中央财经大学
- dplyr包的核心函数主要包括.( )
- 欲抽查某生产线上一批罐装可乐的糖分,已知该生产线每天匀速运转10个小时,产量为1万罐儿,首先从生产线末端的第1到100罐中随机抽取1罐,而后每隔6分钟抽取1罐,直到抽取100罐为止,对这100罐进行检验。此种抽样方法属于( )。
- 下面哪些指标可以用来度量数据的分布形状?( )。
- 一个箱子中装有质量均匀的10个白球和9个黑球,一次摸出5个球,在已知它们的颜色相同的情况下,该颜色是白色的概率大于0.5. ( )
- tibble也是一种数据框,与data.frame数据框类似. ( )
- x<-c(-1:-5),该语句存在语法错误.( )
- 用最小二乘方法估计多元回归模型得到的残差项求和一定等于0.( )
- read.table( ) 函数主要用于读取 .txt 文件.( )
- 样本统计量的概率分布也称为抽样分布(sampling distribution),它是由样本统计量的所有可能取值形成的相对频数分布.( )
- 设随机变量X~N(0,1),则P(-1<X≤3)=0.9.( )
- 当单因素方差分析不满足正态分布或方差齐性的假设前提时,不能采用非参数检验的方法.( )
- 因素各水平的差异由系统性差异和随机误差组成.( )
- 样本是否来自正态分布可以用t分布来检验. ( )
- 显著水平越大,检验效果越好. ( )
- 回归模型
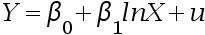 不可以用最小二乘法估计, 因为它是一个非线性模型.( )
不可以用最小二乘法估计, 因为它是一个非线性模型.( ) - 定序变量不能计算中位数。( )
- 在k-均值聚类中,设置的初始类中心不同,不会影响最终的聚类结果。 ( )
- RData只能存放一个数据对象. ( )
- F分布中两个自由度的位置可以随意互换.( )
- 标准误是指统计量的标准差,也称为标准误差.( )
- 单因素方差分析可以用于分析一个分类变量与一个数值变量之间的关系.( )
- 根据加法模型进行时间序列分解时,季节成分之和等于0。 ( )
- 随机变量
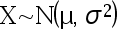 , 则随着
, 则随着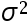 增大, 概率P(|X-
增大, 概率P(|X-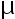 |<3
|<3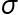 )将会单调增加. ( )
)将会单调增加. ( ) - x<-2,x的类型是Integer.( )
- 一张数据表不可能存在重复健.( )
- 计算加权综合指数时,如果同度量因素固定在基期,则相应的指数称为拉氏指数. ( )
- 方差分析中的因变量也称为因素.( )
- x=rep("1",2),执行该语句后x的取值为1, 1.( )
- x<-1:10,x是向量.( )
- 在单因素方差分析中,多重比较的目的是比较两个水平之间均值的差异性.( )
- F统计量的值有可能小于0.( )
- Logistic回归的结果并非数学定义中的概率值,不可以直接当做概率值来用.( )
- 只考虑两个因素单独对因变量影响的模型称为交互效应的双因子方差分析.( )
- 总体是全部待研究的对象.( )
- P值是原假设成立的情况下,统计量发生的概率.( )
- 假设 x<-c(1,-2, 3, 5, 8),那么取x的第二个元素的语句为 x[1].( )
- 已知P(A∪B) = 0.7,P(A)=0.4,则当A与B不相容时,P(B)=0.3.( )
- 某汽车电瓶商声称其生产的电瓶具有均值为60个月,标准差为6个月的寿命分布。现假设质检部门决定检验该厂的说法是否准确,为此随机抽取了50个该厂生产的电瓶进行寿命实验。假设厂商声称是正确的,则50个样品组成的样本的平均寿命不超过57个月的概率很小.( )
- 虚拟变量陷阱是一种特殊的完全多重共线性.( )
- 下面哪些是统计量?( )
- 如果X和Y分别是来自两个正态总体的两个样本,样本量分别为100和50,已知X和Y的样本均值为12,10;样本方差为:25,16。若总体均值分别为
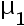 和
和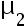 ,那么对于假设检验
,那么对于假设检验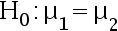 ,它的检验统计量为(保留2位小数点)?( )。
,它的检验统计量为(保留2位小数点)?( )。 - 与直方图相比,茎叶图.( )
- 多元线性回归分析中,使用普通最小二乘进行参数估计时需要假设.( )
- 关于k-均值聚类方法,以下正确的是.( )
- Logistic回归属于( )
- 在不考虑交互效应的双因素方差分析中,若因素A的处理平方和为SSA=20,因素B的处理平方和为SSB=80,误差平方和为SSE=10,那么因素A的偏效应量为.( )。
- 如果一个假设在5%的显著水平下被拒绝,则它___.( )。
- select()函数主要用来选取.( )
- 如够想研究我们班同学对不同的手机品牌是否有明显的偏好,应该选用什么方法?( )。
- 为了估计总体比例p,已经求得其95%的置信区间为(72%,78%),下列说法中错误的是( )。
- 若要用
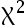 独立性检验检验两个分类型变量之间的相关性,其原假设为___.( )
独立性检验检验两个分类型变量之间的相关性,其原假设为___.( ) - 使用K-S检验来进行正态性检验时,以下说法正确的是( )。
- 下列哪个现象会使得通常的最小二乘法的t 统计量无效?( )。
- 某研究部门准备在全市200万个家庭中抽取2000个家庭,据此推断该城市所有职工家庭的年人均收入。这项研究的参数是.( )
- 某研究人员于2009年发表的一篇文章讨论了男性和女性硕士应届毕业生起薪的差别。文章称,从某重点大学统计学院毕业的20名女性的平均起薪是3500元,中位数是3600元,标准差是550元。根据这些数据可以判断,女性硕士应届毕业生起薪的分布形状是.( )
- 假设要研究性别对个人收入的影响, 其中个人年收入是因变量, 解释变量包括两个变量:Male和Female。其中:个体性别为男性时,Male=1;否则,Male=0。同理,个体性别为女性时,Female=1;否则,Female =0。因为女性的平均收入通常低于男性, 因此, 你预计的回归结果是___. ( )
- 若X是来自正态分布的一个样本,其样本量为20,样本均值为10.2,样本标准差为10,那么它的(95%)的置信区间的下界为(保留2位小数点)?已知
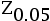 =-1.96,
=-1.96,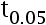 (19)=-1.73.( )
(19)=-1.73.( ) - 关于
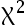 独立性检验,下面说法正确的是___.( )
独立性检验,下面说法正确的是___.( ) - 关于V系数,错误的是___.( )。
- 将学生的考试成绩分成优、良、中、及格和不及格,所得到的数据属于.( )
- 如果X和Y分别是来自两个正态总体的配对样本,若总体均值分别为和,那么对于假设检验的步骤为:()①求样本的统计量、方差、标准误②求两个样本的差值③给定显著水平,构造拒绝域,并判断是否接受原假设④计算检验统计量
- 下列是涉及虚拟变量的回归方程, 哪个回归模型的形式不对? ( )
- 在统计推断中,总体参数是一个.( )
- 在假设检验中,如果得到一个很小的 p-值(比如小于5%),则___.( )。
- 在抽样调查中以下哪一项会造成非抽样误差?( )。
A:arrange()函数
B:filter()函数
C:select()函数
D:summarize()函数
答案:select()函数###summarize()函数###filter()函数###arrange()函数
A:概率抽样
B:整群抽样
C:简单随机抽样
D:等距抽样
答案:等距抽样###概率抽样
A:偏度系数
B:峰度系数
C:标准分数
D:变异系数
答案:峰度系数###偏度系数
A:错 B:对
答案:对
A:错 B:对
答案:对
A:错 B:对
答案:错
A:错 B:对
答案:错
A:对 B:错
答案:对
A:对 B:错
答案:对
A:对 B:错
A:错 B:对
A:对 B:错
A:对 B:错
A:错 B:对
A:错 B:对
A:对 B:错
A:错 B:对
A:错 B:对
A:对 B:错
A:对 B:错
A:对 B:错
A:错 B:对
A:对 B:错
A:错 B:对
A:对 B:错
A:错 B:对
A:错 B:对
A:对 B:错
A:错 B:对
A:对 B:错
A:错 B:对
A:错 B:对
A:错 B:对
A:错 B:对
A:对 B:错
A:错 B:对
A:对 B:错
A:对 B:错
A:错 B:对
A:
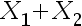
B:
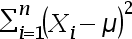
C:
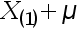
D:
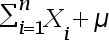
A:3.51
B:-2.65
C:-3.51
D:2.65
A:不能有效展示数据的分布
B:没保留原始数据的信息
C:适合描述分类数据的分布
D:适合描述小样本数据的分布
A:任何一个自变量不能是其他自变量和常数项的线性函数
B:自变量之间不相关
C:其余选项都不对
D:自变量和因变量之间不相关
A:需要事先人为确定k的值
B:R可以自动确定k的值
C:比系统聚类法的计算量要大,对计算机性能的要求高
D:比系统聚类法更精确
A:非概率型非线性回归
B:概率型非线性回归
C:非概率型线性回归
D:概率型线性回归
A:30/20
B:110/30
C:20/110
D:20/30
A:在1%的显著水平下可能被拒绝
B:在1%的显著水平下一定不会被拒绝
C:在10%的显著水平下一定不会被拒绝
D:在10%的显著水平下一定被拒绝
A:都不行
B:列
C:行和列
D:行
A:卡方拟合优度
B:其余选项都不正确
C:一个总体方差的假设检验
D:绘制概率密度曲线
A:点估计值为75%
B:此次估计的误差范围是3%
C:用该方法估计的可靠程度95%
D:总体比例落在这个置信区间的概率为95%
A:其余选项都不正确
B:H0:两个类别变量相关
C:H0:两个类别变量相等
D:H0:两个类别变量独立
A:检验的备择假设是样本服从正态分布
B:检验的原假设是总体服从正态分布
C:检验的原假设是样本服从正态分布
D:检验的备择假设是总体服从正态分布
A:误差项不服从正态分布,但样本量较大
B:回归方程没有常数项
C:异方差
D:X有异常值
A:2000个家庭
B:200万个家庭的年人均收入
C:2000个家庭的年人均收入
D:200万个家庭
A:均匀
B:右偏
C:左偏
D:对称
A:Male系数和Female系数数值相等
B:回归系数无法估计,因为存在完全多重共线性
C:Male系数为正,Female系数为负
D:Male系数为负,Female系数为正
A:5.82
B:5.70
C:6.23
D:6.33
A:单元格中的样本量不要太少,否则检验会出现偏差
B:假设样本量为n,独立性检验的自由度为n-1
C:其余选项都不正确
D:对单元格中的样本量没有要求
A:V系数值不可能会等于1
B:V系数值越接近 1,表示两个变量的相关性越强
C:V系数值越接近 0,表示两个变量的相关性越弱
D:V系数值可能会等于1
A:定类数据
B:定序数据
C:定距数据
D:定比数据
A:②①③④ B:①②③④ C:②①④③ D:①②④③
A:
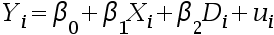
B:
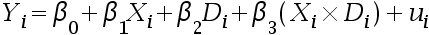
C:
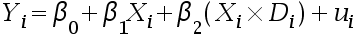
D:
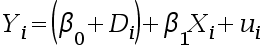
A:随机变量
B:统计量
C:未知的量
D:已知的量
A:该结果出现的概率大约为5%
B:该结果不利于原假设
C:该结果有利于原假设
D:说明t统计量小于1.96
A:调查员编造数据
B:数据录入错误
C:被调查者拒答
D:其余选项都对
温馨提示支付 ¥5.00 元后可查看付费内容,请先翻页预览!

