- 相关关系指的是两事物之间的一种一一对应关系。( )
- 相关系数的伴随概率(P值)是0.768,说明可以认为变量间的相关性程度较弱(不相关)。( )
- 配对样本的一个特征是:两组样本的样本量相同。( )
- 单样本t检验作为假设检验的一种方法,其基本步骤与假设检验是完全相同的。( )
- Pearson简单相关系数用来度量定距型变量间的线性相关关系。( )
- 产品质量的检测问题,如评估灯泡的使用寿命,可以采用参数检验分析方法。( )
- 简单相关系数等于零说明变量之间不相关。( )
- 分析多选项问题时必须先按多选项二分法或多选项分类法将多选项问题分解成若干个问题。( )
- 数据个案排序是整行数据排序,而不是只对某列变量值排序。( )
- SPSS输出窗口由( )组成。
- 进行频数分析时,利用的工具包括( )
- 表示x和y之间线性回归方程的是( )。
- 指出下列哪些现象是相关关系( )。
- 请问是函数关系的是( )。
- ( )可以刻画离散程度。
- 对于一个共有7个选项的多选排序题(多选排序值可以只选部分选项进行排序),在SPSS中建立的变量个数最少是( )
- ( )是SPSS中可用的基本数据类型
- 通过( )可以达到将数据编辑窗口中的分组汇总数据还原为原始数据的目的。

- DW检验的零假设是(ρ为随机误差项的一阶相关系数)( )。
- 下列明显错误的是( )。
- 探索分析中不能生成的统计图形是( )
- 在高考志愿调查中,问你的报考志愿是哪那些大学,可以用( )分析。
- 有一组30位同学的语文、数学和英语三科考试成绩数据(变量名分别为X、Y、Z),三科的学分分别为5分、5分、3分。利用【转换】→【计算变量】菜单,用学分加权计算新变量“平均成绩”,则下列选项正确的是( )
- SPSS公司成立于( )
- ( )的功能是用来建立变量结构,定义变量属性的。
- SPSS数据文件的扩展名是( )
- 个案选取的方法中( )是按符合给定条件的数据进行选取个案。
- 产量(X-台)与单位产品成本(Y-元/台)之间的回归方程为Y=356-1.5X,这说明( )。
- 如果X和Y在统计上独立,则相关系数等于( )。
- SPSS单因素方差分析法应先对方差进行方差齐性检验。( )
- 样本标准差是表示变量取值距均值的平均离散程度的统计量( )
- 自相关问题的处理可以采用加权最小二乘法。( )
- 对于变量中为空的数据,也必须定义缺失值。( )
- 在进行两独立样本t检验之前,正确组织数据是一个非常关键的任务,必须建立一个分组变量。( )
- 横向合并数据文件是依据两份数据文件的个案进行数据对接。( )
- 受极端值影响的描述统计量是( )
- 交叉列联表中的内容包括( )
- SPSS程序运行方式需要做( )工作
- 下列( )属于多选项问题。
- 相关分析的主要内容有( )
- SPSS能够将数据编辑窗口中的数据保存成多种格式的数据文件,常见的有( )
- 频数分析中常用的统计图包括( )
- 下面( )可以用来观察频数分布。
- 变量名最多包含( )个字节
- DW的取值范围是( )。
- 下列( )反映了回归分析的一般步骤。①确定回归模型②建立回归方程③确定回归方程的解释变量和被解释变量④利用回归方程进行预测⑤对回归方程进行各种检验
- SPSS的( )就是将数据编辑窗口中数据的行列互换
- “回归”一词是( )国统计学家提出的。
- ( )的功能是定义SPSS数据的结构、录入编辑和管理待分析的数据。
- SPSS中绘制散点图应选择( )主窗口菜单。
- SPSS中得到的直方图上面可以附加正态分布曲线,便于与正态分布的比较。( )
- 单样本t检验的前提是样本来自的总体应服从或近似服从正态分布。( )
- SPSS个案选取时,【过滤】表示在未被选中的个案号码上打一个“\”标记,表示暂时筛掉。( )
- spearman和kendall相关系数都是非参数方法衡量变量的相关性。( )
- 为方便SPSS数据文件的横向合并,不同数据文件中数据含义不同的数据项,变量名应相同( )
- 纵向合并数据文件是依据两份数据文件的变量名进行数据对接。( )
- 多选项问题的分解通常有( )方法
- 关于相关分析与回归分析的区别与联系叙述正确的是( )
- 相关分析最常用的工具包括( )
- 回归模型的异方差常用检测方法有( )
- 利用SPSS进行频数分析时,频数分布表中内容的输出顺序可以有( )
- SPSS混合运行管理方式的特点是( )
- 统计学中,依据数据的测量尺度划分不包括( )
- 多因素方差分析是用来研究两个及两个以上控制变量是否对观测变量产生( )影响。
- 对“重新编码为不同变量”操作,下列叙述不正确的是( )
- 数据编辑窗口中的一行称为一个( )
- 输出窗口的主要功能有( )
- SPSS中提供的图形编辑功能是在( )窗口。
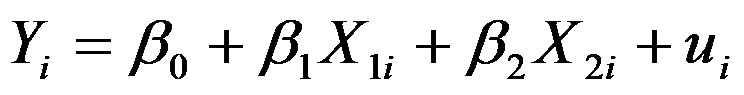
- 由已知变量计算生成新变量应选择( )。
- 回归分析可在( )菜单中找到。
- 在横向合并数据文件时,两个数据文件都必须事先按关键变量值( )
- 变量之间的关系可以分为两大类,它们是( )
- 相关关系是指( )
- SPSS的分析结果显示区可以分为目录区和内容区两个部分。( )
- 两总体方差是否相等是决定如何计算抽样分布方差的关键。( )
- SPSS数据的输入和结果的输出是在同一窗口进行的。( )
- Spearman等级相关系数可用来度量定序变量间的相关关系。( )
- 交叉分组下的频数分析可以分析多个变量联合分布的特征。( )
- 多选项二分法是将多选项问题中的每个答案设为一个SPSS变量。所以问题中有几个答案就应该设置几个变量。( )
- 假设检验不是推断统计的重要组成部分。( )
- 两配对样本t检验采用的检验统计量与单样本t检验类似。( )
- 下列哪些数据适合直接编制频数分布表( )
- 下列哪些不是SPSS中的数据类型?
- 下列回归模型说法中正确的是( )
- ( )统计量可以由SPSS描述统计过程直接计算得到。
- 排序可以实现的功能是( )
- 人们在研究影响广告效果的众多因素时,可以采用( )分析方法。
- 检验一组数据是否服从正态分布,可使用的检验方法是( )
- 有一组随机样本:CCDDDCCCCCDCCCDDDCCCDDDD,请问这组样本的游程数是( )
- 有两个学生信息文件中都包含学生学号变量,其余变量不同。文件1中三个个案,学生学号为4、5、6;文件2中5个个案,学生学号为1、4、6、7、8;在进行横向合并两个文件时,以文件1为当前数据,将文件2的变量横向添加到文件1。以“学号”为关键变量选择匹配关键变量的选项为“活动数据集为基准关键字的表”,则合并后的文件包含的学生学号个案为( )
- 方差齐性检验是对控制变量不同水平下各观测变量( )是否相等进行分析。
- 数据编辑窗口中的一列称为一个变量。( )
- 关键变量是两个数据文件中至少有一个相同的变量,该变量是两个数据文件横向拼接的依据。( )
- 在同一算术表达式中的常量及变量,数据类型不一致时也可以计算。( )
- 分类汇总的分类变量可以是多个,此时的分类汇总称为多重分类汇总。( )
- SPSS安装时通常选择典型安装。( )
- 交叉列联表中的行列变量类型可以是( )
- 利用SPSS进行数据分析的基本步骤可简单概括为( )
- 下面给出的t检验的结果P值 ( )表明接受原假设。显著性水平为0.05。
- 已知一元线性回归方程的判定系数为0.64,则解释变量与被解释变量间的线性相关系数为( )。
- 独立一定不相关,不相关一定独立。( )
- 录入编辑SPSS的数据内容在变量视图中完成。( )
- 数据中明显错误的数据可以看做缺失数据。( )
- 下列问题( )使用参数检验分析方法。
- 两配对样本t检验的前提( )
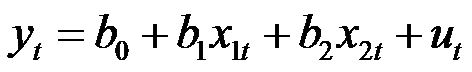
- 方差分析认为观测变量值的变化受两类因素的影响,分别是( )
- 复合条件表达式又称逻辑表达式。在逻辑运算中,下列( )运算最优先。
- 运用SPSS分析时,判断异常值时可以先对数据进行标准化处理得到Z,Z的绝对值大于3可以认为是异常值。( )
- 多元线性回归模型最有可能存在的问题是多重共线性。( )
- 变量值标签是对变量取值含义的解释说明信息,对于定类型和定距型数据尤为重要( )
- SPSS算术表达式是由( )等组成的式子。
- 表示尖峰分布的峰度值是( )
- SPSS语句窗口,在运行菜单中提供的程序执行方式有( )
- D-W检验,即杜宾-瓦尔森检验其最大优点为简单易行。如果DW值接近于零,则说明越倾向于无自相关。( )
- 常见的刻画离散程度的描述统计量有( )
- 相关系数r的取值范围是( )。
- 从下列颜色中选出你最喜爱的颜色,可以从红、 橙、黄、 绿、蓝、黑、紫中选择三种。在进行分析时如果采用多选项二分法设置变量,应该设置的变量数目是( )个。
- 利用SPSS进行数据分析的基本步骤包括建立数据文件、加工整理数据 、数据分析、解释分析结果。( )
- 多个配对样本的“Cochran的Q”检验的假设是多个配对样本来自多个总体的分布无显著差异。( )
- 假设检验推断过程依据的原理是小概率事件。( )
- 利用样本数据获得回归线通常有( )方法
- 卡方检验可用于( )
- 关于时间序列因素分解模型(Y-指标数据、T-长期趋势、S-季节变动、C-周期变动、I-不规则变动),可能的模型有( )
- ( )是访问和分析SPSS变量的唯一标识。
- 对数据可以进行多重拆分,类似于数据的多重排序。( )
- 在合并文件中自动生成的来源变量中,0表示来自当前文件,1表示来自第二份数据文件。( )
- 两个独立样本检验中,Kolmogorov-Smirnov Z检验的假设是两个独立样本来自的两总体的分布无显著差异。( )
- 两配对样本t检验与两独立样本t检验没有差别。( )
- 偏线性相关分析也称净相关分析。它在控制其他变量的线性影响的条件下分析两变量间的线性相关性。所采用的工具是偏线性相关系数(净相关系数)。( )
- 为研究某种降压药物的降压效果是否显著,可以采用单样本t检验方法。( )
- SPSS运行时不可以同时打开多个数据编辑窗口。( )
- 简单相关系数以数值的方式精确的反映了两个变量间线性相关的强弱程度。( )
- 全距也称极差,是数据的最大值与最小值之间的绝对差( )
- 变量名标签这个属性是可以省略的。( )
- 下列( )散点图可以表示多对变量间统计关系。
- 客观事物之间的关系可以分为( )
- 一组时间序列数据在一年中或超过一年以上,呈现周期和幅度大致一样的变动,有可能是以下哪些因素造成( )
- 下面偏度系数的值表明数据分布形态是左偏的是( )
- ( )可以刻画分布形态。
- 数据分析一般经过( )主要阶段。
- 刻画分布形态的描述统计量主要有( )
- 在菜单【转换】→【创建时间序列】命令中,不需要使用菜单【数据】→【定义日期】命令先创建日期变量的函数有( )
- SPSS的命名规则有( )
- 对于图形窗口说法正确的是( )
- 家庭住址、姓名等变量一般定义成( )数据类型。
- 在一次调查中,有一道10个选项的多选题,最多选5个选项。请问用选项数字代码录入方式,最少建立几个变量?
- D-W检验中,如果DW值等于4,则( )
- 判定系数的取值范围是( )。
- 定义性别变量时,假设用数值1表示男,用数值2表示女,需要使用到的工具是( )
- 回归分析的第一步是( )
- 将300名学生分成两组,用普通教学法和改进教学法分别在两组学生中进行一学期的英语教学,看两种方法在提高英语成绩方面有无明显差异。假定数据服从正态分布,在数据编辑窗口的( )菜单下完成。
- 对于输出窗口的结果,说法正确的是( )
- 调查问卷中的量表如何建立数据?
- 工资、年龄、考试成绩等变量一般定义成( )数据类型。
- 以下哪个图形适合展示连续型数值分布( )。
- 为检验某种治疗二型糖尿病新药的效果,选取了100名患者,测量了服药前的餐后两小时血糖数值和服药后餐后两小时血糖数值数据,比较服药前后血糖有无明显差异。已知服从正态分布,可采用( )。
- SPSS输出结果保存时的文件扩展名是( )
- 以下哪个方法与LSD方法基本相同 ( )
- 下列哪个不是多重共线性的检测方法?
- 根据计算的偏度值,是对称分布的是( )
- 单样本t检验中涉及的总体有( )个。
- 单因素方差分析的第二个基本步骤是( )。
- 下列样本模型中,哪一个模型通常是无效的( )
- 对大学毕业班的同学的学习成绩进行综合评价。可以依次计算每个同学的若干门专业课中有几门课程是优,几门是良,并以门次为权重进行分析。其中计算门次的过程就是一个( )过程。
- 在回归分析中,下列哪个不是异常值产生的原因是( )
- 在单因素方差分析中,用于两两比较时,以下哪个方法适用于假定方差齐性的( )
- 在利用筛选器变量选择个案时,筛选器变量取值为( )时,对应个案将被删除。
- SPSS中进行个案排序应选择( )菜单。
- SPSS的安装类型有( )
- 以下哪个变量的变量值不能转换成数字代码录入,并建立值标签?
- ( )筛选是解释变量边引入边剔除进入回归方程的过程。
- 多元线性回归分析中,反映回归平方和在因变量的总变差中所占比重的统计量是( )
- 在程序运行方式中,SPSS算术表达式中的字符型( )应该用引号引起来。
- 测度收入和储蓄、身高和体重等变量间的线性相关关系时可以采用( )相关系数。
- 关于“季节性因素”即季节指数,说法正确的是( )
- 有一组某企业5年各季度的销售数据,首先需要用到的数据预处理菜单是( )
- 关于移动平均项数,说法正确的是( )
- 可直接运用【分析】→【回归】菜单进行分析的时间序列数据是( )
- 季节变动分析必须首先要做的一步操作是( )
- 时间序列的构成要素( )
- 用指数平滑法得到的t+1期的预测值等于( )
- 关于移动平均说法正确的是( )
- 对数据进行移动平均需要用到的菜单( )
- 对数据进行指数平滑分析需要用到的菜单( )
- 下列( )属于相关关系。
- 简单散点图是表示( )变量间的统计关系的散点图。
- 严重的不完全多重共线性会导致如下的严重问题( )
- 使用时间序列数据建立回归模型,最有可能存在的问题是( )。
- 回归分析的主要内容有( )
- 对回归模型的检验,应包括( )。
- D-W检验,即杜宾-瓦尔森检验,用于检验时间序列回归模型的误差项中的一阶序列相关的统计量。如果DW值越接近于2,则( )
- 变量之间的依存关系,依据其紧密程度可分为( )。
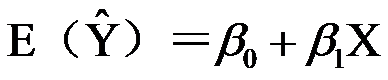
- 如果模型存在异方差性,仍然使用最小二乘法估计模型参数,则( )
- 10在一项健康试验中,利用三种生活方式在一个月时间内,记录了肥胖病人每日的减重量,检验三种生活方式对于减肥的效果是否有显著差异?可以采用( )分析方法。
- 能检验总体是否服从正态分布的菜单是( )
- 为研究某种减肥茶减肥效果是否显著,数据分布未知,可以采用( )分析方法。
- “1-样本 K-S”菜单提供了哪些检验分布( )
- 二项式检验中,对于非二分值数据的检验,下列叙述正确的是( )
- 有甲乙两种安眠药,独立观察20个病人,10人服甲药、10人服乙药,比较他们服药后延长的睡眠时间有无显著性差异?可以采用( )分析方法。
- 对于非参数检验方法叙述正确的是( )
- 某村村民对四个村主任候选人(ABCD)的赞同与否进行调查,检验四个候选人在村民眼中有没有区别。可以采用( )分析方法。
- 游程检验可以用于( )
- 假定有一个容量为10的样本,对于它的每一个观察值,按一定的标准去分为两种符号,例如根据它是大于还是小于样本中位数(或均值)而给定某种符号,如大于记作A,小于记作B,如果我们把这些符号按抽样时被抽出的先后顺序排列,出现如下情况:ABAABAABBB,请问这组样本序列的游程数是( )个。
- 在多因素方差分析结果中,以下关系正确的是( )
- 多因素方差分析有( )
- 单因素方差分析只涉及( )
- 方差分析中,用于检测的F统计量是( )
- 方差分析是检验( )
- 方差分析的基本假设是( )
- 方差分析中如果Levene检验拒绝原假设,则意味着( )
- 方差分析的主要目的是判断( )
- 以下结果判断正确的是( )
- 方差分析如果拒绝原假设,则意味着( )
- 对于均值比较的配对样本检验,需要假设( )
- 对于参数方法的独立样本检验,需要假设( )
- 对于独立样本检验,数据特征是( )
- 开发商在两个城市随机选取家庭进行收入调查,这里两个城市的家庭进行收入数据是( )
- 在独立样本T检验输出结果中,如果Levene检验结果不显著,则( )
- 在均值过程操作中,如果对“选项”选择默认操作,最终输出的统计量是( )
- 均值比较时,对于配对样本检验问题采用( )
- 为了检验某新药降低高血压的作用,随机挑选出一群患者,记录服药前和服药后的血压数据,这里服药前和服药后的血压数据是( )
- 在均值过程操作中,在“自变量列表”栏应选择( )
- 均值比较中,单样本检验说法正确的是( )
- 关于直方图与条形图叙述正确的是( )
- 适用于分类和顺序型数据的统计图形是( )
- 有效百分比是各组频数占( )的百分比。
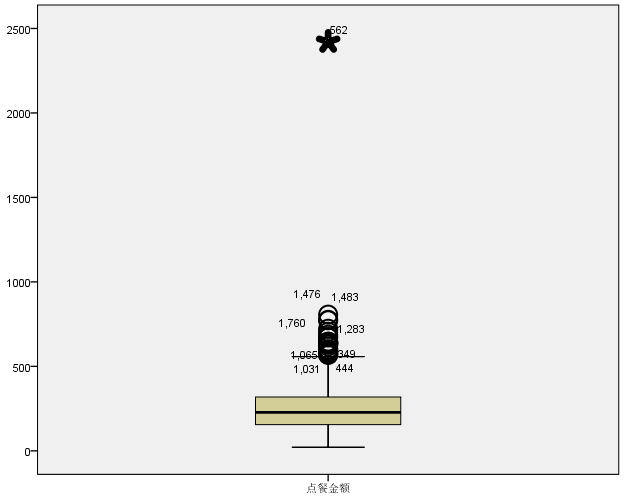
- 对于连续数值型数据编制频数分布表时,首先应该( )
- 探索分析的作用是( )
- 不受数据极端值影响的描述统计量是( )
- SPSS中的频数分布表包括的内容有( )
- 关于列联表分析,下列说法正确的是( )
- 连续数值型数据可选用( )
- 可实现连续型数值数据分组功能的菜单是( )
- 用A、B、C三个已知变量加权求均值计算新变量D,其中A变量有个别个案为缺失值,则新变量D对应个案数值为( )
- 在SPSS数据文件中存储了A、B、C三个变量,根据分析需求,要把A、B、C三个变量加权(A权数:0.3,B权数:0.4, C权数:0.3)综合成新变量D。以下做法正确的是( )
- 符号“&”是( )
- 在变量“服务满意度”中录入值为1、2、3、4、5,分别表示非常满意、满意、一般、不满意和非常不满意。如果计算平均分值时,“服务满意度”平均分越低表示越满意,这与通常认知不符。因此,需要对“服务满意度”取值调整,将原来录入的1、2、3、4、5对应改为5、4、3、2、1表示非常满意、满意、一般、不满意和非常不满意。下列哪些功能菜单可以实现?( )
- “对个案内的值计数”菜单可以实现( )
- 搜集了某地区5年的服务业产值月度数据,其中第5年2月份的数据缺失。另外5年数据分布呈现线性上升趋势(无季节变动),那么在【转换】→【替换缺失值】菜单中,适用的缺失值替换方法是( )
- SPSS基本运算有( ):
- 对“季节性差分”函数说法正确的是( )
- 在可视离散化操作中,如果选择“基于已扫描个案的平均和选定标准差处的分割点”进行分组,则以下叙述正确的是( )
- 菜单【数据】→【拆分文件】的功能是( )
- 利用【数据】→【加权个案】菜单对数据加权操作时,权变量可以是( )
- 某个SPSS数据文件中存储了100家上市公司1-12月的月财务报表数据(1200个个案,每个企业有1-12月12个个案),利用( )菜单功能可以最快地只保留6月份的财务数据。文件中的变量:公司名称、纳税人识别号码、月份(用1-12个数字表示)以及其他财务指标变量。
- 两个数据文件进行纵向合并(添加个案)时,应满足( )
- 将二手列联表数据录入SPSS中,应遵循以下原则( )
- 下列关于数据排序正确的是( )
- 将数据文件A的所有变量属性复制给数据文件B,需要用到的菜单是( )
- 在同一数据文件中,将变量A的属性复制给变量B,需要用到的菜单是( )
- SPSS数据文件中多个个案为相同个案,可以使用( )菜单实现删除重复个案。
- 两个数据文件进行横向合并(添加变量)时,应满足( )
- SPSS21中变量类型有( )
- 下列哪些变量适合定义成定序型变量(序号)?( )
- 在SPSS中导入固定列宽格式文本,要求文本数据( )
- 下列哪些情况有可能需要在SPSS变量属性中定义缺失值?( )
- 在SPSS中导入固定分隔符格式文本,要求文本数据( )
- 需要利用“添加ODBC数据源”功能导入到SPSS的数据文件是( )
- 下列哪些变量适合定义成定距型变量(度量)?( )
- 下列哪些变量适合定义成定类型变量(名义)?( )
- 下列变量名称是合法命名的是( )
- SPSS中标签的含义正确的是( )
- ( )的功能是显示管理SPSS统计分析结果、报表及图形。
- 数据编辑窗口叙述正确的是( )
- 可用于变量属性的输入和修改的窗口是( )
- ( )是SPSS为用户提供的基本运行方式。
- SPSS数据编辑窗口由( )组成。
- 数据视图用于( )
- SPSS软件的常用窗口主要有( )
- ( )文件格式是SPSS独有的。一般无法通过Word、Excel等其他软件打开。
- 数据编辑窗口的主要功能有( )
- SPSS软件是20世纪60年代末,由( )大学的三位研究生最早研制开发的。
答案:错
答案:对
答案:对
答案:对
答案:对
答案:对
答案:错
答案:对
答案:对
答案:结果显示区###结果目录###窗口主菜单###工具栏
答案:条形图###频数分布表
温馨提示支付 ¥5.00 元后可查看付费内容,请先翻页预览!

