安徽财经大学
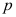 值越小说明拒绝原假设的可能性越大。 ( )
值越小说明拒绝原假设的可能性越大。 ( )- 若
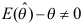 ,则称
,则称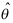 为
为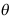 的渐近无偏估计量. ( )
的渐近无偏估计量. ( ) - 在试验设计中,把要考虑的那些可以控制的条件称为因子,把因素变化的多个等级状态称为水平或处理。 ( )
- 设曲线函数形式为
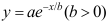 ,能找到一个变换将之化为一元线性回归的形式。 ( )
,能找到一个变换将之化为一元线性回归的形式。 ( ) - 多项研究表明,司机驾车时因接打手机而发生事故的比例超过
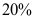 ,用来检验这一结论的原假设和备择假设为
,用来检验这一结论的原假设和备择假设为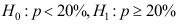 。 ( )
。 ( ) - 设总体
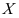 的期望
的期望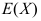 和方差
和方差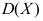 均存在,
均存在,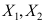 是
是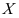 的一个样本,则统计量
的一个样本,则统计量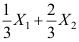 是
是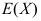 的无偏估计量 ( )
的无偏估计量 ( ) - 费希尔信息量总是存在的 ( )
- 为检验
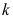 个总体均值是否显著不同,也可以用
个总体均值是否显著不同,也可以用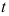 检验,且与方差分析相比,犯第一类错误的概率不变。 ( )
检验,且与方差分析相比,犯第一类错误的概率不变。 ( ) - 对
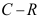 正则族,一致最小方差无偏估计一定是有效估计。 ( )
正则族,一致最小方差无偏估计一定是有效估计。 ( ) - 总体分布为正态分布情形下,若样本为小样本,且总体方差未知, 关于均值的假设检验适合使用用
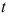 检验统计量。 ( )
检验统计量。 ( ) - 设
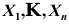 是来自参数为
是来自参数为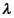 的泊松总体的样本,其均值、方差分别为
的泊松总体的样本,其均值、方差分别为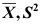 ,则
,则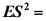 ( )
( ) - 设
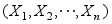 为总体N(1, 22)的一个样本,
为总体N(1, 22)的一个样本,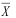 为样本均值,则下列结论中正确的是( )
为样本均值,则下列结论中正确的是( ) - 对一元线性回归方程进行检验时,令
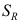 表示回归平方和,令
表示回归平方和,令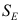 表示残差平方和,
表示残差平方和, 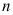 为样本容量, 检验回归方程显著时使用的检验统计量为( )
为样本容量, 检验回归方程显著时使用的检验统计量为( ) - 设总体
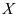 的分布函数为
的分布函数为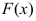 ,从中获得的样本观测值为
,从中获得的样本观测值为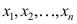 ,将他们从小到大排列重新编号为
,将他们从小到大排列重新编号为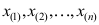 ,则当
,则当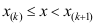 时,样本的经验分布函数
时,样本的经验分布函数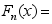 ( )
( ) - 设总体 X ~ N(,2),其中
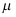 已知,
已知,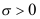 未知,
未知, 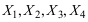 是
是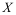 的样本,则下列各项不是统计量的是( )
的样本,则下列各项不是统计量的是( ) - 设一批零件的长度服从正态分布
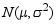 ,其中
,其中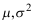 均未知. 现从中随机抽取16个零件,测得样本均值
均未知. 现从中随机抽取16个零件,测得样本均值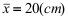 ,样本标准差
,样本标准差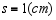 ,则
,则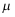 的置信度为0.90的置信区间是 ( )
的置信度为0.90的置信区间是 ( ) - 设
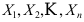 为来自正态总体
为来自正态总体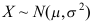 的样本,
的样本,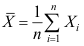 为样本平均,则
为样本平均,则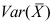 =( )
=( ) - 设
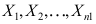 来自正态总体
来自正态总体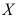 ,
,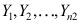 来自正态总体
来自正态总体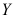 ,且
,且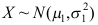 ,
,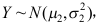
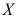 与
与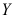 相互独立。令
相互独立。令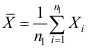 ,
,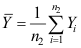 ,
, 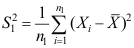 ,
, 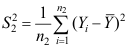 ,则以下结论中错误的是( )
,则以下结论中错误的是( ) - 矿沙中铜含量服从正态分布
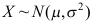 ,
,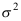 已知,现从总体中抽取样本
已知,现从总体中抽取样本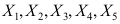 ,在显著性水平
,在显著性水平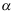 下检验
下检验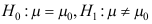 ,取统计量( )
,取统计量( ) - 设
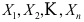 为来自正态总体
为来自正态总体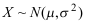 的样本,令
的样本,令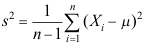 ,则
,则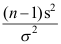 服从卡方分布,其自由度为( )
服从卡方分布,其自由度为( ) - 对于非正态总体(方差未知),在大样本条件下,总体均值在
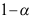 置信水平下的置信区间可以写为( )
置信水平下的置信区间可以写为( ) - 设总体
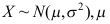 未知,
未知,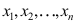 为来自总体
为来自总体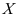 样本观测值,记
样本观测值,记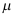 为样本均值,
为样本均值,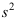 为样本方差,对假设检验
为样本方差,对假设检验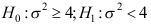 应取检验统计量为( )
应取检验统计量为( ) - 设
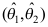 是参数
是参数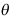 的置信水平为
的置信水平为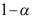 的区间估计,则以下结论正确的是( )
的区间估计,则以下结论正确的是( ) - 在线性模型
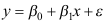 的相关性检验中,如果不能拒绝原假设
的相关性检验中,如果不能拒绝原假设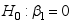 ,则表示( )
,则表示( ) - 设总体
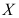 的分布函数为
的分布函数为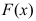 ,从中获得的样本为
,从中获得的样本为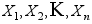 ,样本的经验分布函数为
,样本的经验分布函数为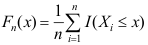 , 对于给定的x, 则
, 对于给定的x, 则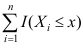 服从的分布是( )
服从的分布是( ) - 设总体
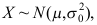
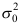 已知,
已知,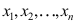 为来自总体
为来自总体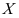 样本观测值,假设检验
样本观测值,假设检验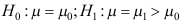 ,则当检验水平为
,则当检验水平为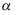 时犯第二类错误的概率为( )
时犯第二类错误的概率为( ) - 从
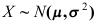 中抽取容量为
中抽取容量为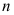 的样本,样本均值为
的样本,样本均值为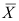 ,样本方差为
,样本方差为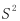 。在
。在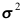 已知的条件下,
已知的条件下,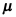 的置信水平为
的置信水平为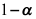 的单侧置信下限为( )
的单侧置信下限为( ) - 设总体
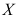 服从正态分布
服从正态分布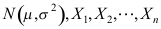 是来自
是来自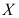 的样本,则
的样本,则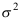 的最大似然估计为( )
的最大似然估计为( ) - 设
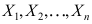 是来自总体X的样本,
是来自总体X的样本,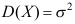 存在,
存在,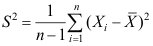 ,则( )
,则( ) - 与标准正态分布相比,t分布的特点是( )
- 在单因子4水平的方差分析中, 检验的原假设是( )
- 总体均值的区间估计中,正确的是( )
- 设总体
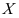 的密度函数为
的密度函数为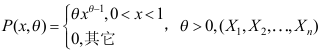 为样本,记
为样本,记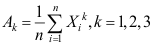 ,则以下结论中错误的是( )
,则以下结论中错误的是( ) - 若
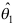 与
与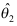 均是参数
均是参数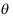 的无偏估计,则下列哪一个也是
的无偏估计,则下列哪一个也是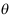 的无偏估计( )
的无偏估计( ) - 在假设检验中,显著性水平
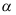 的意义是( )
的意义是( ) - 设样本
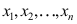 来自正态总体
来自正态总体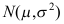 ,
,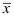 与
与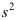 分别是样本均值和样本方差,则下面结论不正确的是( )
分别是样本均值和样本方差,则下面结论不正确的是( ) - 设总体
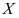 的分布函数为
的分布函数为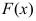 ,从中获得的样本为
,从中获得的样本为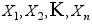 ,样本的经验分布函数为
,样本的经验分布函数为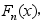 则
则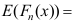 ( )
( ) - 设
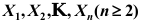 为来自总体N(0,1)的简单随机样本,
为来自总体N(0,1)的简单随机样本,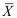 为样本均值,
为样本均值,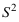 为样本方差,则( )
为样本方差,则( ) - 设总体
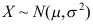 ,
,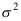 未知,现从总体中抽取容量为
未知,现从总体中抽取容量为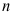 的样本,
的样本,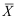 及
及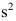 分别为样本均值和样本方差,则
分别为样本均值和样本方差,则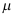 的置信度为
的置信度为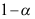 的置信区间为( )
的置信区间为( ) - 从两个总体中分别抽取
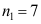 和
和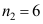 的两个独立随机样本。经过计算得到下面的方差分析表:
的两个独立随机样本。经过计算得到下面的方差分析表:
来源 平方和 自由度 均方和 F比 显著性 组间 7.50 1 7.50 a 4.84 组内 26.19 11 2.38 总计 12
表中a处单元格内的结果是( ) (小数点后保留两位有效数字) - 假设
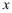 与
与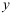 之间存在线性关系如下:回归方程
之间存在线性关系如下:回归方程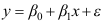 ,给定
,给定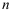 组数据
组数据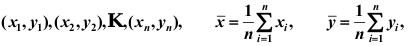

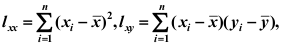 ,则回归系数
,则回归系数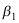 的估计值
的估计值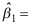 ( )
( ) - 设
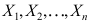 是来自总体
是来自总体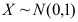 的样本,
的样本,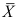 ,
,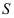 分别是样本均值和样本标准差,则( )
分别是样本均值和样本标准差,则( ) - 样本
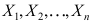 取自总体
取自总体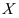 ,
,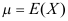 ,
, ,则以下结论不成立的是( )
,则以下结论不成立的是( ) - 设 .w65121255227s .brush0 { fill: rgb(255,255,255); } .w65121255227s .pen0 { stroke: rgb(0,0,0); stroke-width: 1; stroke-linejoin: round; } .w65121255227s .font0 { font-size: 262px; font-family: "Times New Roman", serif; } .w65121255227s .font1 { font-size: 406px; font-family: "Times New Roman", serif; } .w65121255227s .font2 { font-style: italic; font-size: 406px; font-family: "Times New Roman", serif; } .w65121255227s .font3 { font-weight: bold; font-size: 76px; font-family: System, sans-serif; } 4 3 2 1 , , , X X X X 是来自总体 .w65121255216s .brush0 { fill: rgb(255,255,255); } .w65121255216s .pen0 { stroke: rgb(0,0,0); stroke-width: 1; stroke-linejoin: round; } .w65121255216s .font0 { font-size: 406px; font-family: "Times New Roman", serif; } .w65121255216s .font1 { font-style: italic; font-size: 406px; font-family: "Times New Roman", serif; } .w65121255216s .font2 { font-weight: bold; font-size: 76px; font-family: System, sans-serif; } ) 1 , 0 ( ~ N X 的一个简单随机样本,则统计量 .w65121255204s .brush0 { fill: rgb(255,255,255); } .w65121255204s .pen0 { stroke: rgb(0,0,0); stroke-width: 1; stroke-linejoin: round; } .w65121255204s .pen1 { stroke: rgb(0,0,0); stroke-width: 16; stroke-linejoin: round; } .w65121255204s .font0 { font-size: 262px; font-family: "Times New Roman", serif; } .w65121255204s .font1 { font-style: italic; font-size: 406px; font-family: "Times New Roman", serif; } .w65121255204s .font2 { font-size: 373px; font-family: Symbol, serif; } .w65121255204s .font3 { font-weight: bold; font-size: 76px; font-family: System, sans-serif; } 2 4 2 3 2 2 2 1 X X X X + + 服从的分布是( )
- 设
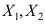 是来自正态总体
是来自正态总体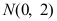 的样本,令
的样本,令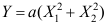 ,则当
,则当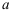 =( )时,统计量
=( )时,统计量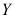 服从
服从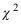 分布。
分布。 - 单因素方差分析中, 因子有r个水平, 样本容量为n, 则F统计量的分子与分母的自由度各为( )
- 在假设检验中,如果原假设
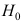 的否定域是
的否定域是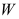 ,那么样本观测值
,那么样本观测值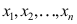 只可能有下列四种情况,其中拒绝
只可能有下列四种情况,其中拒绝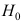 且不犯错误的是( )
且不犯错误的是( ) - 设总体
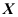 的概率密度为
的概率密度为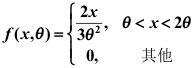
其中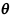 为未知的参数,
为未知的参数,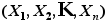 为取自总体的简单随机样本,若
为取自总体的简单随机样本,若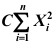 是
是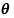 的无偏估计,则常数
的无偏估计,则常数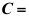 ( )
( ) - 设容量为16人的简单随机样本,平均完成工作所需时间为13分钟,总体服从正态分布且标准差为3,若想对完成工作所需时间构造一个90%的置信区间,则( )
- 在假设检验中,一般情况下( )
A:错 B:对
答案:对
A:错 B:对
答案:错
A:错 B:对
答案:对
A:错 B:对
答案:对
A:错 B:对
答案:错
A:错 B:对
答案:对
A:错 B:对
答案:对
A:对 B:错
答案:错
A:错 B:对
答案:错
A:对 B:错
A:
 B:
B:
A:
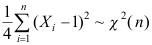 B:
B: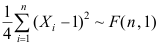 C:
C: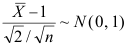 D:
D: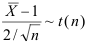
A:
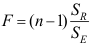 B:
B: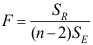 C:
C: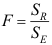 D:
D: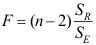
A:
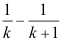
A:
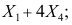 C:
C: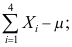
A:
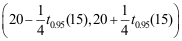 B:
B: C:
C: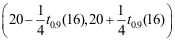 D:
D: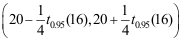
A:
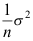 B:
B: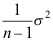 C:
C: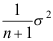 D:
D: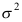
A:
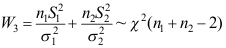 B:
B: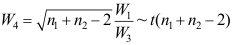 C:
C: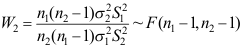 D:
D: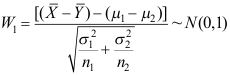
A:
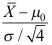 B:
B: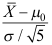 C:
C: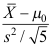 D:
D:
A:n-1 B:n C:1 D:n-2
A:
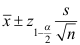 B:
B: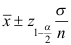 C:
C: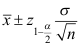 D:
D: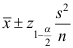
A:
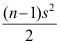 B:
B: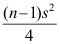 C:
C: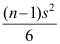 D:
D: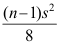
A:参数
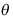 落在区间
落在区间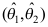 之内的概率为
之内的概率为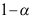 B:区间
B:区间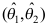 包含参数
包含参数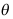 的概率为
的概率为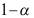 C:参数
C:参数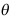 落在区间
落在区间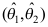 之外的概率为
之外的概率为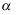 D:对不同的样本观测值,区间
D:对不同的样本观测值,区间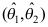 的长度相同
的长度相同
A:
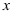 与
与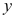 两个变量之间没有显著的非线性相关关系
B:
两个变量之间没有显著的非线性相关关系
B: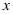 与
与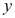 两个变量之间有显著的非线性相关关系
C:
两个变量之间有显著的非线性相关关系
C: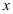 与
与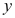 两个变量之间有显著的线性相关关系
D:
两个变量之间有显著的线性相关关系
D: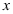 与
与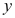 两个变量之间没有显著的线性相关关系
两个变量之间没有显著的线性相关关系
A:
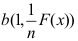 B:
B: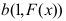 C:
C: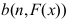 D:
D: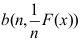
A:
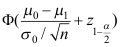 B:
B: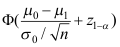 C:
C: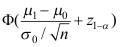 D:
D: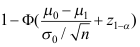
A:
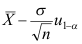 B:
B: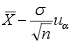 C:
C: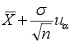 D:
D: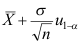
A:
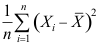 B:
B: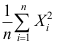 C:
C: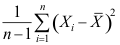
A:
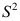 是
是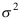 的矩估计
B:
的矩估计
B: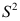 是
是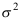 的极大似然估计
C:
的极大似然估计
C: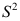 作为
作为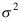 的估计其优良性与分布有关
D:
的估计其优良性与分布有关
D: 是
是 的无偏估计和相合估计
的无偏估计和相合估计
A:更加集中 B:对称分布 C:更加平坦分散 D:非对称分布
A:
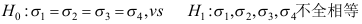 B:
B: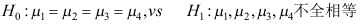 C:
C: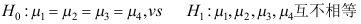 D:
D: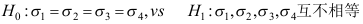
A:置信度
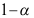 减少,则置信区间长度变短
B:置信度
减少,则置信区间长度变短
B:置信度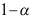 增加,则置信区间长度变短
C:置信度
增加,则置信区间长度变短
C:置信度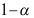 一定时,样本容量增加,则置信区间长度变短
D:置信度
一定时,样本容量增加,则置信区间长度变短
D:置信度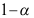 一定时,样本容量增加,则置信区间长度变长
一定时,样本容量增加,则置信区间长度变长
A:
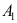 是
是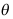 的矩估计量
B:
的矩估计量
B: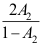 是
是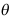 的矩估计量
C:
的矩估计量
C: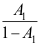 是
是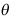 的矩估计量
D:
的矩估计量
D: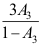 是
是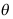 的矩估计量
的矩估计量
A:
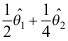 B:
B: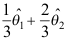 C:
C: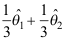 D:
D: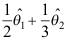
A:原假设
A:
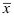 与
与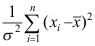 相互独立
B:
相互独立
B: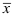 与
与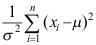 相互独立
C:
相互独立
C: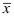 与
与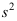 相互独立
D:
相互独立
D: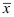 与
与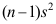 相互独立
相互独立
A:
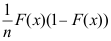 B:
B: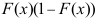 D:
D: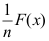
A:
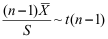 B:
B: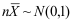 C:
C: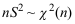 D:
D: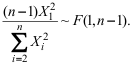
A:
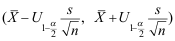 B:
B: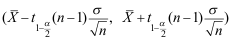 C:
C: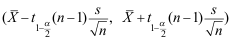 D:
D: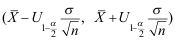
A:3.15 B:5.15 C:4.15 D:2.15
A:
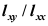 B:
B: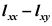 C:
C: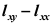 D:
D: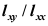
A:
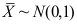 B:
B: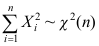 C:
C: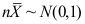 D:
D: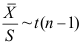
A:
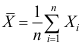 是
是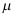 的无偏估计
B:
的无偏估计
B: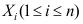 均是
均是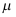 的无偏估计
C:
的无偏估计
C: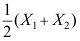 是
是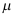 的无偏估计
D:
的无偏估计
D: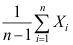 是
是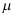 的无偏估计
的无偏估计
A: B: C: D:
A:
 B:
B:A:n-r, r-1 B:r, n C:r-1, n-r D:r-n, n-r
A:
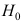 成立,
成立,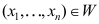 B:
B: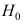 不成立,
不成立,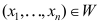 C:
C: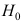 成立,
成立,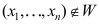 D:
D: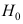 不成立,
不成立,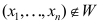
A:
A:应用标准正态概率表查出
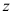 值
B:应用二项分布表查出
值
B:应用二项分布表查出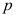 值
C:应用泊松分布表查出
值
C:应用泊松分布表查出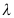 值
D:应用
值
D:应用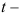 分布表查出
分布表查出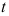 值
值
A:既不犯第一类错误,又不犯第二类错误 B:可能犯第一类错误,也可能犯第二类错误 C:只犯第一类错误 D:只犯第二类错误
温馨提示支付 ¥5.00 元后可查看付费内容,请先翻页预览!





