三亚学院
- 机器学习教父Tom Mitchell提出的机器学习定义是: 一个程序被认为能从经验E中学习,解决任务 T,达到性能度量值P,当且仅当,有了经验 后,经过 评判,程序在处理 时的性能有所提升。____,____,____。
- 机器学习=算法。
- 训练集与测试集的划分对最终模型的确定无影响。( )
- 支持向量是那些最接近决策平面的数据点。( )
- Dropout作用于每份小批量训练数据,由于其随机丢弃部分神经元的机制,相当于每次迭代都在训练不同结构的神经网络。( )
- 决策树只能用于分类问题,不能用于回归问题。( )
- 预剪枝是在决策树的构建过程中加入限制,比如控制叶子节点最少的样本个数,提前停止。( )
- 回归函数A和B,如果A比B简单,则A一定会比B在测试集上表现好。( )
- 逻辑回归是一个回归模型。( )
- SVM是分类模型。( )
- ROC是接收者操作特征曲线(receiver operating characteristic curve),ROC曲线越靠拢(0,1)点,越偏离45度对角线越差。( )
- 在分类问题中,我们经常会遇到正负样本数据量不等的情况,比如正样本为10w条数据,负样本只有1w条数据,以下最合适的处理方法是( )。
- 以下说法中正确的是( )。
- 朴素贝叶斯对缺失值敏不敏感,为什么( )
- 下列哪些假设是我们推导线性回归参数时遵循的?( )
- 下列模型属于机器学习生成式模型的是( )。
- 假定某同学使用Naive Bayesian(NB)分类模型时,不小心将训练数据的两个维度搞重复了,那么关于NB的说法中正确的是( )。
- 影响聚类算法效果的主要原因有?( )
- 下列哪些方法可以用来对高维数据进行降维?( )
- 位势函数法的积累势函数K(x)的作用相当于Bayes判决中的( )。
- 数据清理中,处理缺失值的方法是( )。
- 下列哪个不属于常用的文本分类的特征选择算法?( )
- 如果一个模型在训练集上正确率为99%,测试集上正确率为60%,则下面哪种处理方法是错误的?( )
- 已知一组数据的协方差矩阵P,下面关于主分量说法错误的是( )。
- 对于PCA说法正确的是1.我们必须在使用PCA前规范化数据2.我们应该选择使得模型有最大variance的主成分3.我们应该选择使得模型有最小variance的主成分4.我们可以使用PCA在低维度上做数据可视化( )。
- 下面哪些可能是一个文本语料库的特征1.一个文档中的词频统计2.文档中单词的布尔特征3.词向量4.词性标记5.基本语法依赖6.整个文档( )。
- 在spss的基础分析模块中,作用是“以行列表的形式揭示数据之间的关系”的是( )
- 以下说法正确的是1.一个机器学习模型,如果有较高准确率,总是说明这个分类器是好的2.如果增加模型复杂度, 那么模型的测试错误率总是会降低3.如果增加模型复杂度, 那么模型的训练错误率总是会降低( )。
- SVM在下列那种情况下表现糟糕?( )
- 印度电影《宝莱坞机器人之恋》中的机器人七弟采用的智能算法最有可能是以下哪一种?( )
- 假定你使用了一个很大γ值的RBF核,这意味着( )。
- 关于机器学习模型的评判指标,下面错误的是( )
- 我们想在大数据集上训练决策树, 为了使用较少时间, 我们可以( )。
- 下面哪个/些选项对 K 折交叉验证的描述是正确的?1.增大 K 将导致交叉验证结果时需要更多的时间2.更大的 K 值相比于小 K 值将对交叉验证结构有更高的信心3.如果 K=N,那么其称为留一交叉验证,其中 N 为验证集中的样本数量( )
- 一般来说,下列哪种方法常用来预测连续独立变量?( )
- 一元线性回归的基本假设不包括( )。
- 文本信息检索的一个核心问题是文本相似度计算,将查询条件和文本之间的相似程度数值化,从而方便比较。当文档和查询都表示成向量时,可以利用向量的内积的大小近似地表示两个向量之间的相关程度。设有两个文档和查询抽取特征和去除停用词后分别是:文档d1: a、b、c、a、f、b、a、f、h文档d2: a、c查询q: a、c、a特征项集合为 {a、b、c、d、e、f、g、h}如果采用二值向量表示,那么利用内积法计算出q和d1、d2的相似度分别是( )。
- 变量选择是用来选择最好的判别器子集,如果要考虑模型效率,我们应该做哪些变量选择的考虑?1.多个变量其实有相同的用处2.变量对于模型的解释有多大作用3.特征携带的信息4.交叉验证( )
- 二分类任务中,有三个分类器h1,h2,h3,三个测试样本x1,x2,x3。假设1表示分类结果正确,0表示错误,h1在x1,x2,x3的结果分别(1,1,0),h2,h3分别为(0,1,1),(1,0,1),按投票法集成三个分类器,下列说法正确的是( )。
- 词向量描述正确的是( )。
- 以下哪种决策树法可以用于求解回归问题( )
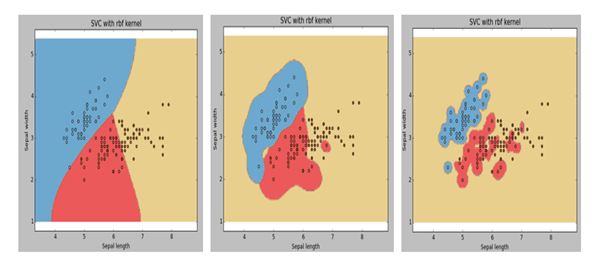
- 下图是同一个SVM模型, 但是使用了不同的径向基核函数的gamma参数, 依次是g1, g2, g3 , 下面大小比较正确的是(C)。
 ( )。
( )。 - 下列哪些不特别适合用来对高维数据进行降维?( )
- https://image.zhihuishu.com/zhs/doctrans/docx2html/202105/bfcba348d52244dfb44453d656c8643e.png
- 你正在使用带有L1正则化的logistic回归做二分类,其中C是正则化参数,w1和w2是 x1和 x2的系数。当你把C值从0增加至非常大的值时,下面哪个选项是正确的?( )
- 在HMM中,如果已知观察序列和产生观察序列的状态序列,那么可用以下哪种方法直接进行参数估计( )。
- 数据科学家可能会同时使用多个算法(模型)进行预测,并且最后把这些算法的结果集成起来进行最后的预测(集成学习),以下对集成学习说法正确的是( )。
- 朴素贝叶斯NB与逻辑回归LR的区别( )
- 对于随机森林和GradientBoosting Trees, 下面说法正确的是1.在随机森林的单个树中, 树和树之间是有依赖的, 而GradientBoosting Trees中的单个树之间是没有依赖的2.这两个模型都使用随机特征子集, 来生成许多单个的树3.我们可以并行地生成GradientBoosting Trees单个树, 因为它们之间是没有依赖的, GradientBoosting Trees训练模型的表现总是比随机森林好( )。
- 下面对集成学习模型中的弱学习者描述错误的是( )。
答案:E;P;T
A:错 B:对
答案:12)machine-learning algorithm
A:对 B:错
答案:错
A:对 B:错
答案:对
A:对 B:错
答案:对
A:错 B:对
答案:错
A:对 B:错
答案:对
A:对 B:错
答案:错
A:对 B:错
答案:错
A:错 B:对
A:对 B:错
A:从10w正样本中随机抽取1w参与分类
B:将负样本重复10次,生成10w样本量,打乱顺序参与分类
C:直接进行分类,可以最大限度利用数据
D:将负样本每个权重设置为10,正样本权重为1,参与训练过程
A:在AdaBoost算法中,所有被分错的样本的权重更新比例相同
B:SVM对噪声(如来自其他分布的噪声样本)鲁棒
C:Boosting和Bagging都是组合多个分类器投票的方法,二者都是根据单个分类器的正确率决定其权重
D:给定n个数据点,如果其中一半用于训练,一般用于测试,则训练误差和测试误差之间的差别会随着n的增加而减少
A:在预测时,不影响预测最终结果。
B:缺失的数据在建模时将被忽略,不影响类条件概率的计算
C:朴素贝叶斯算法对缺失值不敏感,能够处理缺失的数据,在算法的建模时和预测时数据的属性都是单独处理的。
D:朴素贝叶斯对缺失值是敏感的
A:X 与 Y 有线性关系(多项式关系)
B:误差一般服从 0 均值和固定标准差的正态分布
C:X 是非随机且测量没有误差的
D:模型误差在统计学上是独立的
A:朴素贝叶斯
B:隐马尔科夫模型(HMM)
C:深度信念网络(DBN)
D:马尔科夫随机场(Markov Random Fields)
A:当两列特征高度相关时,无法用两列特征相同时所得到的结论来分析问题
B:模型效果相比无重复特征的情况下精确度会降低
C:这个被重复的特征在模型中的决定作用会被加强
D:如果所有特征都被重复一遍,得到的模型预测结果相对于不重复的情况下的模型预测结果一样。
A:特征选取
B:模式相似性测度
C:分类准则
D:已知类别的样本质量
A:线性判别法
B:LASSO
C:聚类分析
D:拉普拉斯特征映射
E:小波分析法
F:主成分分析法
A:先验概率
B:后验概率
C:类概率密度与先验概率的乘积
D:类概率密度
A:估算
B:变量删除
C:成对删除
D:整例删除
A:主成分分析
B:信息增益
C:互信息
D:卡方检验值
A:减少模型复杂度
B:增加训练样本数量
C:加入正则化项
D:增加模型复杂度
A:主分量分析就是K-L变换
B:在经主分量分解后,协方差矩阵成为对角矩阵
C:主分量分析的最佳准则是对一组数据进行按一组正交基分解, 在只取相同数量分量的条件下,以均方误差计算截尾误差最小
D:主分量是通过求协方差矩阵的特征值得到
A:1 and 3
B:1, 3 and 4
C:3 and 4
D:2 and 4
E:1, 2 and 4
A:1234
B:123
C:123456
D:12345
A:相关
B:多重相应
C:交叉表
D:数据描述
A:1 and 3
B:3
C:2
D:1
A:清洗过的数据
B:含噪声数据与重叠数据点
C:标称型数据
D:线性可分数据
A:穷举算法
B:遗传算法
C:神经网络
D:模拟退火
A:模型将考虑使用远离超平面的点建模
B:模型仅使用接近超平面的点来建模
C:模型不会被点到超平面的距离所影响
D:其余选项都不正确
A:机器学习模型的精准度(Precision)越高,模型性能不一定越好,还要看模型的召回率(Recall),特别是在正负样本分布不均的情况下。
B:为了解决准确率和召回率冲突问题,引入了F1分数
C:正确率、召回率和 F 值取值都在0和1之间,数值越接近0,查准率或查全率就越高
D:召回率是指检索出的相关文档数和文档库中所有的相关文档数的比率,衡量的是检索系统的查全率
A:增加学习率 (learning rate)
B:减少树的深度
C:减少树的数量
D:增加树的深度
A:1 和 3
B:1 和 2
C:1、2 和 3
D:2 和 3
A:线性回归和逻辑回归都行
B:逻辑回顾
C:线性回归
D:其余选项说法都不对
A:随机误差项是一个期望值或平均值为0的随机变量;
B:随机误差项彼此相关;
C:解释变量是确定性变量,不是随机变量,与随机误差项彼此之间相互独立;
D:随机误差项服从正态分布
E:解释变量之间不存在精确的(完全的)线性关系,即解释变量的样本观测值矩阵是满秩矩阵;
F:对于解释变量的所有观测值,随机误差项有相同的方差;
A:1、1
B:2、2
C:0、0
D:7、2
A:所有选项都对
B:1 和 4
C:1, 3 和 4
D:1, 2 和 3
A:集成降低了性能
B:集成提高了性能
C:集成效果不能确定
D:集成没有效果
A:没有正确答案
B:词向量技术是将词转化成为稀疏向量的技术
C:女人+漂亮=女神
D:自然语言表示的单词不能转换为计算机能够理解的向量或矩阵形式
A:CART
B:C4.5
C:其余选项都可以
D:ID3
A:g1 = g2 = g3
B:g1 <= g2 <= g3
C:g1 < g2 < g3
D:g1 >= g2 >= g3
E:g1 > g2 > g3
A:聚类分析
B:主成分分析法
C:小波分析法
D:线性判别法
E:LASSO
F:拉普拉斯特征映射
A:不会
B:会
C:不确定
A:第一个 w1 成了 0,接着 w2 也成了 0
B:即使在 C 成为大值之后,w1 和 w2 都不能成 0
C:第一个 w2 成了 0,接着 w1 也成了 0
D:w1 和 w2 同时成了 0
A:极大似然估计
B:EM算法
C:前向后向算法
D:维特比算法
A:单个模型之间有低相关性
B:在集成学习中使用“平均权重”而不是“投票”会比较好
C:单个模型之间有高相关性
D:单个模型都是用的一个算法
A:NB是判别式模型
B:NB适用于数据集少的情景, LR适用于大规模数据集
C:LR是生成模型
D:其余选项说法都不对
A:1, 3 and 4
B:2
C:2 and 4
D:1 and 2
A:他们通常带有高偏差,所以其并不能解决复杂学习问题
B:他们经常不会过拟合
C:他们通常会过拟合
温馨提示支付 ¥5.00 元后可查看付费内容,请先翻页预览!



