北京航空航天大学
- 贝叶斯网络可对任意属性关系进行建模。( )
- K近邻分类器的分类方法是选择k个近邻中样本个数最少的类。( )。
- 对于ISODATA算法,其聚类结果唯一。( )
- 条件熵H(Y|X)表示在已知随机变量X的条件下随机变量Y的不确定性。( )
- 半朴素贝叶斯分类器的SPODE方法假设存在超父属性,可将该属性视为超参数进行调整。( )
- 最小风险贝叶斯决策通过计算期望风险进行分类时,无需计算后验概率。( )
- 如果向量能够确认类别,则本身的观察所提供信息量最大,熵也最大。( )
- 剪枝表示将一个节点拆分成多个子集的过程。( )
- 半朴素贝叶斯分类器要求每个属性在类别之外至少依赖于一个其他属性。( )
- 单层感知机无法解决异或问题,而多层感知机能解决异或问题。( )
- 当训练样本不足时,可以采用迁移学习的方式。通过迁移学习将已学到的模型参数通过某种方式分享给新模型,从而加快并优化模型的学习效率。( )
- 决策树方法利用一定的训练样本,从数据中“学习”出决策规则,自动构造决策树,并利用决策树实现分类。( )
- 有监督模式识别可以减少数据标记的工作量,同时又能带来比较好的准确率。( )
- 过拟合可以通过某些措施来避免( )
- AUC值是P-R曲线下的面积。( )
- Boosting方法是按照一定的顺序来训练不同的基模型,每个模型都针对前序模型的错误进行专门训练,从而增加不同基模型之间的差异性。( )
- 贝叶斯决策将样本的类别视为随机事件,将样本的特征向量视为随机变量。( )
- 信息增益会偏向取值较多的特征( )
- 对于规范化的增广样本集,
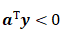 表示样本正确分类( )
表示样本正确分类( ) - 分类器集成应该做到“好而不同”( )
- 惩罚参数C>0,C值大时对误分类的惩罚减小,相反则增大。( )
- ID3算法的核心是( )
- 下面有关ISODATA算法,描述正确的是( )
- 神经网络模型中,提高模型复杂度的方法( )
- 以下说法正确的是( )
- 下面哪些是最小平方误差准则分类器的特点?( )
- 以下哪种是启发式搜索方式( )。
- 下面关于自组织竞争神经网络,说法错误的是( )
- 如何将多个弱分类器的结果集成起来( )
- 二叉树算法有哪些特点?( )
- K近邻分类器的K值越大,则下面哪些叙述正确?( )。
- 随机森林的缺点包括( )
- 设计一个模式识别系统时,主要的工作包括( )。
- 以下哪种是流形学习方法( )。
- 决策树的构建主要包括( )
- 以下关于池化层说法正确的是( )
- 分类器集成的主要方法包括( )
- 信息增益存在的问题包括( )
- ID3算法采用( )作为节点划分标准。
- 下面哪个操作对应了线性可分性样本集的规范化?( )
- DBSCAN聚类算法中,边界点的判定条件为( )
- 以下关于神经网络中的神经元,说法正确的是( )
- 自组织神经网络与BP网络不同之处是( )
- C4.5算法采用( )作为节点划分标准。
- 假设C为类别数,D为特征维数,则C>2,D=3表示( )
- “软间隔”允许部分样本不满足如下哪个条件( )
- CART算法采用( )作为节点划分标准。
- K均值聚类算法中,采用的相似性测度是 ( )
- 以下关于感知机,说法正确的是( )
- 朴素贝叶斯算法的前提是数据集中( )。
- P-R曲线的平衡点是指( )
- 以下多分类算法的描述中,错误的是?( )
A:错 B:对
答案:对
A:错 B:对
答案:错
A:对 B:错
答案:错
A:错 B:对
答案:对
A:对 B:错
答案:对
A:错 B:对
答案:错
A:错 B:对
答案:错
A:错 B:对
答案:错
A:对 B:错
答案:错
A:对 B:错
A:对 B:错
A:错 B:对
A:错 B:对
A:对 B:错
A:错 B:对
A:对 B:错
A:错 B:对
A:错 B:对
A:对 B:错
A:错 B:对
A:对 B:错
A:选择划分后信息增益大的作为划分特征,则使用该特征后划分得到的子集纯度更高,即不确定性更小 B:选择当前使得信息增益最大的特征来划分数据集 C:选择当前使得信息熵最大的特征来划分数据集 D:选择划分后信息增益大的作为划分特征,则使用该特征后划分得到的子集纯度更高,即不确定性更大
A:初始聚类中心选择会影响最终聚类结果 B:属于基于层次的聚类方法 C:属于动态聚类方法 D:通过聚类合并和分裂操作,实现聚类数量动态调整
A:增加输出层神经元的数量 B:增加隐含层神经元的数量 C:增加隐含层的层数 D:增加输入层神经元的数量
A:人工智能是模式识别的一个分支 B:模式识别研究的内容比人工智能更加广泛 C:模式识别是人工智能的一个分支 D:人工智能研究的内容比模式识别更加广泛
A:存在闭式解 B:与最小距离分类器等价 C:解决的是两类分类问题 D:样本集不限,可以是线性不可分的
A:分支定界算法 B:SBS C:遗传算法 D:模拟退火算法
A:对获胜神经元及其邻域进行权值调整 B:属于无监督学习 C:竞争层(输出层)神经元个数可任意设置 D:采用WTA竞争学习策略
A:使用学习法 B:采用投票法 C:使用平均值 D:使用加权平均
A:分类器设计简单 B:第一个权向量影响后续所有权向量 C:可以解决两类多峰问题 D:二叉树各节点(分段)可以优化设计
A:模型丢失信息越多 B:模型能更好抵抗噪声 C:模型泛化能力越小 D:模型变得简单
A:对于分类工作表现得很好,但是对于回归问题则表现一般 B:构建过程难以有效控制,只能通过尝试不同的参数来调整,可解释性差 C:不能较好的处理缺省值问题 D:需要对数据进行降维才能获得较好的效果
A:分类器设计 B:特征选择 C:特征提取 D:系统的性能评估
A:等度量映射 B:局部线性嵌入 C:PCA D:LDA
A:节点拆分 B:剪枝 C:决策树生成 D:特征选择
A:池化层的作用是对卷积层中提取的特征进行挑选,使模型更关注是否存在某些特征而不是特征的具体位置。 B:池化是降采样过程,可以减少计算量。 C:最大池化操作需要模型参数,反向传播过程中需要进行权值优化 D:池化可以提高后续特征的感受野
A:Boosting方法 B:Bagging方法 C:随机森林 D:AdaBoost
A:在分类问题困难时,也就是说在训练数据集经验熵大的时候,信息增益值会偏大,反之信息增益值会偏小 B:信息增益会偏向取值较多的特征 C:信息增益会偏向取值较少的特征 D:信息增益值的大小相对于训练数据集而言的,并没有绝对意义
A:信息增益比 B:信息熵 C:基尼指数 D:信息增益
A:负类样本的增广向量全部减1 B:负类样本的增广向量全部乘以-1 C:正类样本的增广向量全部乘以-1 D:正类样本的增广向量全部减1
A:该点在其半径 Eps 邻域内含有点的数量小于 MinPts,但是该对象落在核心点的Eps邻域内 B:无正确答案 C:该点在其半径 Eps 邻域内含有点的数量小于 MinPts,但是该对象不落在核心点的Eps邻域内 D:该点在其半径 Eps 内含有超过 MinPts 数目的点
A:每个神经元可以有多个输入和多个输出 B:其他选项的表述均正确 C:每个神经元可以有多个输入和单个输出 D:每个神经元可以有单个输入和单个输出
A:用于分类 B:包含输入层和输出层 C:输入层神经元个数与输入数据的维度有关 D:无监督学习网络
A:信息增益 B:信息增益比 C:信息熵 D:基尼指数
A:二维空间中的多分类问题 B:二维空间中的二分类 C:三维空间中的二分类 D:三维空间中的多分类问题
A:
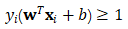 B:
B: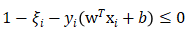 C:
C: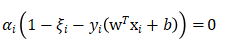 D:
D: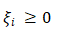
A:信息增益 B:信息增益比 C:信息熵 D:基尼指数
A:相关性测度 B:马氏距离 C:欧氏距离 D:明氏距离
A:解决线性可分的分类问题,求解结果不唯一 B:解决线性可分的分类问题,求解结果唯一 C:解决线性不可分的分类问题,求解结果不唯一 D:解决线性不可分的分类问题,求解结果唯一
A:各特征之间互相对立 B:各特征之间互相关联 C:各特征之间互相依赖 D:各特征之间互相独立
A:准确率等于召回率时的取值点 B:精确率等于召回率时的取值点 C:真正率等于真负率时的取值点 D:敏感性等于特异性时的取值点
A:设类别数为c,则有向无环图法在训练和识别阶段均需要调用c(c-1)/2个二分类模型 B:一对多法在类别数较大时,可能出现类别不平衡问题 C:一对一法不适合类别较多场景 D:一对一、一对多、有向无环图三种方式都可以用于解决多分类问题
温馨提示支付 ¥5.00 元后可查看付费内容,请先翻页预览!

