提示:内容已经过期谨慎付费,点击上方查看最新答案
计量经济学(山东联盟-山东财经大学)
- Which of the following models is used quite often to capture decreasing or increasing marginal effects of a variable?
- Changing the unit of measurement of any independent variable, where log of the dependent variable appears in the regression:
- Which of the following is true of the OLS t statistics?
- A change in the unit of measurement of the dependent variable in a model does not lead to a change in
- Which of the following is true of experimental data?
托宾模型中的设定问题 ( )。
- Econometrics is the branch of economics that
- A data set that consists of observations on a variable or several variables over time is called a _____ data set
- 因变量为 y,自变量为 logx的函数形式为:( )
条件零均值假定不成立将会导致OLS的估计:( )
- Data on the income of law graduates collected at different times during the same year is
- An empirical analysis relies on _____to test a theory.
- Which of the following is a statistic that can be used to test hypotheses about a single population parameter?
- Which of the following is true?
- A data set that consists of a sample of individuals, households, frms, cities, states, countries, or a variety of other units, taken at a given point in time, is called a(n)
- Which of the following tests helps in the detection of heteroskedasticity?
- Weighted least squares estimation is used only when
- 对美国所有家庭构成的总体考虑一个家庭储蓄方程:
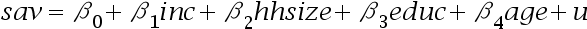
其中,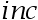 表示家庭收入,
表示家庭收入,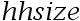 表示家庭规模,
表示家庭规模,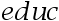 表示户主受教育年数,而
表示户主受教育年数,而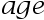 表示户主的年龄。假定
表示户主的年龄。假定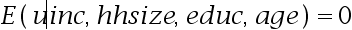 。
。
假设样本只包括户主年龄在25岁以上的家庭,我们使用OLS进行估计,得到的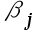 是( );
是( );
假设我们从样本中排除掉储蓄超过每年25000美元以上的家庭,OLS能得到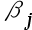 的估计是( )。 ( )
的估计是( )。 ( ) - The linear probability model contains heteroskedasticity unless _____.
- A variable is standardized in the sample
- 在多元回归中,OLS的基本假定包括:( )
- 一个计量经济模型中,可作为解释变量的有
- 在回归方程中,因变量y也可以被称为:( )
- 与其他经济模型相比,计量经济模型有如下特点
- 计量经济模型的应用在于
- 下列哪些方法可用于异方差性的检验
- 计量经济学是以下哪些学科相结合的综合性学科
- 当模型存在异方差现象进,加权最小二乘估计量具备
- 模型的拟合优度R-squared随变量的度量单位的变化有所改变。
- F统计量计算公式为:
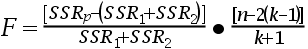 。 ( )
。 ( ) - If the calculated value of the t statistic is greater than the critical value, the null hypothesis, H0 is rejected in favor of the alternative hypothesis, H1.
- 当
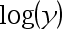 是一个模型的因变量时,将虚拟变量的系数乘以100,可解释为
是一个模型的因变量时,将虚拟变量的系数乘以100,可解释为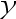 在保持所有其他因素不变情况下的百分数差异。( )
在保持所有其他因素不变情况下的百分数差异。( ) - 在多元回归中,即使模型存在完全共线性问题,依旧可以运用OLS进行估计。
- 在没有假定泊松分布完全正确的情况下使用泊松MLE时,称之为准极大似然估计。 ( )
- 女性受教育程度(educ)对生育率(kids)影响的回归方程为
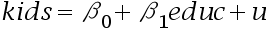 ,其中
,其中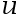 为误差项。年龄、收入、家庭背景都可能包含在误差项中,但它们必须与受教育程度无关。( )
为误差项。年龄、收入、家庭背景都可能包含在误差项中,但它们必须与受教育程度无关。( ) - If the Breusch-Pagan Test for heteroskedasticity results in a large p-value, the null hypothesis of homoskedasticty is rejected.
- 一般地,仅改变自变量自身的度量单位,不会影响截距估计值。( )
- The linear probability model always contains heteroskedasticity when the dependent variable is a binary variable unless all of the slope parameters are zero.
- 在概率单位模型下值得注意的两个问题是:1)潜变量模型中的e的非正态性;2)e的异方差性。( )
- P值就是给定t统计量,能拒绝虚拟假设的最大显著性水平。
- 拟合优度R-squared的值越接近于1代表拟合优度越好,拟合优度R-squared可以用于作为评价模型好坏的标准。
- Predictions of a dependent variable are subject to sampling variation
- The notion of ceteris paribus means “other factors being equal.”
- 如果多元回归分析中包含了一个或多个无关变量,并不会影响到OLS估计的无偏性。
- 普通最小二乘法OLS是计量经济学中常用的计量模型之一。
- 残差和误差是相同的两个量,残差平方和又可以称为“误差平方和”。
A:Models with quadratic functions B:Models with interaction terms C:Models with variables in level D:Models with logarithmic functions
AI参考:正确答案是【D:Models with logarithmic functions】。该题需要找出哪种模型常用于捕捉一个变量的边际效应的变化情况,比如减少或增加。而logarithmic functions(对数函数)常常被用来处理这种情况,因为对数函数可以有效地捕捉变量的边际效应变化,尤其是当这个变化是逐步、渐进的时。因此,选项D是对的。选项A和B可能会捕捉到变量之间非线性的交互影响,而不是变量自身边际效应的变化;选项C则可能只关注变量的水平值,而不是其边际效应的变化。'
A:affects neither the slope nor the intercept coefficient. B:affects only the intercept coefficient. C:affects only the slope coefficient. D:affects both the slope and intercept coefficients.
答案:affects only the intercept coefficient.
A:The usual t statistics do not have exact t distributions if the sample size is large. B:The heteroskedasticity-robust t statistics are justifed only if the sample size is large. C:The heteroskedasticty-robust t statistics are justifed only if the sample size is small. D: In the presence of homoscedasticity, the usual t statistics do not have exact t distributions if the sample size is small.
AI参考:正确选项:D: In the presence of homoscedasticity, the usual t statistics do not have exact t distributions if the sample size is small.解释:选项D表示在同方差假设(homoscedasticity)成立的情况下,如果样本量较小,则常用的t统计量分布不精确。这是因为大样本情况下,t统计量的分布是精确的,但在小样本情况下,如果存在异方差(heteroskedasticity),则t统计量的分布就不再是精确的,需要采用异方差性鲁棒的t统计量。所以选项D是正确的。'
A:the confidence intervals of the regression. B:the standard error of the regression. C:the goodness-of-fit of the regression. D:the sum of squared residuals of the regression.
答案:你可以在课外和你的同学练习.AI参考:正确答案是 B:the standard error of the regression.。在回归模型中,如果自变量的单位发生变化,不会导致置信区间、拟合优度或残差平方和发生变化,但会改变回归的标准误。标准误是衡量回归系数估计值精度的指标,它的大小反映了样本数据中回归系数估计值的不确定性。因此,如果单位发生变化,标准误也会随之变化。所以选项B是正确的。'
A:Experimental data cannot be collected in a controlled environment. B:Experimental data is sometimes called observational data. C:Experimental data are collected in laboratory environments in the natural sciences. D:Experimental data is sometimes called retrospective data.
AI参考:正确答案是C:实验数据是在自然科学中在实验室环境中收集的。原文中提到“experimental data are collected in laboratory environments in the natural sciences”,意思是实验数据是在自然科学中在实验室环境中收集的,所以选项C是正确的。其他选项不符合原文的意思。选项A表示实验数据不能在受控环境中收集,这是不正确的;选项B和D都没有提到实验数据的本质特点。'
A:托宾模型的期望表达式,假定潜变量模型满足正态性和同方差性 B:非正式地评价托宾模型方法是否适当 C:托宾模型潜在的重要局限性 D:其余选项都对
AI参考:正确选项是【C:托宾模型潜在的重要局限性】。托宾模型是一种经济学模型,用于解释股票市场对公司投资的影响。在托宾模型中,存在一些设定问题,如模型假设的潜变量模型是否满足正态性和同方差性等,这些问题可能会影响模型的准确性和适用性。因此,选项A不是正确答案。同时,托宾模型的方法是否适当也不是模型的设定问题,而是关于模型应用和解释的问题。因此,选项B也不正确。而其他选项D的说法本身就不符合逻辑,因此也不正确。因此,正确答案是托宾模型潜在的重要局限性。'
A:deals with the performance, structure, behavior, and decision-making of an economy as a whole B:develops and uses statistical methods for estimating economic relationships C:studies the behavior of individual economic agents in making economic decisions D:applies mathematical methods to represent economic theories and solve economic problems.
答案:develops and uses statistical methods for estimating economic relationships
A:binary B:time series C:cross-sectional D:experimental
答案:正确AI参考:正确选项是【B:time series】。根据问题描述,一个包含关于一个或多个变量随时间变化的观察数据的集合被称为时间序列数据集。选项A、C和D都不符合问题的描述。选项A是二元的,选项C是横截面的,而选项D是实验性的,这些选项都不能完全符合问题的要求。因此,B选项“时间序列”是正确答案。'
A:对数---对数 B:对数---水平值 C:水平值---对数 D:水平值---水平值
答案:水平值---对数
A:有偏 B:其余选项都对 C:没有影响 D:不再满足最小方差
AI参考:正确选项为D:不再满足最小方差。条件零均值假定是线性回归分析中的一个基本假定,如果该假定不成立,则回归模型中的误差项不再是零均值化的,这会导致回归模型的估计不再满足最小方差,从而影响OLS估计的精度和可靠性。因此,在进行线性回归分析时,必须确保满足零均值假定。'
A:cross-sectional data B:time series data C:panel data D:experimental data
AI参考:正确选项是【B:time series data】。题目中提到的是在同一年的不同时间收集的法律毕业生收入数据,这表明这些数据是按照时间顺序排列的,属于时间序列数据。因此,选项B是正确答案。选项A、C、D都不符合题意。选项A的“横截面数据”通常是在不同的时间点收集的数据,而选项C的“面板数据”通常用于描述同一批个体在多个时间点的数据,与题目描述不符。选项D的“实验数据”通常用于描述通过实验方法获得的数据,与题目描述也不符。'
A:customs and conventions B:data C:sciences. D:ethical considerations
A:t statistic B:χ2 statistic C:Durbin Watson statistic D:F statistic
AI参考:正确选项是【B:χ2 statistic】。χ2 statistic(卡方统计量)是用于测试单总体参数假设的统计量之一。它通常用于检验两个或多个样本数据之间的差异是否具有统计学意义,或者用于检验一个样本数据是否符合一个特定的理论分布。因此,选项B是正确答案。其他选项A、C、D分别代表t统计量、杜宾-瓦森统计量和F统计量,这些统计量通常用于多元统计分析或其他更复杂的统计方法中。'
A:In weighted least squares estimation, each observation is given an identical weight. B:In weighted least squares estimation, less weight is given to observations with a higher error variance. C:In ordinary least squares estimation, each observation is given a different weight. D:In ordinary least squares estimation, less weight is given to observations with a lower error variance.
AI参考:正确选项是【B:In weighted least squares estimation, less weight is given to observations with a higher error variance.】。在加权最小二乘法估计中,误差较大的观测值所赋予的权重较小,因此选项B是正确的。选项A和C描述的是普通最小二乘法估计,选项D描述的是误差较小观测值的权重较小,但并没有明确指出误差较大的观测值所赋予的权重较小,因此选项B是唯一正确的选项。'
A:experimental data set B:longitudinal data set C:time series data set D:cross-sectional data set
AI参考:正确选项是D:cross-sectional data set。解释:cross-sectional data set指的是一个数据集,它由一组在某一特定时间点抽取的个体、家庭、地区、城市、州、国家或其他各种单位组成。这个数据集的特点是只关注一个时间点上的样本,而不是一个时间段内的数据变化。因此,选项D是正确答案。而选项A的experimental data set指的是实验数据,通常用于科学研究;选项B的longitudinal data set指的是纵向数据,通常用于追踪同一组对象在不同时间点的变化;选项C的时间系列数据指的是一个数据集,其中数据点按时间顺序排列,用于研究时间上的变化趋势。这三个选项都与题目描述不符。'
A:The Durbin-Watson test B:The Breusch-Godfrey test C:The Breusch-Pagan test D:The Chow test
A:the error term in a regression model has a constant variance B:the dependent variable in a regression model is binary C:the independent variables in a regression model are correlated D:the functional form of the error variances is known
A:有偏的,无偏的 B:无偏的,有偏的 C:无偏的,无偏的 D:有偏的,有偏的
AI参考:答案:B推理过程:选项A和D明显错误,因为样本中排除掉一些家庭后,剩下的家庭数量不同,所以OLS估计出来的结果是有偏的。选项C也不对,因为排除掉一些样本后,剩下样本的代表性就降低了,所以估计出来的结果是有偏的。所以只有B是正确的。第一个空是根据图表的信息来填写的。我们可以发现对于每一个观察到的特征(即每一列数据),他们的平方差都非常接近,并且其平方差总体趋势也是逐步变大的,这是因为观察对象是从最初的较为多元的数据,随着对数据进行不断地选择剔除(年龄大于等于25岁且储蓄小于等于25000美元的家庭),最终剩下的是更为集中和一致的数据。因此,排除掉一些样本后,剩下的样本在总体特征上是有偏的。第二个空是根据题目要求来填写的。题目要求我们排除掉储蓄超过每年25000美元以上的家庭后,估计结果与没有剔除之前的结果进行比较。此时我们的样本在特征上有一定的偏性(即偏向储蓄低于25000美元的家庭),而且这样的偏性影响了我们估计出的结果的精度。综上所述,正确答案是B:无偏的,有偏的。'
A:the intercept parameter is zero B:all the slope parameters are positive C:the independent variables are binary D:all the slope parameters are zero
A:by multiplying by its mean. B:by subtracting off its mean and dividing by its standard deviation. C:by multiplying by its standard deviation. D:by subtracting off its mean and multiplying by its standard deviation.
AI参考:正确答案是:B: by subtracting off its mean and dividing by its standard deviation.根据题干中的描述,变量在样本中被标准化,即通过减去其均值并除以标准差来实现。因此,选项B是正确的。其他选项中,A、C、D都与题干描述不符。'
A:随机抽样 B:不存在完全共线性 C:误差项的条件均值为0 D:线性于参数
A:控制变量 B:滞后变量 C:内生变量 D:外生变量 E:联合收获型
A:被解释变量 B:响应变量 C:回归元 D:回归子
AI参考:正确选项是【A:被解释变量】。在回归方程中,因变量y通常被称为被解释变量,它是通过预测或测量得到的,而自变量x则是解释变量,它对因变量y的影响被建模并用于预测。因此,选项A“被解释变量”是正确的答案。选项B“响应变量”通常用于描述实验设计中因变量在特定条件下的反应,与回归方程中的因变量不是一个概念。选项C和D也不是回归方程中的常用术语。'
A:经验性 B:随机性 C:确定性 D:灵活性 E:动态性
A:设定和检验模型 B:检验和发展经济理论 C:结构分析 D:政策评价 E:经济预测
A:判定系数增量贡献法 B:DW检验 C:样本分段比较法 D:残差回归检验法 E:方差膨胀因子检验法
A:经济统计学 B:数理经济学 C:经济学 D:统计学 E:任意角度
A:精确性 B:线性 C:无偏性 D:一致性 E:有效性
A:对 B:错
A:对 B:错
AI参考:答案为“对”。F统计量是一种常用的检验样本统计数据分布情况的指标,其计算公式所提供的链接中展示了F统计量的计算公式,即题干所给的图片内容。所以,该判断题正确,答案为A。'
A:对 B:错
AI参考:答案是B:错。根据题目描述,如果t统计量的计算值大于临界值,我们会倾向于拒绝原假设(H0),而不是接受备择假设(H1)。所以这个表述是错误的。'
A:对 B:错
A:错 B:对
A:错 B:对
AI参考:答案是B:对。准极大似然估计是在没有假定泊松分布完全正确的情况下使用泊松MLE的一种方法。因此,答案为B,表示正确。'
A:错 B:对
A:对 B:错
A:对 B:错
A:对 B:错
A:错 B:对
A:对 B:错
A:对 B:错
A:对 B:错
A:对 B:错
A:错 B:对
A:错 B:对
AI参考:答案:B。普通最小二乘法(OLS)是计量经济学中常用的计量模型之一,所以该题答案是B,表示正确。'
A:错 B:对
温馨提示支付 ¥1.45 元后可查看付费内容,请先翻页预览!

