- 分析结果与汇报结果同样重要。
- 如果一个变量统计不显著,我们应该把它从模型中直接剔除。
- 面板数据可以解决某些特定类型的遗漏变量偏差。
- 数据可获得性和质量直接影响实证研究的可行性。
- 文献回顾可以只按时间顺序罗列相关论文即可。
- 当我们进行模型的稳健性分析时,我们可以做以下哪些工作?
- 当我们讨论一个解释变量的系数时,我们通常会讨论:
- 数据的初步处理包括以下工作:
- 与其它选项相比,下列哪个平台不适宜进行学术搜索?
- 下列哪个实证题目不需要建立因果关系的模型?
- 在线性概率模型 Yi= β0+ β1Xi+ ui 中,下列说法错误的是
- 在二值因变量模型中,预测值为0.8意味着
- Probit模型的有效估计通常采用
- 下列关于伪的说法错误的是
- 关于线性概率模型,正确的是
- 对于线性概率模型,唯一解释变量X的系数估计值为0.5,这意味着
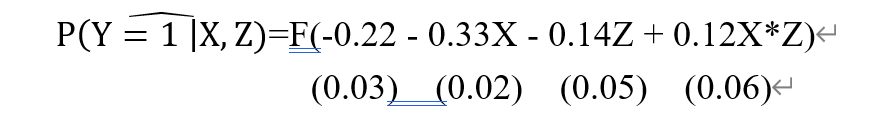
- 面板数据回归中,变量只随个体变化并且不可观测,如果该变量和其他自变量存在相关性,意味着应该使用随机效应模型。
- 面板数据中,
- 如果固定效应估计与OLS估计存在较大差异,说明:
- 个体固定效应中的个体:
- 关于时间固定效应,以下说法正确的是:
- 在只有两期的面板数据中:
- 关于面板数据估计方法,以下哪个说法是正确的?
- 面板数据相对于截面数据最主要的优势是?
- 面板数据可以解决以下哪个问题?
- 以下哪个数据是面板数据?
- 如果序列{}和{}单整阶数不同,那么两个变量间建立回归模型没有任何意义。
- 如果两个变量存在协整关系,那么回归方程不再是伪回归。
- 假设 I(1), I(1), I(0), I(1),哪几组变量不可能存在协整关系?把标号写在括号中
- 考虑下面的误差修正模型模型,错误的说法是:
- 关于协整说法错误的是?
- 模型如下:那么的均值和方差的特点是:
- 模型如下假设t期扰动项改变一个单位,t+2期的改变量是?
- 下面是对几个时间序列做单位根检验的结果, 哪个序列是I(1)的? 水平变量单位根检验临界值5% : -3.41 差分后临界值 5% :-2.86
- 关于趋势平稳随机过程正确的说法是:
- ADF单位根检验与DF单位根检验比较,错误的说法是?
- GARCH(1,1)模型与ARCH(10)模型相比,优点是参数个数较少
- 波动率聚类性表现在收益率的平方存在强自相关,收益率不相关或弱相关。
- 某随机过程Yt无条件均值等于0,无条件方差是常数,条件均值等于0,条件方差随时间变化,该随机过程可能是:
- 假设ARCH-LM检验q=4,那么统计量服从的分布是?
- 对收益率建立AR(3)-EGARCH(1,1)模型,可以用来在如下应用,除了:
- ARCH-LM检验使用的回归模型是:
- 如果扰动项的平方服从ARMA(2,3)模型,那么对应的GARCH模型是:
- 关于下面的TGARCH模型,哪个说法是错误的?其中 = 1 if < 0>
- 下面模型对条件方差的2步预测等于?,其中=0.04,=0.2
- TARCH与ARCH模型相比,优点是:
- AIC准则有较强的一致性,确定的阶数随着样本容量的增加收敛到真实滞后长度上去。
- 白噪声过程是不相关平稳随机过程。
- 预测误差大小惩罚力度最大的指标是
- 考虑下面的 ARMA(1,1)模型:yt = 0.1 + 0.7yt-1 + 0.2et-1+ et对 yt 的最优一步预测是(i.e. 对时刻t 假设 t-1前包括t-1期的数据已知)其中et-1 = 0.01; yt-1 =0.12;
- Yt =0.1+0.4et-1 -0.2et-2 +et,Yt的自相关系数最小值等于:
- 用一个长度为121的平稳时间序列计算得到样本偏自相关系数:,,和。只基于这些信息,我们会为该序列试探性地设定什么样的模型?
- 假设yt = 0.4 + et+ 0.5 et-1 - 0.3 et-2,yt 的无条件均值等于?
- 下面是几个模型, 写出不满足平稳条件模型的标号:
- 假设数据满足AR(2)模型:,那么对变量进行前向100步预测,最接近的估计值是?
- 下面哪个说法可以很好的描述ARMA(1,4)的统计特点?
- 只有在过度识别的情况下,才能进行工具变量的外生性假设检验
- 如果我们只在乎一致性,则工具变量回归一定比OLS回归要好。
- 两阶段最小二乘估计量与OLS估计量相比的优点是更有效率
- 模型结构式必须基于经济理论来构造。
- 弱工具变量造成的主要问题是:
- 一个有效的工具变量应满足如下两个条件
- 在一个完全竞争的市场中,市场均衡是由需求和供给决定的,如果使用商品数量-商品价格的数对来做回归:
- 在进行项目评价或估计处理效应时,只要使用了双重差分,模型中不再需要控制其他因素的影响。
- 拒绝邹氏检验的原假设意味着两个组别之间存在差异。
- 虚拟变量陷阱是一种特殊的完全多重共线性。
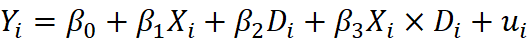
- 下列涉及虚拟变量的回归方程,哪个形式是不对的?
- 假设你要研究性别对个人收入的影响,于是你选择个人年收入为因变量,解释变量包括二元变量Male(当个体性别为男时取值1,否则为0)、二元变量Female(当个体性别为女时取值1,否则为0)以及常数项。因为女性的收入平均来说往往低于男性,因此,你预计的回归结果是:
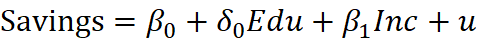
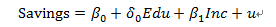
- 模型ln(Yi) = β0 + β1ln(Xi) + ui,β1 表示:
- 回归结果是内部有效的,指的是:
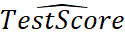
- 为了判断模型是线性回归模型还是r阶的多项式回归模型,我们可以:
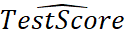
- 非线性模型中,当其他自变量保持不变,X1 变化△X1,因变量的期望值的变化量为:
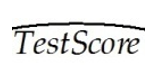
- 在模型中,参数的含义是:
- 一元对数线性模型的形式为:
- 请问下列哪一个不能化为参数线性的回归模型:
- 如果和是回归模型中未知参数的估计量,那么可得
- 多元回归模型中,OLS估计量是一致估计量的充分条件是:
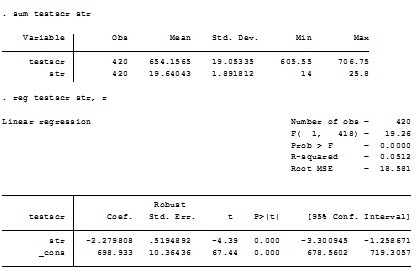
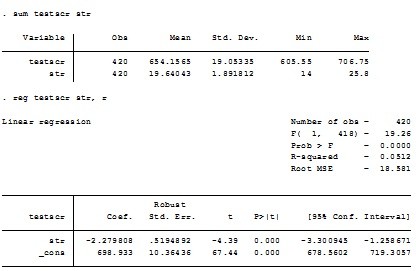
- 检验一个包含两个约束条件的原假设,其中无约束的R2和有约束的R2分别为 0.4366 和 0.4149。总的观测值为420个,则F统计量为:
- 以下哪组原假设不能采用F检验:
- 同方差下的F统计量和异方差下的F统计量通常是:
- 同方差下的F统计量可以用如下公式计算:
- 整体显著性的F统计量是检验:
- 对于单个约束而言,F统计量:
- 假设检验的显著性水平是:
- 多元回归模型单个系数的假设检验 ,我们构造的检验统计量服从:
- 两个回归用的是不同的数据集,即使其中一个模型用了更少的自变量,我们仍然能用来比较两个模型。
- 当多元模型中加入一个新的自变量,新得到的会减小
- 多元线性回归模型中的“线性”指的是对参数是线性的。
- 模型有7个自变量,现有20个观测值,那么此时回归模型的自由度是:
- 调整的,即的计算公式为:
- 不完全多重共线时:
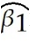
- 在一个有截距项的回归模型估计结果中,已知总的离差平方和SST=49,归直线所能解释的离差平方和SSE=35, 那么可知残差平方和SSR等于:
- 对于一个二元线性回归模型,这里的是一个________.
- 如果因为遗漏变量导致假设条件E(ui|Xi) = 0不成立,则:
- R2很小意味着解释变量不显著。
- 选项r可用于控制异方差性。
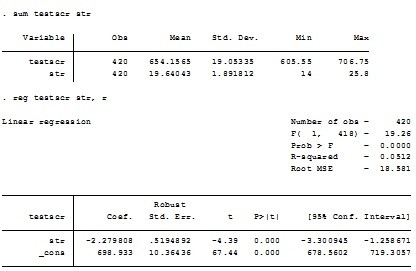
- 当t分布的自由度很大时,t分布可以由正态分布近似。
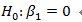
- 当经典线性回归模型去掉误差服从正态分布的假设时,仍然可以使用最小二乘法来估计未知参数,但是这时检验某个参数是否等于0的统计量不再服从t分布。
- 对于单侧和双侧的备择假设,t 统计量的构造是相同的。
- 计量经济学里,显著性包括经济显著性和统计显著性两个维度。
- 在一个普通商品的需求函数中,需求数量是商品价格的线性函数。在进行价格的显著性检验时,你应该:
- 下列哪个现象会使得通常的OLS 中t 统计量无效?
- 如果 一个假设在5%的显著水平下不能被拒绝,则它
- 在假设检验中,如果得到一个很小的p-值(比如小于5%),则
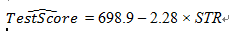
- 拟合优度没有单位。
- 过原点的回归模型中,残差项之和也一定等于0。
- 回归模型 不可以用OLS估计,因为它是一个非线性模型。
- 误差项的异方差会影响OLS估计量的
- 估计量具有抽样分布的原因是:
- 在一个带截矩项的一元线性模型中,下列哪条OLS的代数性质不成立?
- 将因变量的值扩大10,将自变量的值同时扩大100,则:
- OLS估计量是通过()推导的:
- 在简单回归模型中,u 一般用来表示
- 建立预测模型不需要严格的因果关系。
- 相关系数只能描述两个变量之间的线性关系。
- 建立计量经济学模型时,只需考虑我们感兴趣的变量。
- 时间序列数据又被称为纵向数据。
- 在经济学的分析中,因果关系只能通过实验数据来估计。
- 研究金砖四国2001-2019年的GDP增长率需要用到下列哪种数据?
- 下列哪条不是横截面数据的特征?
- 下列那些指标可用于描述两个变量之间的关系?
- _____对_____有因果影响?
- 计量经济学研究中,不需要用到:
答案:对
答案:错
答案:对
答案:对
答案:错
答案:模型函数形式的变化;###解释变量的增减;###数据抽样范围的变化。###解释变量的替换或重新定义;
答案:系数的数值大小;###系数的符号;###系数的显著性;
答案:是否包括模型所需的关键变量;###清洗数据;###计算描述统计量;###做散点图。
答案:百度;
答案:中国明年的通货膨胀率会是多少?
答案:系数β1表示自变量X变化一个单位所引起的Y的取值的变化
温馨提示支付 ¥5.00 元后可查看付费内容,请先翻页预览!

