第八章 机器学习实验:以具体数据为例讲解机器学习的流程,包括数据业务理解、数据预处理、统计图描述统计分析、决策树、随机森林和支持向量机等知识点。8.1机器学习概述、数据业务理解:介绍adult数据的变量、变量类型,数据分析的主要任务。[单选题]决策树学习算法主要包括①决策树的生成、②决策树的剪枝、③特征选择等3个部分,3个部分顺序正确的是( )选项:[③②①
8.2数据预处理:根据adult数据的特点,介绍部分数据预处理方法。
8.3描述统计分析:根据adult数据任务要求进行相关统计图等描述统计分析。
8.4决策树模型分析原理:介绍决策树算法原理。
8.5决策树模型分析操作演示:介绍决策树算法R软件操作演示。
8.6随机森林模型分析原理:介绍随机森林算法原理。
8.7随机森林模型分析操作演示:介绍随机森林分析R软件操作演示。
8.8支持向量机分析原理:介绍支持向量机分析原理。
8.9支持向量机分析操作演示:介绍支持向量机分析R软件操作演示。
8.1机器学习概述、数据业务理解:介绍adult数据的变量、变量类型,数据分析的主要任务。
8.2数据预处理:根据adult数据的特点,介绍部分数据预处理方法。
8.3描述统计分析:根据adult数据任务要求进行相关统计图等描述统计分析。
8.4决策树模型分析原理:介绍决策树算法原理。
8.5决策树模型分析操作演示:介绍决策树算法R软件操作演示。
8.6随机森林模型分析原理:介绍随机森林算法原理。
8.7随机森林模型分析操作演示:介绍随机森林分析R软件操作演示。
8.8支持向量机分析原理:介绍支持向量机分析原理。
8.9支持向量机分析操作演示:介绍支持向量机分析R软件操作演示。
, ②①③
, ③①②
, ①②③
]

[单选题]可以将所有含缺失值NA的观测都删去的函数是( )选项:[na.contiguous
, na.fail
, na.pass
, na.omit
]
[单选题]
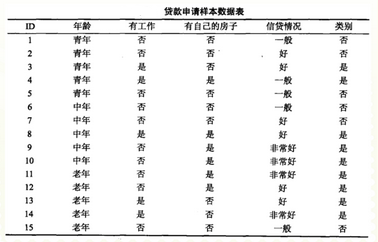 如图数据,研究是否批准贷款申请(“类别”变量)。经计算年龄、有工作、有自己的房子、信贷情况4个特征的信息增益依次为0.083、0.324、0.420和0.363,根据ID3决策树学习算法应该选择( )为划分标志。选项:[年龄
如图数据,研究是否批准贷款申请(“类别”变量)。经计算年龄、有工作、有自己的房子、信贷情况4个特征的信息增益依次为0.083、0.324、0.420和0.363,根据ID3决策树学习算法应该选择( )为划分标志。选项:[年龄, 有工作
, 信贷情况
, 有自己的房子
]
[单选题]如果一个 SVM 模型出现欠拟合,那么下列哪种方法能解决这一问题?( )选项:[同时减少惩罚参数 C的值和核系数(gamma参数)
, 减小核系数(gamma参数)
, 减小惩罚参数 C 的值
, 增大惩罚参数 C 的值
]
[单选题]评估完模型之后,发现随机森林模型存在高偏差(high bias),应该如何解决?( )选项:[增加模型的特征数量
, 减少模型的特征数量
, 上面说法都正确
, 增加样本数量
]
[单选题]假设我们使用原始的非线性可分的 Soft-SVM 优化目标函数。我们需要做什么来保证得到的模型是线性可分离的?( )选项:[C = 1
, C 正无穷大
, C 负无穷大
, C = 0
]
[多选题]下列哪些R包可以进行决策树分析( )选项:[party
, dplyr
, rpart
, Rmisc
, tree
]
[判断题]CART决策树算法以信息增益率准则来选择划分属性。( )选项:[错, 对]
[判断题]在训练完 SVM 之后,我们可以只保留支持向量,而舍去所有非支持向量。仍然不会影响模型分类能力。这句话是否正确?( )选项:[错, 对]
[判断题]随机森林模型是使用随机特征子集来创建中间树的( )选项:[错, 对]
[判断题]随机森林模型的中间树不是相互独立的( )选项:[错, 对]
温馨提示支付 ¥1.00 元后可查看付费内容,请先翻页预览!
