长春职业技术学院
- 二叉树中任何一个结点的度都是2。( )
- 二叉排序树的任意一棵子树中,关键字最小的结点必无左孩子,关键字最大的结点必无右孩子。( )
- 顺序存储方式只能用于存储线性结构。( )
- 数据结构中,在栈满情况下不能做进栈操作。( )
- 在无向图中,(V1,V2)与(V2,V1)是两条不同的边。( )
- 图可以没有边,但不能没有顶点。( )
- 有向图是一种非线性结构。( )
- 非空线性表中任意一个数据元素都有且仅有一个直接前驱元素。( )
- 如果两个串含有相同的字符,则说明它们相等。( )
- 完全二叉树的某结点若无左孩子,则它必是叶结点。( )
- 在线性表的顺序存储结构中,逻辑上相邻的两个元素但是在物理位置上不一定是相邻的。( )
- 在二叉排序树中,根结点的值都小于孩子结点的值。( )
- 哈希表的查找不用进行关键字的比较。( )
- 栈一定是顺序存储的线性结构。( )
- 完全二叉树就是满二叉树。( )
- 一个有向图的邻接矩阵一定是一个非对称矩阵。( )
- 二分查找法要求待查表的关键字值必须有序。( )
- 算法一定要有输入和输出。( )
- 图的生成树是惟一的。( )
- 顺序表和一维数组一样,可按下标随机(直接)访问。( )
- 根据数据元素之间的关系的不同特性,通常分为( )基本结构。
- 下列属于算法的重要特征的是( )。
- 关于串的叙述正确的是( )。
- 从表中任一结点出发都能扫描整个表的是( )。
- 图的应用算法有( )。
- 线性表的顺序存储结构是一种( )的存储结构。
- 二叉树是有( )基本单元构成。
- 下列哪一条不是顺序存储结构的优点( )。
- 下列数据结构中,属于线性数据结构的是( )。
- 非线性结构是数据元素之间存在一种:( )
- 如果以链表作为栈的存储结构,则出栈操作时( )。
- 动态查找包括( )查找。
- 如果要求一个线性表既能较快地查找,又能适应动态变化的要求,可以采用( )查找方法。
- 有向图的一个顶点的度为该顶点的( )。
- 下列时间复杂度中最坏的是( )。
- 对n个元素进行直接插入排序的过程中,共需要进行( )趟排序。
- 采用邻接表存储的图,其深度优先遍历类似于二叉树的( )。
- 栈和队列的共同点是( )。
- 一个具有 n 个顶点的有向图最多有( )条边。
- 组成数据的基本单位是( )。
- 在一个无向图中,所有顶点的度数之和等于所有弧数的( )倍。
- 若对n个元素进行直接插入排序,则进行第i趟排序过程前,有序表中的元素个数为( )。
- 算法的空间复杂度是指( )。
- 下列算法的时间复杂度是( )。
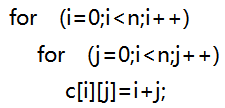
- 单链表中,增加头结点的目的是为了( )。
- 线性表的静态链表存储结构与顺序存储结构相比优点是( )。
- 关于数据结构中的树形结构,下列说法错误的是( )。
- 线性表L在( )情况下适用于使用链式结构实现。
- 线性表是( )。
- 二叉树的深度为 k,则二叉树最多有( )个结点。
A:错 B:对
答案:错
A:错 B:对
答案:B: 对
A:对 B:错
答案:B: 错
A:对 B:错
答案:对
A:对 B:错
答案:错
A:错 B:对
答案:对
A:错 B:对
答案:对
A:对 B:错
答案:错
A:错 B:对
答案:错
A:错 B:对
A:对 B:错
A:对 B:错
A:对 B:错
A:对 B:错
A:错 B:对
A:对 B:错
A:错 B:对
A:对 B:错
A:对 B:错
A:错 B:对
A:集合 B:图状结构 C:线性结构 D:树形结构
A:输入和输出 B:确定性 C:有穷性 D:可行性
A:模式匹配是串的一种重要运算 B:串是字符的有限序列 C:串既可以采用顺序存储,也可以采用链是存储 D:空串是空格构成的串
A:循环链表 B:顺序表 C:双链表 D:单链表
A:哈弗曼算法 B:克鲁斯卡尔算法 C:拓扑排序算法 D:迪杰斯特拉算法
A:随机存取 B:索引存取 C:顺序存取 D:散列存取
A:左子树 B:叶节点 C:右子树 D:根节点
A:可方便的用于各种逻辑结构的存储表示 B:删除运算方便 C:插入运算方便 D:存储密度大
A:树 B:栈 C:队列 D:图
A:多对多关系 B:多对一关系 C:一对一关系 D:一对多关系
A:必须判别栈元素类型 B:必须判别栈是否满 C:队栈可不做任何判别 D:必须判别栈是否空
A:顺序表 B:二叉排序树 C:索引顺序表 D:有序表
A:分块 B:散列 C:二分 D:顺序
A:出度 B:入度与出度之和 C:入度 D:(入度+出度)/2
A:O(n) B:O
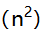 C:O(1)
D:O
C:O(1)
D:O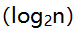
A:n+1 B:n C:2n D:n-1
A:先序遍历 B:后序遍历 C:按层次遍历 D:中序遍历
A:没有共同点 B:都是先进后出 C:只允许在端点处插入和删除元素 D:都是先进先出
A:n×(n+1)/2 B:
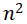 C:n×(n-1)/2
D:n×(n-1)
C:n×(n-1)/2
D:n×(n-1)
A:数据项 B:数据元素 C:数据类型 D:数据变量
A:1/2 B:2 C:1 D:4
A:i B:i-1 C:i+l D:1
A:算法执行过程中所需要的存储空间 B:算法程序中的指令条数 C:算法程序的长度 D:算法程序所占的存储空间
A:O(1) B:O
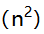 C:O
C:O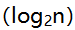 D:O(n)
D:O(n)
A:用于标识起始结点的位置 B:使单链表中至少有一个结点 C:用于标识单链表 D:方便运算的实现
A:便于随机存取 B:便于利用零散的存储器空间 C:所有的操作算法实现简单 D:便于插入和删除
A:除叶子结点外其余每个结点有且只有一个后续节点 B:叶子结点没有后续结点 C:除树根结点以外其余每个结点有且只有一个前驱结点 D:树根结点没有前驱结点
A:需要经常修改L中的结点值 B:L中含有大量的结点 C:L中结点结构复杂 D:需经常对L进行删除插入
A:一个无限序列,可以为空 B:一个有限序列,可以为空 C:一个无限序列,不能为空 D:一个有限序列,不能为空
A:2k-1 B:2k-1 C:2k D:2k-1
温馨提示支付 ¥5.00 元后可查看付费内容,请先翻页预览!
