第六章测试1.DIANA算法中,定义两个数据点之间的平均距离的为( )。
A:簇的直径 B:平均相异度 C:欧几里得距离 D:范式距离
答案:B
2.基于( )的聚类方法是基于距离判断数据对象相似度的聚类。
A:划分 B:层次 C:密度 D:网格 3.聚类质量评估的主要任务不包括( )
A:确定簇数 B:确定聚类质量 C:估计聚类趋势 D:确定层次结构 4.下面哪种距离度量方法为欧几里得距离( )。
A:
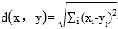 B:
B: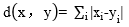 C:
C: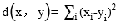 D:
D: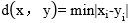 5.数据挖掘对聚类的典型要求包括( )。
5.数据挖掘对聚类的典型要求包括( )。A:处理噪声数据的能力 B:增量聚类和对输入次序不敏感 C:聚类高维数据的能力 D:可解释性和可用性 6.数据的哪些特性对聚类分析具有很强的影响( )。
A:高维性 B:规模 C:噪声和离群点 D:稀疏性 7.在聚类分析当中,簇内的相似性越大,簇间的差别越大,聚类的效果就越差。( )
A:错 B:对 8.基于密度的聚类方法可以发现任意形状的簇。( )
A:对 B:错 9.DBSCAN算法能够很好的区分原始数据的形状,但受限于用户指定的参数。( )
A:对 B:错 10.K-中心点算法采用簇中对象的平均值作为参考点。( )
A:对 B:错
温馨提示支付 ¥3.00 元后可查看付费内容,请先翻页预览!





