提示:内容已经过期谨慎付费,点击上方查看最新答案
高等数理统计
- 单参数指数型分布族是指分布族中只有一个未知参数的分布族. ( )
- 令
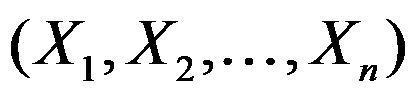 是来自于两点分布的简单随机样本,
是来自于两点分布的简单随机样本,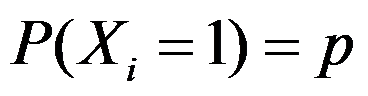 ,
,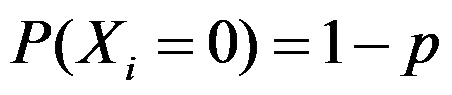 ,其中
,其中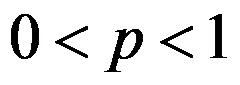 为未知参数. 用
为未知参数. 用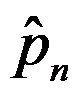 表示
表示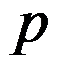 的极大似然估计,那么
的极大似然估计,那么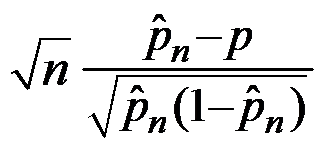 满足渐近正态性(当样本容量趋于无穷时).( )
满足渐近正态性(当样本容量趋于无穷时).( ) - 假设总体
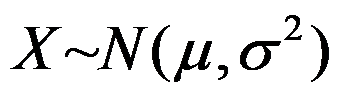 ,
, 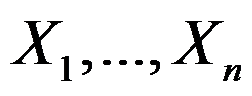 为来自
为来自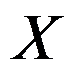 的样本.若参数
的样本.若参数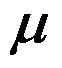 的置信水平为
的置信水平为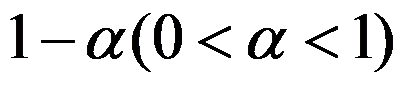 的双侧置信区间包含0, 则在显著性水平
的双侧置信区间包含0, 则在显著性水平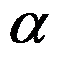 下接受假设检验
下接受假设检验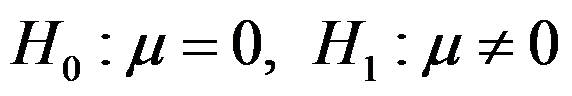 的原假设. ( )
的原假设. ( ) - 设样本
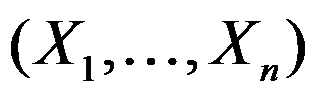 的分布族为
的分布族为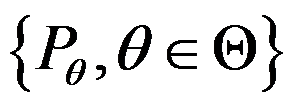 ,
, 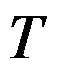 是充分完全统计量.
是充分完全统计量. 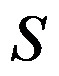 是另一个统计量,它的分布不依赖于参数
是另一个统计量,它的分布不依赖于参数 . 则统计量和
. 则统计量和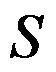 相互独立. ( )
相互独立. ( ) - 设
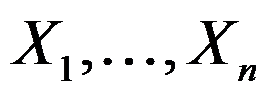 为取自参数为
为取自参数为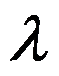 的Poisson分布的独立同分布样本, 记
的Poisson分布的独立同分布样本, 记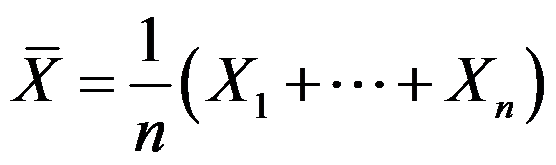 ,
, 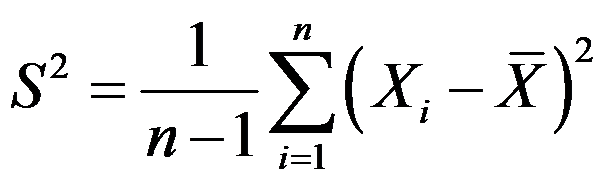 . 则
. 则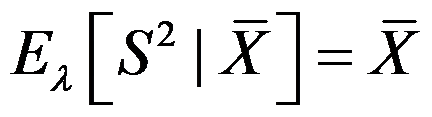 . ( )
. ( ) - 为了研究导致死亡的结核病的类型和性别有没有关系,调查了3583个因结核病死亡的人组成的样本,数据如下:
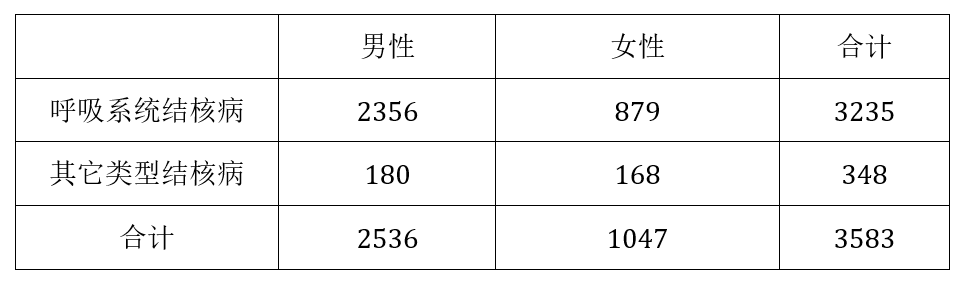
根据数据, 在检验水平 下, 应该判断导致死亡的结核病类型和性别无关 (已知
下, 应该判断导致死亡的结核病类型和性别无关 (已知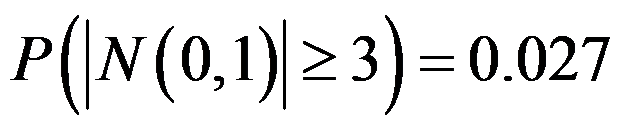 , 其中
, 其中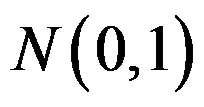 为标准正态变量. ( )
为标准正态变量. ( ) - 在同样的置信水平下,对于某参数
 构造置信区间,利用同一个样本,其单侧置信下限一定
构造置信区间,利用同一个样本,其单侧置信下限一定
小于等于双侧置信区间的左端点,大于等于双侧置信区间的左端点. ( ) - 对于正态总体标准差和方差的区间估计,可以采用同一个枢轴量. ( )
- 无偏估计量的均方误差一定比有偏估计量的均方误差小. ( )
- 设样本
 的分布族为
的分布族为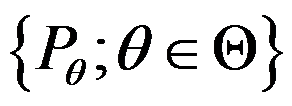 ,
, 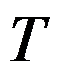 是充分完全统计量,
是充分完全统计量, 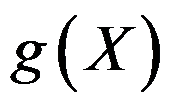 ,
,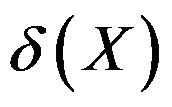 是两个统计量, 且满足
是两个统计量, 且满足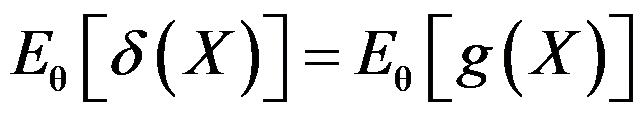 ,
,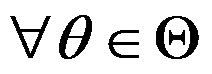 . 那么
. 那么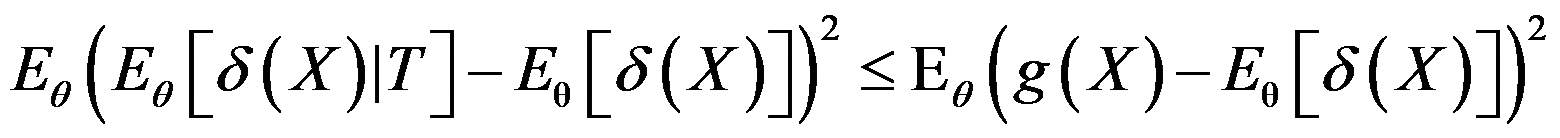 .
.
( ) - 令
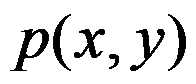 是二元随机向量的联合概率密度函数,当
是二元随机向量的联合概率密度函数,当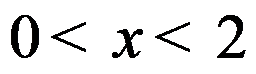 ,
,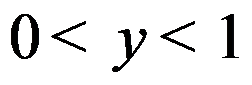 时,
时,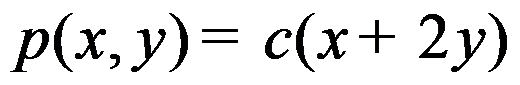 ;其它情况下,
;其它情况下,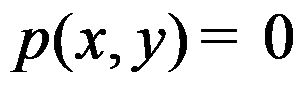 . 那么
. 那么 等于( ).
等于( ). - 从期望为
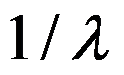 的指数总体
的指数总体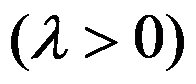 中抽取简单随机样本
中抽取简单随机样本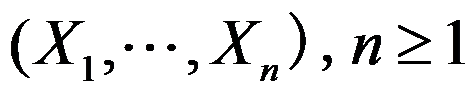 , 记样本均值为
, 记样本均值为 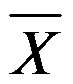 , 则
, 则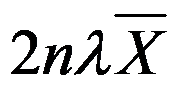 服从 ( )
服从 ( ) - 在相同条件下测试两种枪弹的枪速(单位:m/s),设两种枪弹的枪速数据来自两个独立总体
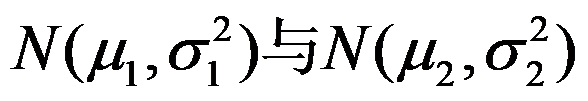 ,且样本间也相互独立.
,且样本间也相互独立. 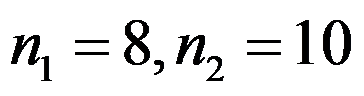 为样本容量,
为样本容量,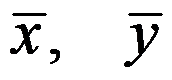 为样本均值的观测值,
为样本均值的观测值,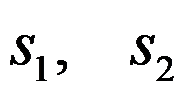 为样本标准差的观测值. 则对于假设检验问题
为样本标准差的观测值. 则对于假设检验问题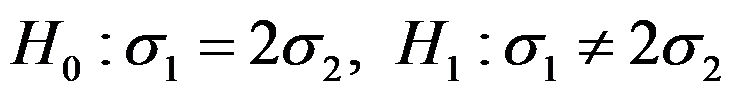 , 其拒绝域为( ).
, 其拒绝域为( ). - 设
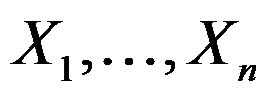 为取自正态总体
为取自正态总体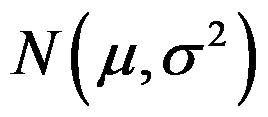 的独立同分布样本,
的独立同分布样本, 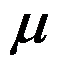 已知. 考察假设检验问题
已知. 考察假设检验问题 ,
,
其中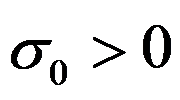 为一已知实数. 记其样本均值为
为一已知实数. 记其样本均值为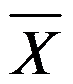 , 观测值为
, 观测值为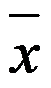 . 则显著性水平为
. 则显著性水平为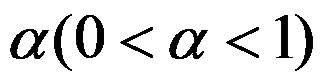 的一致最优无偏检验的拒绝域为( ).
的一致最优无偏检验的拒绝域为( ). - 设总体
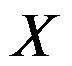 的分布属于正态分布族
的分布属于正态分布族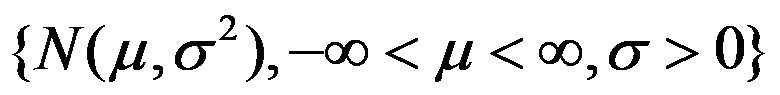 ,来自该总体的简单随机样本
,来自该总体的简单随机样本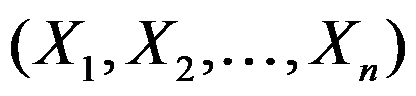 ,
, ,记其样本均值为,样本方差为
,记其样本均值为,样本方差为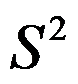 ,则
,则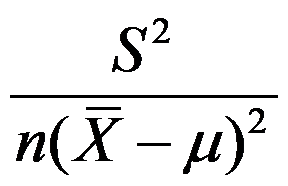 的分布为( ).
的分布为( ). - 总体
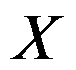 的分布列为
的分布列为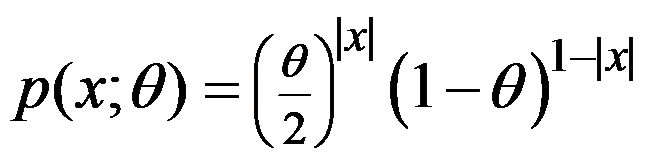 ,
,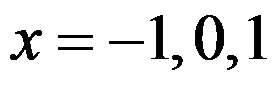 ;
;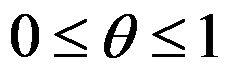 为未知参数.
为未知参数. 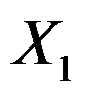 是来自该总体的样本,定义函数
是来自该总体的样本,定义函数 为:当
为:当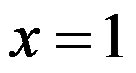 时,
时,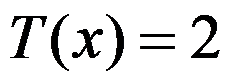 ;当
;当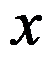 为其它值时,
为其它值时,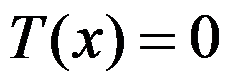 .则以下为
.则以下为 的无偏估计的有( ).
的无偏估计的有( ). - 总体的概率密度函数为
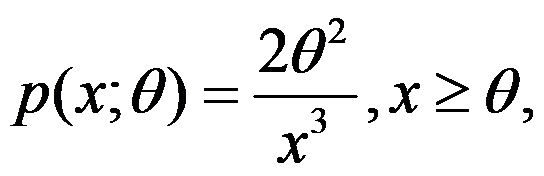 其中
其中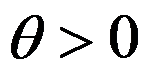 为未知参数, 来自该总体的简单随机样本,则以下统计量为
为未知参数, 来自该总体的简单随机样本,则以下统计量为 的矩法估计量是( ).
的矩法估计量是( ). - 设
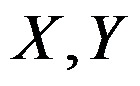 为独立样本,
为独立样本, 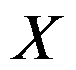 服从参数为
服从参数为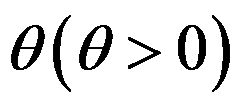 的指数分布, 密度函数为
的指数分布, 密度函数为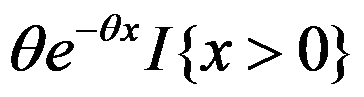 ,
, 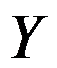 服从参数为
服从参数为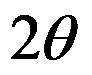 的指数分布. 考察假设检验问题
的指数分布. 考察假设检验问题 ,
,
则显著性水平为的一致最优检验可由下述统计量构造( ). - 总体的概率密度函数为
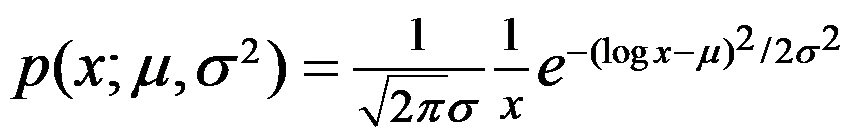 ,
,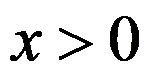 ,即为来自对数正态分布族, 其中
,即为来自对数正态分布族, 其中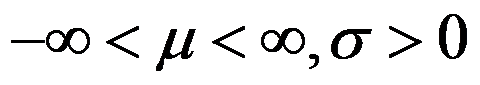 为未知参数, 来自该总体的简单随机样本
为未知参数, 来自该总体的简单随机样本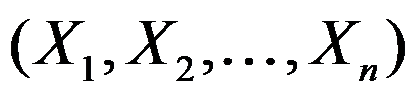 ,
,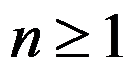 , 记样本均值为,则
, 记样本均值为,则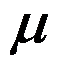 的极大似然估计量为( ).
的极大似然估计量为( ). - 关于分布的上
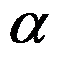 分位数
分位数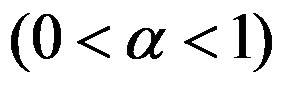 , 下列表述中不正确的是( )
, 下列表述中不正确的是( ) - 若总体服从期望为1的指数分布,来自该总体的简单随机样本
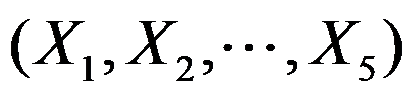 ,
,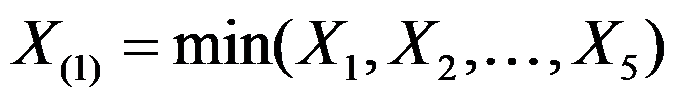 为最小次序统计量, 则随机变量
为最小次序统计量, 则随机变量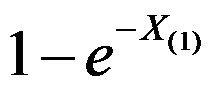 服从( ).
服从( ). - 总体的概率密度函数为
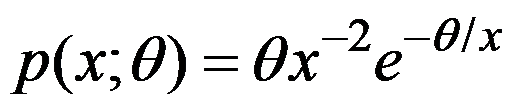 ,
,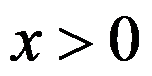 ,其中为未知参数, 来自该总体的简单随机样本,, 则
,其中为未知参数, 来自该总体的简单随机样本,, 则 的极大似然估计量为( ).
的极大似然估计量为( ). - 令
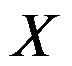 和
和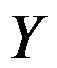 是独立标准正态随机变量,定义随机变量
是独立标准正态随机变量,定义随机变量 如下:当
如下:当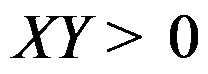 时,
时,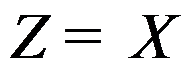 ;当
;当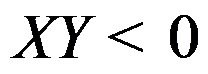 时,
时,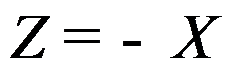 。下列结论正确的是( ).
。下列结论正确的是( ). - 令
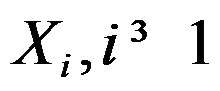 是一列独立同分布随机变量序列,
是一列独立同分布随机变量序列,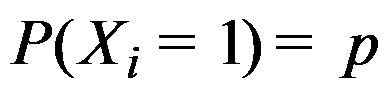 ,
,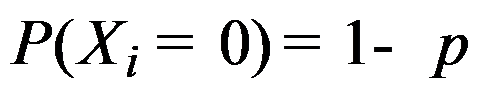 ,
, . 令
. 令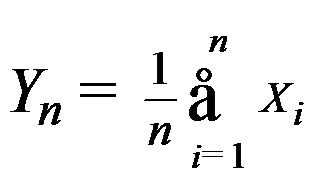 , 则下列结论正确的有( ).
, 则下列结论正确的有( ). - 二维总体
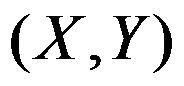 的联合概率密度函数为
的联合概率密度函数为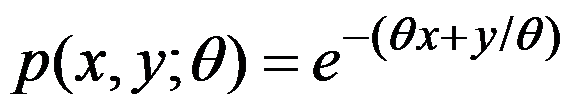 ,
,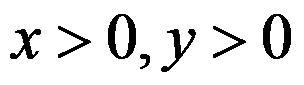 .令
.令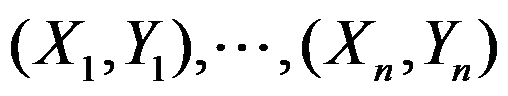 是来自于该总体的简单随机样本.定义
是来自于该总体的简单随机样本.定义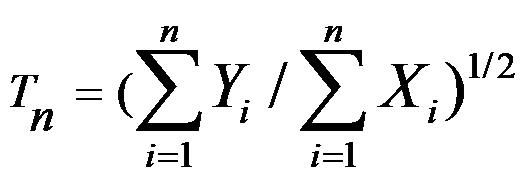 . 则下列结论正确的有( ).
. 则下列结论正确的有( ). - 下列函数可以成为分布函数的有( ).
- 总体
 的分布属于正态分布族
的分布属于正态分布族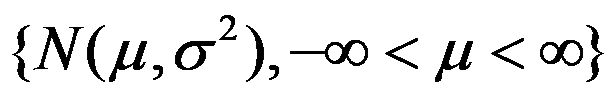 , 其中
, 其中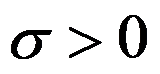 已知,来自该总体的简单随机样本,,记其样本均值为,样本方差为,在构造
已知,来自该总体的简单随机样本,,记其样本均值为,样本方差为,在构造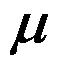 的置信区间时,可采用的枢轴量有( ).
的置信区间时,可采用的枢轴量有( ). - 令
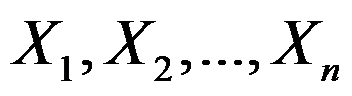 是来自正态总体
是来自正态总体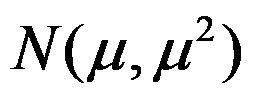 (其中参数
(其中参数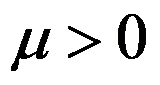 未知)的简单随机样本,那么
未知)的简单随机样本,那么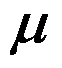 的无偏估计有( ).
的无偏估计有( ). - 令
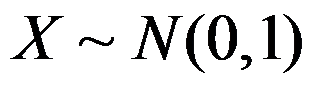 ,
,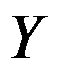 为离散型随机变量,分布列为
为离散型随机变量,分布列为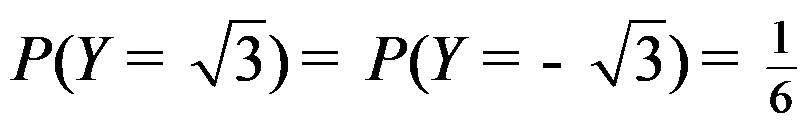 ,
,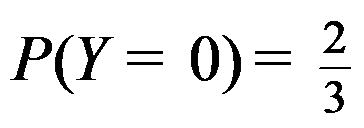 。 则下列结论正确的有( ).
。 则下列结论正确的有( ). - 假设总体
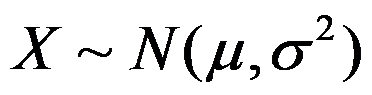 ,
, 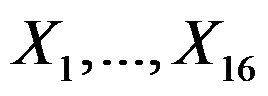 为来自的样本,根据样本观测值得样本均值
为来自的样本,根据样本观测值得样本均值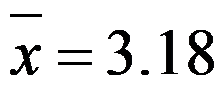 和样本标准差
和样本标准差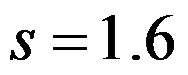 . 则下列说法正确的有( ).
. 则下列说法正确的有( ). - 下列为参数分布族的有( )
- 若随机变量
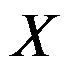 服从
服从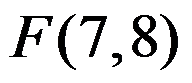 ,且已知
,且已知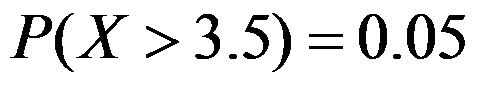 ,则下列结论正确的是( ).
,则下列结论正确的是( ). - 设总体有
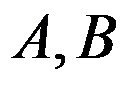 两种属性,
两种属性, 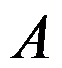 属性分
属性分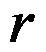 类
类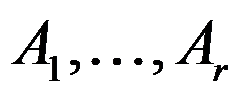 ,
,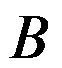 属性分
属性分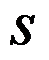 类
类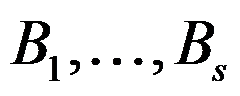 . 为检验属性是否独立, 随机抽取
. 为检验属性是否独立, 随机抽取 个独立同分布的样本, 记
个独立同分布的样本, 记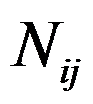 为属性在
为属性在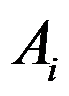 类、属性在
类、属性在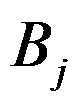 类的样本个数. 考察列联表独立性检验, 下列说法正确的是( ).
类的样本个数. 考察列联表独立性检验, 下列说法正确的是( ). - 对于容量大于1的简单随机样本而言,其样本均值,样本方差,下面说法正确的有 ( ).
A:错 B:对
答案:错
A:错 B:对
AI参考:答案:B推理过程:样本自相关和随机变量的样本均值为条件,参数为随机变量的未知函数时满足正态性我还能怎么样啊一般说“我还能怎么样啊”,说明之前可能已经做出了各种尝试和努力,但是情况依然没有改变。这是一种无力和失望的表达方式。这句话可以用来表达一种无奈的情绪,可以用于面对困境时的自我安慰或自我鼓励。同时,也可以用来提醒自己不要放弃,要继续坚持下去。总之,这句话表达了一种无力和失望的情绪,但同时也提醒自己不要放弃,要继续坚持下去。可以根据具体情况灵活运用。'
A:对 B:错
AI参考:这个问题的关键在于理解置信区间和原假设的含义以及如何在显著性水平下进行假设检验。首先,根据题意,参数的置信水平为双侧置信区间包含0。这意味着在给定的置信水平下,我们相信这个参数的值在区间的上下限之间,包括0。其次,原假设是在进行假设检验中,我们想要确认的假设,通常是“两个样本之间没有显著差异”或者“两个样本的参数值没有显著差异”。在显著性水平为α的情况下,如果我们的检验结果支持原假设(即,在给定的置信水平下,参数值在区间内包括0),那么我们就可以在显著性水平α下接受原假设。因此,根据题意和上述解释,答案应为:A:对。在这个问题中,由于置信区间包含0并且在显著性水平下支持原假设,所以我们可以接受原假设。'
A:错 B:对
AI参考:题目中给出了一个样本分布族和一个充分完全统计量,并说明另一个统计量不依赖于参数。根据这些信息,我们可以得出以下结论:由于充分完全统计量是独立的于样本参数的,那么另一个统计量与样本参数也无关。这意味着两个统计量之间没有相互依赖性,因此它们是相互独立的。因此,答案是B:对。'
A:错 B:对
AI参考:B:对。根据题意,
、是Poisson分布的独立同分布样本,因此它们的概率密度函数应该相同。根据题目给出的图片,可以发现与的概率密度函数形状相同,只是大小不同,因此可以判断选项B为正确答案。'A:错 B:对
AI参考:答案是B:对。根据问题描述,样本数据表明导致死亡的结核病类型和性别之间没有关系,所以应该判断两者无关。由于数据已经给出,不需要进行进一步的分析。因此,答案为B。'
A:对 B:错
答案:对
A:错 B:对
答案:对
A:错 B:对
答案:错
A:对 B:错
AI参考:正确答案是A,即题目所述的情况是正确的。根据题目中的描述,样本分布族为某个分布族,充分完全统计量
,两个统计量和满足某种关系。根据充分完全统计量的定义,如果一个统计量是充分完全的,那么它对于样本空间的任何划分都能给出样本点是否属于某个类的信息。因此,题目中的情况是正确的。'A: B: C: D:
AI参考:根据题目描述,
是一个二元随机向量的联合概率密度函数中的某个像素值,它取决于其他三个图像的像素值。由于题目没有给出具体的像素值和对应的概率密度函数,我们无法直接确定答案。因此,正确答案是D:无法确定。'A: B: C: D:
答案:对AI参考:正确答案是A:期望为
的正态分布。样本均值是一个随机变量,其期望值(即均值)为期望为的正态分布,符合正态分布的特征。因此,样本均值服从正态分布。'A: B: C: D:
AI参考:答案:B解析:当μ相同且差异不显著,考虑的是二者均值间是否有显著性差异时,拒绝域为{|样本均值<μ1或样本均值>μ2},其中μ1和μ2分别为两个总体均值.本题中,已知两种枪弹的枪速数据来自两个独立总体,且样本容量相同,所以拒绝域为{|样本均值<样本均值的观测值或样本均值>样本均值的观测值的√n倍}.其中n为样本容量。由题目图可知样本均值的观测值为59,故选B。'
A: B: C: D:
的情况下,我们要做的是最优一致无偏检验,来拒绝或接受原假设。由于原假设为总体均值等于某个已知值,所以拒绝域应为样本均值小于该已知值。即,拒绝域为: ≤ 所以,正确答案是C。'A: B: C: D:
A: B: C: D:
AI参考:从题干描述来看,给出的样本是随机抽样得到的,因此每一个样本值都是总体的一部分。函数
是描述样本分布的函数,它根据样本值来计算相应的结果。对于未知参数,无偏估计是指样本统计量与参数的真实值之间的平均误差最小。对于给定的样本,函数根据样本分布来计算参数的无偏估计。选项A中,根据题目描述,样本总体是均匀分布的,而给出的样本也是随机的,因此总体应该是均匀分布的。而函数描述的是当样本值为某个值时,对应的参数值是多少。因此,选项A中的无偏估计应该是指当样本值为某个值时,对应的参数值与真实值的平均误差最小。因此,选项A是正确答案。'A: B: C: D:
A: B: C: D:
A: B: C: D:
AI参考:正确答案是C。根据题意,总体服从对数正态分布族,其概率密度函数为题目给出的三个图像。样本均值记为μ,则样本数据满足均值μ的对数正态分布。因此,样本数据的极大似然估计量就是对数正态分布族中的未知参数θ。由于题目中给出的是对数正态分布族,因此未知参数θ为正数。因此,极大似然估计量为:θ ≈ log(μ)其中μ为样本均值。因此,答案为C。'
A: B: C: D:
AI参考:关于分布的上分位数,下列表述中不正确的是D选项。因为分位数是按照从小到大的顺序排列的,所以最小的上分位数是第一分位数,即最小值所在的那个百分位数。因此选项D表述不正确。其他选项A、B、C都是正确的描述。'
A: B: C: D:
A: B: C: D:
A:不是二元正态分布 B:是正态分布 C:是柯西分布 D:是二元正态分布
AI参考:根据所给的图像和描述,可以推断出这三个随机变量是独立标准正态分布。由于这三个随机变量的平均值是相等的(假设为μ),方差也相等(假设为σ^2),并且相互独立,因此它们满足正态分布的三个基本条件。所以,选项B是正确的。需要注意的是,虽然这三个随机变量满足正态分布的条件,但它们不一定是二元正态分布。二元正态分布要求两个随机变量之间存在某种特定的关系,而不仅仅是满足正态分布的条件。因此,正确答案是B:是正态分布。'
A:依分布收敛于 B:依分布收敛于 C:当时,依分布收敛于 D:当时,依分布收敛于
AI参考:正确答案是ABD。根据题意,给出的图片序列是一列独立同分布的随机变量序列,其中每个图片的宽度和高度都是随机变量。由于每个图片的宽度和高度都是独立同分布的随机变量,因此它们是独立同分布的。选项A和B是正确的,因为每个图片的宽度和高度都是独立同分布的随机变量,它们之间没有关系。因此,这个序列按照宽度和高度独立同分布的分布收敛到图像上所有点的均值,这个值对于给定的任何分布都有相同的概率分布,也就是说它是每个像素值上的期望。选项C和D也是正确的,因为当时,根据图像的性质,它的像素值服从某个分布,例如正态分布或泊松分布等。这个序列按照给定的分布收敛到这个像素值上的期望。因此,选项C和D都是正确的。综上所述,选项A、B、C和D都是正确的。'
A:是的无偏估计 B:是的极大似然估计 C:是的无偏估计 D:是的极大似然估计
AI参考:选项C和D是正确的。对于二维总体的问题,我们需要考虑的是联合概率密度函数。由题可知,该联合概率密度函数为已知。简单随机抽样得到的样本是来自该总体的随机样本,因此,样本均值也是随机变量。对于选项A,样本均值不是无偏估计量,因为其方差不一定是1。对于选项B,由于样本均值不是最大似然估计量,因此极大似然估计量也不一定是样本均值。对于选项C和D,当总体联合概率密度函数已知时,样本均值的数学期望等于总体均值,因此样本均值是无偏估计量。对于选项D,由于样本是来自该总体的随机样本,因此极大似然估计量也是样本均值。综上所述,选项C和D是正确的。'
A: B: C: D:
AI参考:正确选项为C和D。分布函数是概率论中重要的概念,它是一个定义在所有可能结果的全体上的实值函数。选项A和B并不是实数函数,不符合分布函数的定义。选项C和D是实数函数,可以成为分布函数。因此,正确选项为C和D。'
A: B: C: D:
A: B: C: D:
AI参考:答案为C。无偏估计是对参数的数学期望等于参数真值的估计,所以本题答案是C,因为样本均值等于总体均值,所以样本均值是无偏估计。样本均值是描述样本特征的一个重要统计量,通过样本均值可以对总体均值进行估计。因此,选项C是正确的。'
A: B: C: D:
AI参考:根据题目所给的图像,我们可以看到以下四个选项:A、B、C和D。首先,我们可以确认这两个
A:的置信水平为0.95的单侧置信下限(保留两位小数)为2.48 B:的置信水平为0.95的单侧置信上限(保留两位小数)为3.88 C:的置信水平为0.95的双侧最优置信区间(保留两位小数)为[2.33,4.03] D:的置信水平为0.95的双侧等尾置信区间(保留两位小数)为[2.33,4.03]
AI参考:根据题目中给出的样本均值和标准差,可以得出以下结论:A. 的置信水平为0.95的单侧置信下限(保留两位小数)为:2.483,而非选项中的2.48。B. 的置信水平为0.95的单侧置信上限(保留两位小数)为:3.869,而非选项中的3.88。C. 的双侧最优置信区间为[2.33, 4.03],这是基于样本均值和标准差计算的,置信水平为0.95,双侧检验。D. 的双侧等尾置信区间为[2.33, 4.03],这是基于样本均值和标准差计算的,置信水平为0.95,双侧等尾检验。因此,正确选项为C和D。'
A: B:、 C: D:
AI参考:正确选项为:B: 平均数、C: 标准差、D: 方差。参数分布族是指一组描述数据分布特征的参数,通常包括平均数、标准差和方差等。其中,平均数表示数据集中趋势,标准差和方差则用于衡量数据的离散程度。因此,选项B、C、D均属于参数分布族。选项A不属于参数分布族,因为它描述的是数据的频率分布情况。'
A: B: C: D:
AI参考:答案为B,D。由已知条件可得该随机变量可能取的值为正数和负数。由对称性可知其期望和方差也是对称的,由于是服从卡方分布,可知其期望和方差均非负,由于取值为正负两数,则该分布具有绝对中性,方差可能为零,根据题目中给出的三个式子可知选项B和D正确。因此,答案为B和D。'
A:设获得了列联表独立性检验的检验统计量的观测值, 那么检验的值为, 其中为标准正态变量 B:检验统计量为其中 C:当属性不独立时, 列联表独立性检验的检验统计量的渐近分布是分布 D:水平为的检验的拒绝域为, 其中为列联表独立性检验的检验统计量的观测值
A:样本均值一定是统计量,样本方差则不一定 B:两者都是统计量 C:两者都与样本有关,因此一定不独立 D:样本均值的期望有可能等于样本方差的期望

