加一个负号的原因是( )。
- 我们想在大数据集上训练决策树, 为了使用较少时间, 我们可以( )。
- 机器学习方法传统上可以分为( )类。


- 分析顾客消费行业,以便有针对性的向其推荐感兴趣的服务,属于( )问题。
- 以下关于K-means算法错误的有 ( )
- 对于线性回归,我们应该有以下哪些假设 ( )(1)找到离群点很重要,因为线性回归对离群点很敏感;(2)线性回归要求所有变量必须符合正态分布;(3)线性回归假设数据没有多重线性相关性。
- 朴素贝叶斯是一种典型的基于概率的机器学习方法,它利用了( )
- SVM的效率依赖于( )。
- 下列不是 SVM 核函数的是( )
- 下面有关机器学习的认识正确的是( )。
- 下列选项中,关于KNN算法说法不正确是 ( )
- 以下关于逻辑回归与线性回归问题的描述错误的是( )。
- 下列关于朴素贝叶斯的特点说法错误的是( )
- 以下关于决策树特点分析的说法错误的有( )。
- KNN(K近邻算法)属于一种典型的( )算法
- 朴素贝叶斯分类器基于( )假设
- 下面关于回归分析的描述错误的是( )
- KNN 最近邻方法在( )情况下效果较好?
- 以下选择主成分数量的合理方法是(n是输入数据的维度m是输入示例的数量)( )
- 公司里有一个人穿了运动鞋,推测是男还是女?已知公司里男性30人,女性70人,男性穿运动鞋的有25人,穿拖鞋的有5人,女性穿运动鞋的有40人,穿高跟鞋的有30人。则以下哪项计算错误( )
- 假设会开车的本科生比例是15%,会开车的研究生比例是23%。若在某大学研究生占学生比例是20%,则会开车的学生是研究生的概率是( )
- 机器学习算法在图像识别领域的性能表现可能会超过人类。 ( )
- 支持向量机求解不可以采用梯度下降方法求解最优值。 ( )
- 决策树学习是一种逼近离散值目标函数的方法,学习到的函数被表示为一棵决策树。 ( )
- 根据肿瘤的体积、患者的年龄来判断良性或恶性,这是一个回归问题。 ( )
- SVD可用于求解矩阵的伪逆。 ( )
- Apriori算法是一种典型的关联规则挖掘算法。 ( )
- 梯度上升方法可以求解全局最大或者局部最大值。 ( )
- 在各类机器学习算法中,过拟合和欠拟合都是可以彻底避免的。 ( )
- 大部分的机器学习工程中,数据搜集、数据清洗、特征工程这三个步骤要花费大部分时间,而数据建模,占总时间比较少。 ( )
- K-Means聚类分析使用目标字段,预测某一结果。 ( )
- 逻辑回归和朴素贝叶斯都有对属性特征独立的要求。 ( )
- 梯度下降,就是沿着函数的梯度(导数)方向更新自变量,使得函数的取值越来越小,直至达到全局最小或者局部最小。 ( )
- 具有较高的支持度的项集具有较高的置信度。 ( )
- 朴素贝叶斯适用于小规模数据集,逻辑回归适用于大规模数据集。 ( )
- K均值算法,是一种原型聚类算法。 ( )
- K-Means方法是基于划分的聚类方法。 ( )
- 逻辑回归算法是一种广义的线性回归分析方法,它仅在线性回归算法的基础上,利用Sigmoid函数对事件发生的概率进行预测。 ( )。
- K均值是一种产生划分聚类的基于密度的聚类算法,簇的个数由算法自动地确定。 ( )
- 支持向量机是那些最接近决策平面的数据点。 ( )
- ID3 算法的核心思想就是以信息增益来度量特征选择,选择信息增益最大的特征进行分裂。 ( )
- 如果A为m阶实矩阵, ATA与AAT有相同的非零特征值集合。( )
- 如果A为m阶实矩阵,则ATA半正定。( )

- 设实矩阵A有SVD:A=UΣVT,则下列说法错误的是( )。
- 以下说法中错误的是( )。
- 假设将原矩阵降维到一维,采用的特征向量为,则映射后的结果为( )。
- 主成分分析是一个线性变化,就是把数据变换到一个新的坐标系统中。( )

- 下列关于主成分分析法(PCA)说法错误的是? ( )
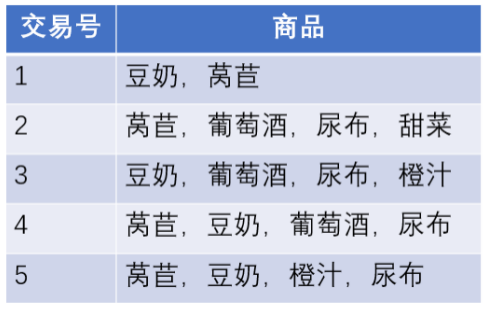
- 如果某个项集是频繁的,那么它的所有超集也是频繁的。( )


- 如果某个项集是频繁的,那么它的所有子集也是频繁的。( )
- 以下是一组用户的年龄数据,将K值定义为2对用户进行聚类。并随机选择16和22作为两个类别的初始质心,回答以下问题:[15,15, 16, 19, 19, 20, 20, 21, 22, 28, 35, 40, 41, 42, 43, 44, 60, 61, 65]第一次迭代结束后,样本20的分类为( )
- 以下是一组用户的年龄数据,将K值定义为2对用户进行聚类。并随机选择16和22作为两个类别的初始质心,回答以下问题:[15,15, 16, 19, 19, 20, 20, 21, 22, 28, 35, 40, 41, 42, 43, 44, 60, 61, 65]第一次迭代结束后,原质心16的类包含( )个样本。
- 以下是一组用户的年龄数据,将K值定义为2对用户进行聚类。并随机选择16和22作为两个类别的初始质心,回答以下问题:[15,15, 16, 19, 19, 20, 20, 21, 22, 28, 35, 40, 41, 42, 43, 44, 60, 61, 65]第一次迭代中,样本“15”到质心16的距离是( )
- 以下是一组用户的年龄数据,将K值定义为2对用户进行聚类。并随机选择16和22作为两个类别的初始质心,回答以下问题:[15,15, 16, 19, 19, 20, 20, 21, 22, 28, 35, 40, 41, 42, 43, 44, 60, 61, 65]第一次迭代结束后,原质心16更新后的质心是( )。
- 以下对经典K-means聚类算法解释正确的是 ( )


- 朴素贝叶斯的基本假设是属性之间是相互独立的。( )
- 朴素贝叶斯是概率模型。( )
- 下列选项中,对于硬间隔支持向量机,超平面应该是( )。
- 现有一个能被正确分类且远离超平面的样本,如果将其删除,不会影响超平面的选择。( )

- 下列选项中,对于软间隔支持向量机,超平面应该是( )。

- 下面对集成学习模型中的弱学习器描述错误的是?( )




- 关于决策树剪枝操作正确的描述是( )。
- 决策树模型中如何处理连续型属性( )。

- 决策树模型中建树的基本原则是( )。
- 哪些情况下必须停止树的增长( )
- 批量梯度下降是最原始的形式,它是指在每一次迭代时使用一部分样本的梯度来更新参数。( )
- 以下关于梯度下降算法说法正确的是( )。
- 小批量梯度下降是结合了批量梯度下降和随机梯度下降,性能比批量梯度下降和随机梯度下降都好。( )
- 随机梯度下降中每次迭代使用一个样本的梯度。( )
- 随机梯度下降导致方向变化过大,不能很快收敛到最优解。( )
- 考虑一个有两个属性的logistic回归问题。假设,则分类决策平面是( )。
- logistic回归只能用于二分类问题。( )
- logistic回归中也可以用正则化方法来防止过拟合。( )
- 假设训练了一个logistic回归分类器,对于一个样本我们有,则该式说明( )。
- 从某大学随机选择8名女大学生,其身高x(cm)和体重y(kg)的回归方程是 y=0.849x-85.712,则身高172cm的女大学生,预测体重为( )。
- 线性回归中加入正则化可以降低过拟合。( )
- 下列( )中两个变量之间的关系是线性的。
- lasso中采用的是L2正则化。( )
- K近邻算法中数据可以不做归一化,因为是否归一化对结果影响不大。( )
- K近邻算法中采用不同的距离公式对于结果没有影响。( )
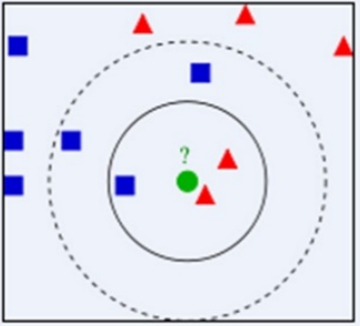
- K近邻算法认为距离越近的相似度越高。( )
- 在K近邻算法中,K的选择是( ) ?
- 机器学习算法需要显示编程,具备归纳、总结等自学习能力。( )
- 在机器学习中,样本常被分成( )。
- 机器学习和人工智能、深度学习是一个概念,都是指机器模仿人类推理、学习能力。( )
- 样本是连续型数据且有标签,我们采用( )进行机器学习。
- 特征工程非常重要,在采用机器学习算法前,首先需要利用特征工程确定样本属性。( )
答案:模型评估指标###损失函数###模型###优化算法
答案:剪枝是防止过拟合的手段###ID3算法没有剪枝操作###决策树剪枝的基本策略有预剪枝和后剪枝
答案:不需要迭代训练###不需要选择学习率###当特征值很多的时候,运算速率会很慢###只适用于线性模型,不适合逻辑回归模型等其他模型
答案:添加多项式特征(例如,使用)可以增加我们拟合训练数据的程度###在θ的最佳值处,(J是损失函数)
答案:支持向量机的学习策略就是间隔最大化###支持向量机模型定义在特征空间上的间隔最大的线性分类器###支持向量机可以通过核技巧,这使之成为实质上的非线性分类器
答案:对异常值不敏感###对数据没有假设###计算复杂度低
答案:销售预测###商品推荐###信用风险检测
答案:减小训练时间###方便消除冗余特征###方便实现数据可视化
答案:移动簇中心,更新簇中心。###分配簇,计算距离。
答案:算法###数据###算力
答案:PCA 转换后选择的第一个方向是最主要特征
温馨提示支付 ¥5.00 元后可查看付费内容,请先翻页预览!