1.面板数据的分析可采用以下哪个方法? ( )
A:单独每一个个体估计,再将每个个体的估计值取平均值
B:为n-1个体创造一个二值变量,将这n-1个二值变量加入模型估计
C:为每个观测值创造一个二值变量,将所有二值变量加入模型估计
D:单独每一期数据估计,再将每期估计值取平均值
答案:为n-1个体创造一个二值变量,将这n-1个二值变量加入模型估计
2.在工具变量回归中,如果工具变量是外生的,则: ( )
A:说明工具变量已经满足有效性。
B:说明工具变量与包含的内生变量X有相关性。
C:说明工具变量的变化不能直接影响因变量Y。
D:说明工具变量与感兴趣方程里的误差项可能存在相关性。
答案:说明工具变量的变化不能直接影响因变量Y。
3.两阶段最小二乘估计量的第一阶段为: ( )
A:建立工具变量对包含的内生变量和包含的外生变量的回归。
B:建立包含的内生变量对包含的外生变量和工具变量的回归。
C:建立包含的外生变量对包含的内生变量和工具变量的回归。
D:建立包含的内生变量对包含的外生变量的回归。
答案:建立包含的内生变量对包含的外生变量和工具变量的回归。
4.一个只包含一个回归变量X的线性回归模型中,假设X是外生的,且存在有效的工具变量Z,从估计量的有效性的角度来说: ( )
A:OLS估计一定比用工具变量Z的TSLS估计好。
B:OLS估计与用工具变量Z的TSLS估计一样好。
C:其余选项皆错。
D:用工具变量Z的TSLS估计一定比OLS估计好。
答案:OLS估计一定比用工具变量Z的TSLS估计好。
5.常用来表示定性的信息。( )
A:自变量
B:工具变量
C:因变量
D:虚拟变量
答案:虚拟变量
6.以下哪一个不属于高斯马尔可夫定理的假设( )
A:给定解释变量,随机扰动项的条件方差为常数
B:随机扰动项必须服从标准正态分布
C:给定解释变量,随机扰动项的条件期望为0
D:一元回归模型的参数是线性的
答案:随机扰动项必须服从标准正态分布
7.关于样本选择偏差,正确的说法是:( )
A:收集数据时,缺失了与Y或u有关的一部分数据
B:收集数据时,缺失了与自变量X有关的一部分数据
C:只是在有限样本中存在这个问题
D:收集数据时,随机地缺失了一部分数据
答案:收集数据时,缺失了与Y或u有关的一部分数据
8.固定效应回归的估计量:( )
A:是一致的估计量
B:很难计算准确
C:一般偏小
D:一般偏大
答案:是一致的估计量
9.工具变量的有效性的表述正确的是: ( )
A:它是TSLS估计量一致性的必要条件。
B:只要工具变量的个数大于内生变量的个数,模型通过J检验可以保证至少有一部分工具变量满足外生性。
C:它是TSLS估计量无偏性的必要条件。
D:工具变量的强弱可以用第一阶段 F统计量是否大于10的经验法则来精准地判断。
答案:它是TSLS估计量一致性的必要条件。
10.回归模型增加一个自变量后:( )
A:可以减小遗漏变量偏差
B:如果加入的变量很重要,那么 R2 会变小
C:R2 一定会变大
D:通过对用t统计量的大小判断,如果对用的p值小于1%,则说明该变量应该加入
答案:可以减小遗漏变量偏差
11.在面板数据分析中,如果其中一个控制变量是不随时间变化的,会发生以下哪种情况? ( )
A:可以在不观察到它的情况下仍然控制它的影响。
B:计算机软件崩溃
C:由于计算压力太大,硬盘可能被烧毁
D:无法得到目标变量前系数的估计值
A:小于0 B:大于0 C:等于1 D:等于0 13.OLS估计量的无偏性不需要如下假设( )
A:样本为随机抽样 B:给定解释变量,随机扰动项的条件方差为常数 C:给定解释变量,随机扰动项的条件期望为0 D:一元回归模型的参数是线性的 14.Di 是二值变量, X 是连续变量,回归模型Yi = β0 + β1Xi + β2Di + β3(Xi × Di) + ui , 关于β3的正确说法为:( )
A:β3的估计值不是正态分布的 B:因为当 Di = 0时,(Xi × Di) = 0,所以β3无意义 C:当D=1时模型的斜率 D:当D取不同值对应的两个模型的斜率差 15.在二元线性回归模型中,如果去掉一个解释变量,则( )
A:OLS 估计量不存在 B:OLS 是一致但是有偏的 C:误差项不再是同方差的 D:无法再控制这个变量的影响 16.一个只包含一个回归变量X的线性回归模型中,且存在有效的工具变量Z: ( )
A:如果X是内生的,OLS估计与用工具变量Z的TSLS估计都是无偏的。 B:如果X是外生的,OLS估计与用工具变量Z的TSLS估计都是一致的。 C:如果X是内生的,OLS估计与用工具变量Z的TSLS估计都是一致的。 D:如果X是外生的,OLS估计与用工具变量Z的TSLS估计都是无偏的。 17.将y回归到x,下列哪个表述说明存在异方差( )
A:给定解释变量x,随机扰动项的条件方差为常数 B:给定解释变量x,随机扰动项的条件方差为x的函数 C:一元回归模型的参数是线性的 D:随机扰动项必须服从标准正态分布 18.面板数据的应用中:( )
A:如果删掉50%的个体的观测值,估计会更精准 B:观测值的个数必须小于10万 C:T越短,估计偏差会越小 D:N越大越好 19.关于TSLS的统计推断的表述错误的是: ( )
A:在STATA中可以使用IVREG回归命令一次性计算出估计量和正确的标准误。 B:第二阶段OLS估计的异方差稳健标准误是正确的。 C:TSLS估计的渐近正态性是基于大样本的结论。 D:当模型里的工具变量为弱时,TSLS估计的渐近正态性不成立。 20.对于线性概率模型,唯一解释变量X的系数估计值为0.2,这意味着( )
A:X取1时,因变量取1的概率预测值为0.2 B:X每增加1个单位,因变量取1的概率预测值增加0.2 C:X每增加1个单位,因变量的预测取值增加0.2 D:X取1时,因变量的取值为0.2 21.在多元线性回归模型中,需要担心完全多重共线性是因为:( )
A:很多经济变量之间是完全多重共线的 B:经济变量总是一起变化的 C:OLS 估计量将无法计算 D:OLS 估计量不再是BLUE的 22.SER的优点之一是和因变量的单位相同。( )
A:对 B:错 23.MA(4)过程是平稳随机过程。( )
A:错 B:对 24.在大样本情形下,我们仍然需要假设误差项具有正态分布。( )
A:对 B:错 25.其他条件相同,误差项方差越大,斜率估计量的方差越大。( )
A:错 B:对 26.对于系数的显著性检验,使用t统计量,p值和置信区间三种方法得出的结论一定是相同的。( )
A:对 B:错 27.方差集群性是金融时间序列的常见特征。( )
A:对 B:错 28.出现伪回归时误差项序列存在很强的自相关性。( )
A:错 B:对 29.在使用虚拟变量进行政策评估时, d=1的组通常称为处理组。( )
A:对 B:错 30.判断一个模型的残差是否存在条件异方差可以使用下面的方法?( )
A:观察残差平方的样本自相关函数和样本偏自相关函数 B:对残差的平方使用Q检验 C:观察残差的样本自相关函数和样本偏自相关函数 D:使用ARCH-LM检验 31.关于协整说法正确的是?( )
A:如果存在协整关系,各变量的随机趋势一定不独立。 B:如果存在协整关系,协整向量唯一。 C:如果存在协整关系,说明变量间存在长期均衡关系。 D:有n个非平稳序列,则最多有n个线性独立的协整向量。 32.对收益率建立AR(3)-GARCH(1,1)模型,可以如下应用:( )
A:检验收益率是否可预测。 B:风险溢价的大小。 C:收益率的波动率对好消息和坏消息的响应是否对称。 D:计算收益率的风险程度。 33.残差
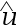 指的是( )
指的是( )A: B: C: D: 34.对于回归模型 Yi = β0 + β1X1 + β2X2 + β3(X1 × X2) + ui,
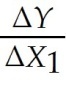 的期望值是:( )
的期望值是:( )A:β1. B:β1 + β3X1. C:β1 + β3X2. D:β1 + β3. 35.欲探究二值变量抵押贷款是否被拒(deny,若被拒,取1,否则取0)与还款/收入比(P/I ratio)的关系,利用相关数据,以deny作为因变量,对P/I ratio做OLS回归,得到结果:
 = -0.080 + 0.604 P/I ratio
= -0.080 + 0.604 P/I ratio(0.032) (0.098)
下列说法错误的是( )
A:P/I ratio的系数估计在1%水平下显著 B:由模型结果可看出,还款额占收入比例越高,申请者的申请越可能被拒 C:还款/收入比每增加0.1,被拒概率上升0.060 D:若计划还款额为申请者收入的30%,则由模型得预测值为0.181 36.拟合优度
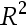 为( ):
为( ):A: B: C: D: 37.对于该模型的说法错误的是( )
A:估计过程中采用极大似然估计法得到的系数估计量满足一致性和有效性 B:高收入与否和年龄这两个变量均对已婚概率有显著影响(5%显著性水平下) C:年龄每增加一岁带来的已婚概率变化依赖初始年龄 D:若采用线性概率模型,则可以用调整后的来评价拟合状况 38.模型
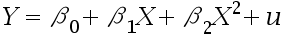 中未知参数的估计方法为:( )
中未知参数的估计方法为:( )A:OLS估计 B:非线性最小二乘估计法 C:Probit估计方法 D:R方估计方法 39.预测值
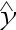 指的是( )
指的是( )A: B: C: D: 40. 模型
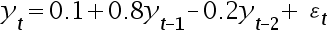 ( )
( )一阶自相关系数等于
A:2/3 B:1/3 C:-1/2 D:0 41.下列说法错误的是( )
A:在对线性概率、probit、logit模型进行估计时,估计方法和普通的多元线性回归一致 B:在二值因变量模型中,因变量取1的概率可以不是自变量的线性函数 C:二值因变量模型无法给出具体的Y取1或0的结果,而只能对于Y的取值做概率上的估计 D:在对线性概率、probit、logit模型进行拟合状况评价时,不能采用与普通多元线性回归一样的拟合指标

