山东科技大学
- https://image.zhihuishu.com/zhs/onlineexam/ansewerImg/202211/d89920b9959948cdad951e5990fa3d1f.png
- 次梯度方法是传统的梯度下降方法的拓展,用来处理不可导的凸函数。它的优势是比传统方法处理问题范围大,劣势是算法收敛速度慢。( )
- 增大正则化系数可以用于处理欠拟合( )
- SVM分类超平面的解是唯一的,要满足间隔最大化。感知机的解不唯一,没有间隔最大化的约束条件,满足分开数据点的分界面都是可以的。( )
- 带模型假设的经验损失最小化算法架构,相比于无约束经验损失最小化算法架构更容易发生过拟合。( )
- 值迭代算法是在已知模型的基础上,用规划的方法进行策略评估策略改进,最终获得最优策略。( )
- 交叉熵损失函数适用于回归问题。( )
- DQN的回放记忆单元的目的是通过随机抽取交互数据,避免了数据相关性问题,数据满足独立同分布,算法易于收敛。( )
- 平方损失函数是凸函数,连续可导,因此容易优化。( )
- L2 正则化得到的解更加稀疏。( )
- BP算法容易陷入局部最优解。( )
- 马尔科夫性特点:未来与现在有关,下一个状态既和当前状态有关,又和之前的状态有关。( )
- 分段回归特征选择算法是一个迭代搜索算法,避免了采用贪心选择策略。( )
- 卷积神经网络在池化层丢失大量的信息,从而降低了空间 分辨率,导致了对于输入微小的变化,从而导致了其输出改变巨大。( )
- 线性降维方法包括主成分分析和局部线性嵌入方法。( )
- L1正则化方法和L2正则化方法都可以增加模型的平滑度,降低模型过度拟合的概率。( )
- 梯度下降法需要预先设定学习率,然后通过多次迭代求解最优参数。( )
- 主成分分析中可以利用( )求解主成分
- 以下输入梯度下降法的有:( )
- 以下关于结构损失最小化算法的说法哪个是正确的?( )
- 下列哪种方法可以用来减小过拟合?( )
- 以下关于监督式学习的说法哪个是正确的?( )
- 关于BP神经网络的缺点说法正确的是( )
- 以下关于聚类算法说法正确的是( )。
- 以下哪些算法基于动态规划的强化学习算法?( )
- 关于合并聚类算法说法正确的有( )。
- 强化学习包含哪些元素?( )
- Q-learning的缺点有哪些?( )
- 以下关于PCA和KPCA的对比,正确的有( )
- 降维的主要优点有哪些 ( )。
- 下面关于前馈神经网络的描述不正确的是( )
- ID3算法以( )作为测试属性的选择标准。
- 下列关于梯度下降(Gradient descent )法的描述错误的是 ( )
- 假设您有一个数据集,有100000个样本,每个样本有20000个特性。你想用多元线性回归来拟合参数
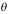 到我们的数据。你更应该用梯度下降还是正规方程?( )
到我们的数据。你更应该用梯度下降还是正规方程?( ) - 下列关于感知器算法的说法中错误的是( )
- 以下哪些方法不能用于处理过拟合?( )
- 线性回归方程y=-2x+7揭示了割草机的剩余油量(升)与工作时间(小时)的关系,以下关于斜率描述正确的是:( )。
- 线性回归经常使用的优化算法是( )
- 在回归分析中,下列哪个选项不属于线性回归( )。
- 以下(1)动态规划算法、(2)蒙特卡洛算法、(3)时序差分算法,无模型的算法有哪些?( )
- PCA的理论基础是( )
- K均值算法中的K指的是什么( )
- 回归问题和分类问题的区别是( )
- 下列哪个是自动编码器任务( )
- 关于K均值算法说法不正确的是( )。
- 下列说法错误的是?( )
- 下列选项中哪个不是正规方程的特点( )
- 决策树的构成顺序是?( )
- 下列关于长短期记忆网络LSTM和循环神经网络RNN的关系描述正确的是( )
- 假设有100张照片,其中,猫的照片有60张,狗的照片是40张。识别结果:TP=40,FN=20,FP=10,TN=30,则可以得到:( )。
- 下面有关 LDA的说法错误的是哪个( )
- 以下说法哪个是不正确的?( )
- 线性回归模型假设标签随机变量服从_______? Logistic回归模型假设标签随机变量服从_______? Softmax回归模型假设标签随机变量服从_______?( )
 ( )
( )- 下列哪一项在神经网络中引入了非线性?( )
- 下列说法正确的是( )
- 主成分分析是根据( )确定选取的主成分个数
- Logistic回归与多重线性回归比较( )
- 假定你使用SVM学习数据X,数据X里面有些点存在分类错误。现在如果你使用一个二次核函数,多项式阶数为2,使用松弛变量C作为超参之一,当你使用较大的C(C趋于无穷),则:( )
- .一元线性回归模型和多元线性回归模型的区别在于( )
答案:
A:错 B:对
答案:对
A:对 B:错
答案:错
A:对 B:错
答案:对
A:错 B:对
答案:错
A:错 B:对
答案:错
A:对 B:错
答案:对
A:对 B:错
答案:对
A:错 B:对
答案:对
A:错 B:对
A:错 B:对
A:对 B:错
A:错 B:对
A:错 B:对
A:错 B:对
A:对 B:错
A:对 B:错
A:Hessian矩阵 B:距离矩阵 C:相关系数矩阵 D:协方差矩阵
A:小批量梯度下降法 B:批量梯度下降法 C:丢弃法 D:随机梯度下降法
A:不会发生过渡拟合 B:带有正则化方法的经验损失最小化算法被称为结构损失最小化算法 C:任何经验损失最小化算法,都可以通过正则化方法转化成结构损失最小化算法 D:体现了奥卡姆剃刀法则思想
A:L1 正则化 B:L2 正则化 C:减小模型的复杂度 D:更多的训练数据
A:实际应用中,监督式学习使用的标签形式灵活多样 B:监督式学习往往需要事先标注大量的数据 C:监督式学习需要通过有标签的数据进行学习 D:监督式学习不需要标签就可以训练
A:随着神经网络的层数加深,训练过程存在严重的“梯度弥散” 现象,即网络的输出结果通过反向传播,当到达前面层时,梯度会逐渐消失,使得不能指引网络权值的训练,从而导致网络不能正常收敛。 B:BP神经网络的容错性较差。 C:BP神经网络以数值作为输入。在处理图像相关的信息时, 则要从图像中提前提取特征。 D:BP算法一般只能用于浅层网络结构的学习,限制了BP算法的数据表征能力,影响了在实际应用中的效果。
A:合并聚类算法是基于密度的聚类 B:K均值算法是一个近似算法 C:聚类分析是无监督学习算法 D:聚类目标是将数据集中的样本划分为若干个不相交的子集
A:值迭代算法 B:蒙特卡洛算法 C:策略迭代算法 D:梯度下降算法
A:合并聚类算法聚类时,先将每一个数据样本自成一类 B:类间距离定义为两类的中心之间的欧几里得距离 C:类中心定义为类中样本的最大值 D:合并聚类算法的思想类似于经典图算法中的Kruskal算法
A:Agent B:State C:Reward D:Action
A:不能对连续状态,进行查找。 B:存储开销大 C:查找Q值耗时长 D:需要存储并维护Q表,具有局限性
A:应用PCA算法前提是假设存在一个线性超平面,如果数据不是线性的,这时就需要用到KPCA B:PCA对坐标轴做了线性变换,而KPCA对坐标轴做了非线性变换 C:KPCA用到了核函数思想,计算量比PCA小 D:KPCA能比PCA提供更多的特征数目
A:可明显提高学习性能 B:方便消除冗余特征 C:方便实现数据可视化 D:减小训练时间
A:不能有隐藏层 B:是一种可以包含多层结构的网络 C:是一种单向计算网络 D:每一层可以包含多个神经元
A:分类的速度 B:信息增益 C:信息熵 D:所划分的类个数
A:通常会先初始化一组参数值,然后在这个值之上,用梯度下降法去求出下一组的值。由于是梯度下降的,所以损失函数 的值在下降。当迭代到一定程度,此时的参数取值即为要求得的值 B:梯度下降算法的学习速率是模型参数,而不是超参数 C:梯度下降是利用一阶的梯度信息找到代价函数局部最优解的一种方法 D:学习速率的选取很关键,如果学习速率取值过大,容易达不到极值点甚至会发散,学习速率太小容易导致收敛时间过长
A:梯度下降,因为它总是收敛到最优
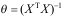 中计算非常慢
C:正规方程,因为它提供了一种直接求解的有效方法
D:正规方程,因为梯度下降可能无法找到最优
中计算非常慢
C:正规方程,因为它提供了一种直接求解的有效方法
D:正规方程,因为梯度下降可能无法找到最优A:在感知器算法中的学习率是可以改变的 B:在感知器算法中,如果样本不是线性可分的,则算法最后不会收敛 C:在感知器算法中可以通过调整学习率来减少迭代次数 D:感知器算法也适用于线性不可分的样本
A:对数据进行清洗 B:增大训练数据的量 C:利用正则化技术 D:增加数据特征的复杂度
A:割草机可以被预测到的油量是2升 B:割草机每工作1小时大约需要消耗7升油 C:割草机每工作1小时大约需要消耗2升油 D:割草机工作1小时后剩余油量是2升
A:A和B B:正规方程 C:最优值搜索 D:梯度下降法
A:多个因变量与多个自变量的回归 B:分段回归 C:多元线性回归 D:一元线性回归
A:(1),(2) B:全都不是 C:(1),(3) D:(2),(3)
A:成分最大理论 B:残差最大理论 C:方差最大理论 D:系数最大理论
A:样本大小 B:样本间距 C:属于某一类的数量 D:类别数量
A:回归问题与分类问题在输入特征值上要求不同 B:回归问题输出值是连续的,分类问题输出值是离散的 C:回归问题有标签,分类问题没有 D:回归问题输出值是离散的,分类问题输出值是连续的
A:降维或特征学习 B:计算参数 C:生成标签 D:训练网络
A:K均值算法是基于划分的聚类 B:K均值算法不适用于所有的聚类问题 C:当类中数据集构成凸集时,取得最差的效果 D:使用时需要预先确定聚类的类数
A:利用拉格朗日函数能解带约束的优化问题 B:进行 PCA 降维时,需要计算协方差矩阵 C:沿负梯度的方向一定是最优的方向 D:当目标函数是凸函数时,梯度下降算法的解一般就是全局最优解
A:需要迭代求解 B:一次运算得出 C:不需要选择学习率 D:时间复杂度高O(n3)
A:决策树生成、决策树剪枝、特征选择 B:特征选择、决策树生成、决策树剪枝 C:决策树剪枝、特征选择、决策树生成 D:特征选择、决策树剪枝、决策树生成
A:LSTM是RNN的扩展方法,通过特有结构设计来避免长期依赖问题 B:LSTM是简化版的RNN C:LSTM是多层的RNN D:LSTM是双向的 RNN
A:准确率=0.8 B:召回率=0.8 C:精确率=0.8 D:ABC都不对
A:LDA中线性变换可以使投影后类内方差最大,类间方差最小。 B:LDA属于监督式学习算法。 C:LDA是一种结合类别标签的信息对数据样本特征进行降维的算法。 D:LDA除了可以用于降维,还可以用于分类。
A:Logistic回归模型适用于求解二元分类问题,Softmax回归模型是Logistic模型的推广,它适用于求解
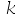 元分类问题。
B:k元分类问题中,监督式学习模型预测的是给定的对象属于每一个类的概率,预测模型输出的是k个概率值。
C:k元交叉熵是一个凸函数,可以用梯度下降算法来优化Softmax回归算法。
D:Softmax回归算法是一个以sigmoid函数为模型假设,且以log对数损失函数为目标函数的经验损失最小化算法。
元分类问题。
B:k元分类问题中,监督式学习模型预测的是给定的对象属于每一个类的概率,预测模型输出的是k个概率值。
C:k元交叉熵是一个凸函数,可以用梯度下降算法来优化Softmax回归算法。
D:Softmax回归算法是一个以sigmoid函数为模型假设,且以log对数损失函数为目标函数的经验损失最小化算法。
A:伯努利分布、正态分布、多项分布 B:伯努利分布、多项分布、正态分布 C:正态分布、伯努利分布、多项分布 D:正态分布、多项分布、伯努利分布
A:
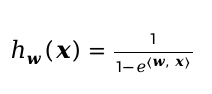 B:
B:
 C:
C: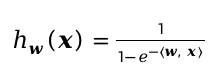 D:
D:
A:修正线性单元(ReLU) B:卷积结构 C:批量梯度下降 D:ABC都不正确
A:通过添加其他特征项可以解决欠拟合的问题 B:正规方程不能使回归算法更加优化 C:根据肿瘤特征判断良性还是恶性是回归问题 D:对数据正则化可以解决欠拟合的问题
A:因子载荷 B:误判率 C:累计贡献率 D:最短距离
A:Logistic回归和多重线性回归的因变量都可为二分类变量 B:Logistic回归的自变量必须是二分类变量 C:logistic回归的因变量为二分类变量 D:多重线性回归的因变量为二分类变量
A:不确定 B:不能正确分类 C:ABC均不正确 D:仍然能正确分类数据
A:自变量的个数不同 B:判定系数的大小不同 C:因变量的个数不同 D:相关系数的大小不同
温馨提示支付 ¥5.00 元后可查看付费内容,请先翻页预览!



