- 上述原始数据中,在“期刊*年份”层面进行数据聚合,统计每个期刊每年论文的平均页码,上述计算得到的平均页码最大值为:( )
- 上述原始数据中,《管理世界》平均每篇论文作者人数:( )
- 上述原始数据中,第一作者姓名为两个字的论文有多少篇:( )
- 上述原始数据中,论文发表月份为8月份的论文有多少篇:( )
- 上述原始数据中,删除论文摘要中字数超过300字后的剩余样本量为:( )
- 对上述文字进行jieba分词后(不考虑停用词和自定义词典),去掉标点符号和单字词后的词数区间为( )
- 对上述文字进行jieba分词后(不考虑停用词和自定义词典),包含的总词数区间为( )
- 使用正则表达式,将上述文字分割为若干个语句(以。.?!;,为语句分割标准),完成后第十个句子的前五个字为( )
- 在上述文字中,欲提取“老旧小区”一词及其前后文各4个字,以下代码正确的是( )
- 在上述文字中,“城市”一词出现的次数是( )
- 上述文字包含的不重复字数是( )
- 以下不能创建一个字典的语句是:( )
- 以下哪个说法不是函数的优点:( )
- s=”Happy New Year”,则s[3:8]的值为:( )
- 以下正则表达式中,属于非贪婪匹配,且允许出现0次的是:( )
- 下列语句中变量i取值次数最多的是:( )
- 下面哪一个是布尔值:( )
- 在一个应用程序中定义 a=[1,2,3,4,5,6,7,8,9,10],为了打印输出列表a的最后一个元素,下面正确的代码是:( )

- 以下是正确的字符串的为:( )
- 定义vehicle=[[‘train’,’car’],[‘bus’,’subway’],[‘ship’,’bicycle’],[‘car’]],则len(vehicle[1][1])的结果为:( )
- 网页https://music.163.com/的编码格式为:( )
- 下面哪个不是Python合法的标识符:( )
- 若a=(1,2,3),那么下列哪个操作是非法的:( )
- 以下哪个是不合法的布尔表达式:( )
- 两个数据‘GPA'、3.6相加为’GPA_3.6’的正确写法是:( )
- Python程序print(‘哟,’+”写程序呢”)的结果为:( )
- 下面哪一个是以追加模式打开文件作写入操作的:( )
- Python不支持的数据类型有:( )
- 若 a=range(100),以下哪个操作是非法的:( )
- Python中对代码注释可以用“//”。( )
- 在Python当中,当作为条件表达式时,空值、空字符串、空列表、空元组、空字典、空集合、空迭代对象以及任意形式的数字0都等价于False。( )
- 表达式 {1, 2} * 2 的值为 {1, 2, 1, 2}。( )
- 同一个列表对象中所有元素必须为相同类型。( )
- 在Python中运算符+不仅可以实现数值的相加、字符串连接,还可以实现列表、元组的合并和集合的并集运算。( )
- Python的正则表达式中,[^xyz]代表匹配x,y,z之外的字符。( )
- 列表对象的排序方法sort____只能按元素从小到大排列,不支持别的排序方式。( )
- 当作为条件表达式时,{}与None等价。( )
- 在Python变成当中,使用try...except语句主要目的是核查Python程序错误的原因。( )
- pip命令也支持扩展名为.whl的文件直接安装Python扩展库。( )
- 在Python爬虫中,使用API(应用程序接口)的主要目的是为了突破网站爬虫限制,实现反爬虫。( )
- 表达式’a’+str(1)的值为’b’。( )
- 已知x=3,那么赋值语句x='abcedfg'是无法正常执行的。( )
- 形参可以看做是函数内部的局部变量,函数运行结束之后形参就不可访问了。( )
- Python集合中的元素可以是元组。( )
- 在python的循环体内,continue语句的作用是结束这一轮的循环,程序跳转到循环头部。( )
- Python编程语句区分大小写。
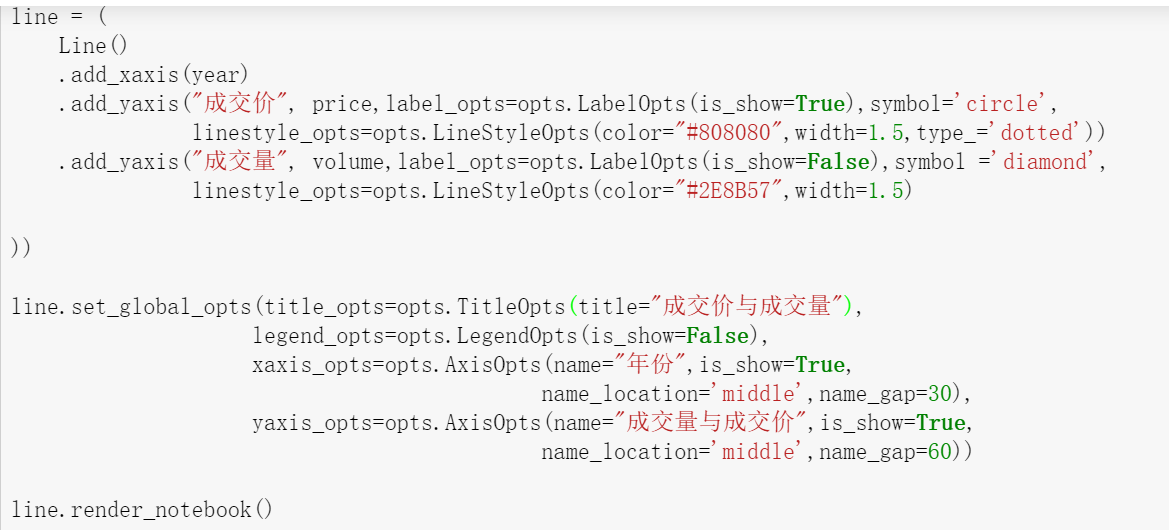
- 在Python的序列分片运算符[start:end]中,start是开始索引,end是结束索引。( )
- 不可以在同一台计算机上同时运行多个Python程序。( )
- 已知x和y是两个等长的整数列表,那么表达式[i+j for i,j in zip(x,y)]的作用时计算这两个列表所表示的向量的和。( )
- 设有变量赋值 x=3.5;y=4.6;z=5.7,则以下的表达式中值为True的是:( )。
- 在一个应用程序中定义 a=[1,2,3,4,5,6,7,8,9,10],为了打印输出列表a的最后一个元素,下面正确的代码是( )。
- 以下哪个不是python中的关键字:( )
- 设s=”Happy New Year”,则s[3:8]的值为:( )
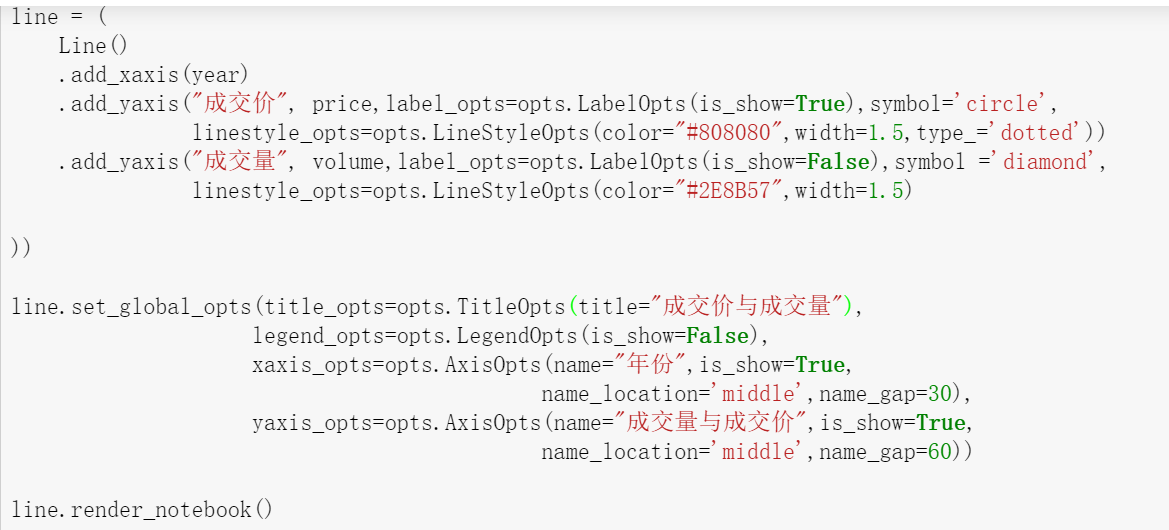
- 在16进制颜色码对照中,#0000FF代表的颜色是:( )
- 定义了两个数组(ndarray) x1和x2,那么x1+x2的意思是指两个数值进行拼接。( )
- 在数据框df1当中,通过df1['mag_name'].replace('\D',""),可以将“mag_name”列中的所有数字删除。( )
- 定义了数据库df1,其中包含一列股票名称’stock_name’,以下那个代码可以提取出股票名称的前两个字。( )
- 在数据框df1当中,‘daily’是一列日期格式数据,如果准备将该列日期统一增加10天,以下代码正确的是:( )
- 定义了数据库df1,那么以下程序df1.drop_duplicates(subset=['c1','c2'],keep='first',inplace=True)当中的“inplace=True”是指这样命令运行的结果覆盖原来的df1。( )
- Python的正则表达式中,re.S代表匹配包括换行在内的多个字符。( )
- Python爬虫中,以下那种XPath代码能够获取文本信息:( )
- 正则表达式 R[\d]{2},能匹配出以下哪个字符串:( )
- 网页https://xueqiu.com/的编码格式为:( )
- 在Python爬虫中,一些网站会有意使用API(应用程序接口)的方式,来便利使用者调取其数据。( )
- 网页https://www.douban.com/的编码格式为:( )
- 从以下类似字符串:'''其他信息<td><div align="center">1984>div>郭峰</div></td>其他信息'''中提取“郭峰”信息,以下正则表达式写法中正确的是:( )
- 正则表达式 R[0-9]{3},能匹配出以下哪个字符串:( )
- Python的正则表达式中,+代表匹配前一个字符0或者无限次。( )
- 如果要对一个上市公司社交媒体中的所有发帖信息进行分词处理,以下哪些词不能作为自定义词典:( )
- 文本的数学表达中,one-hot方法存在的问题包括:( )
- 在Python当中,导入第三方模块的方式存在语法上错误的为:( )
- 已知data是一篇长文本,那么语句data_new=data.split('\n')代表的含义是将data按照换行符进行分割。( )
- 执行如下Python语句:str1 = "Python example....wow!!!";str2 = "exam"; 那么print(str1.find(str2, 5)) 打印的结果为:( )
- Python中需要将循环执行的语句放入“{}”内:( )
- 下列语句中变量i取值次数最多的是:( )
- 定义Python函数如下:def shownum(numbers):for n in numbers:print(n)下面那些在调用函数时会报错( )

- 下列Python语句正确的是:( )
- 定义字典:gpa={‘小明’:3.0,’小王’:2.5, ‘小郭’:3.8, ‘小刘’:2.5},那么语句 list(gpa.values())[2]返回值为:( )
- 在Python当中,字典的元素是有顺序的,而列表的元素则没有顺序( )
- 在Python当中,已知x=[1,2]和y=[3,4],那么x+y等于:( )
- 在Python的字符串处理中,s[1:5]可以去除字符串s中从索引值1开始到5结束的子字符串。( )
- 在Python中,下列哪个变量名称是正确的:( )
- Jupyter Notebook是一个专门对Python进行编译的编译器。( )
- Python 3的结果打印方式为:( )
- 这门课程的学习目标为:( )
答案:23.9
答案:2.49
答案:2155
答案:692
答案:5962
答案:[210,220]
答案:[490,500]
答案:要更好推进
答案:data[data.index(''老旧小区'')-4:data.index(''老旧小区'')+8]
答案:27
答案:320
温馨提示支付 ¥3.00 元后可查看付费内容,请先翻页预览!

