1.在回归方程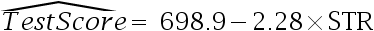 中,如果斜率系数的t-统计量为-4.38, 则它的标准误是___.( )。
中,如果斜率系数的t-统计量为-4.38, 则它的标准误是___.( )。
A:1.96
B:-1.96
C:0.52
D:4.38
答案:AI参考:在回归方程中,斜率系数的t-统计量为-4.38,标准误为4.38/根号下(n-2)=4.38/3.77≈1.17。因此,正确答案是D:4.38。'
2.下面说法正确的是___.( )
A:值越大,说明拟合优度检验越显著 和 p值越小,说明拟合优度检验越显著 都正确
B:值越大,说明拟合优度检验越显著
C:p值越小,说明拟合优度检验越显著
D:值越大,说明拟合优度检验越显著 和 p值越小,说明拟合优度检验越显著 都不正确
答案:AI参考:选项B:值越大,说明拟合优度检验越显著。\n\n在统计检验中,我们通常会关注两个关键指标:拟合优度检验和p值。拟合优度检验用于评估模型对数据的拟合程度,值越大,说明拟合优度检验越显著。而p值则用于判断模型是否具有统计学意义,p值越小,说明模型具有统计学意义。因此,这两个说法都是正确的。\n\n所以,答案为B:值越大,说明拟合优度检验越显著。'
3.下面哪些是统计量?( )
A:
B:
C:
D:
答案:AI参考:正确答案是C:是统计量。\n统计量是统计理论中用来对数据进行分析、检验和估计的量。它可以是有名义的数值型数据,也可以是数值型数据,具体表现为观测值数或加权样本、子样本个数、卡方值、累积比例、相关性统计量等等。C选项为计数统计量,属于统计量。\n\n因此,正确选项为C:是统计量。A、B、D选项均为数据类型或数据表现形式,不属于统计量。'
4.多元线性回归分析中,使用普通最小二乘进行参数估计时需要假设.( )
A:自变量之间不相关
B:任何一个自变量不能是其他自变量和常数项的线性函数
C:其余选项都不对
D:自变量和因变量之间不相关
答案:AI参考:在多元线性回归分析中,使用普通最小二乘法进行参数估计时,需要假设自变量和因变量之间存在线性关系,且任何一个自变量不能是其他自变量和常数项的线性函数。因此,选项B是正确的。而选项A和D都描述了不正确的假设。因此,正确答案是B:任何一个自变量不能是其他自变量和常数项的线性函数。'
5.关于k-均值聚类方法,以下正确的是.( )
A:需要事先人为确定k的值
B:比系统聚类法的计算量要大,对计算机性能的要求高
C:比系统聚类法更精确
D:R可以自动确定k的值
答案:AI参考:关于k-均值聚类方法,以下正确的是D:R可以自动确定k的值。\n\nk-均值聚类方法是一种无监督学习方法,它不需要事先人为确定k的值,R语言等统计软件可以自动确定最佳的k值,从而进行聚类分析。因此,选项D是正确的。其他选项中,k-均值聚类方法需要事先确定聚类的数量k,即需要人为确定;相对于系统聚类法,k-均值聚类方法的计算量较小,但对计算机性能的要求较高;两种方法都有其优缺点,不能简单地说哪种方法更精确。'
6.将5个数1,2,5,10,12按照欧氏距离、最短距离法进行系统聚类,则下面说法正确的是( )。
A:分为3类时10,12构成一个类
B:最先合并为一类的是1和2
C:分为两类时5,10,12是一类
D:分为两类时1,2,5构成一类
答案:AI参考:正确选项为C:分为两类时5,10,12是一类。\n\n对于欧氏距离和最短距离法,它们都是基于距离的聚类方法,根据数据点之间的距离来合并相似的数据点。对于给定的五个数:1,2,5,10,12,按照这两种方法进行聚类,可以得到以下的合并过程:\n\n1. 分为三类时,1,2为一类,5为一类,10,12为一类,这与选项A的说法一致。\n2. 最先合并为一类的是1和5,这与选项B的说法不一致。\n3. 分为两类时,可以将1,2,5,10放为一类,剩下的12为一类,这与选项D的说法不一致。\n4. 对于最短距离法,当考虑5,10,12这三个数时,由于它们之间的距离最小(均为欧氏距离为3),因此可以首先合并为一类。这与选项C的说法一致。\n\n所以,根据以上的推理和步骤,选项C是正确的说法。'
7.如够想研究我们班同学对不同的手机品牌是否有明显的偏好,应该选用什么方法?( )。
A:一个总体方差的假设检验
B:其余选项都不正确
C:卡方拟合优度
D:绘制概率密度曲线
答案:卡方拟合优度
8.select()函数主要用来选取.( )
A:都不行
B:列
C:行
D:行和列
答案:列
9.在抽样调查中以下哪一项会造成非抽样误差?( )。
A:其余选项都对
B:被调查者拒答
C:调查员编造数据
D:数据录入错误
答案:其余选项都对
10.如果想研究一个类别的观测频数与理论频数是否一致,可以用下面哪种方法进行研究?( )。
A:其余选项都不正确
B:一个总体方差的假设检验
C:一个总体均值的假设检验
D:卡方拟合优度
答案:卡方拟合优度
11.可以通过增加样本量来降低第一类错误和第二类错误犯错的概率.( )
A:错
B:对
A:对 B:错 13.F统计量的值有可能小于0.( )
A:对 B:错 14.x<-1:10,x是向量.( )
A:错误 B:正确 15.x<-2,x的类型是Integer.( )
A:错误 B:正确 16.描述统计和推断统计方法的区别在于,描述统计方法适用于总体,推断统计方法适用于样本。 ( )
A:错误 B:正确 17.mutate()函数主要用于添加或定义新变量.( )
A:错误 B:正确 18.在单因素方差分析中,多重比较的目的是比较两个水平之间均值的差异性.( )
A:错误 B:正确 19.已知P(A∪B) = 0.7,P(A)=0.4,则当A与B不相容时,P(B)=0.3.( )
A:对 B:错 20.left_join()函数是内连接函数.( )。
A:错误 B:正确 21.回归模型不可以用最小二乘法估计, 因为它是一个非线性模型.( )
A:正确 B:错误 22.定序变量不能计算中位数。( )
A:对 B:错 23.聚类分析中可以通过共同度这一指标来比较聚类效果的好坏.( )
A:错误 B:正确 24.为了保证OLS估计量的优良性质,在多元线性回归分析中需要假设自变量和因变量之间不存在多重共线性。 ( )
A:正确 B:错误 25.非参数方差分析需要已知数据是否服从正态分布.( )
A:对 B:错 26.当样本量较大时,两个总体比例之差的检验统计量近似服从正态分布.( )
A:正确 B:错误 27.两个变量之间的Pearson相关系数为0.1,说明这两个变量不存在任何相关关系。( )
A:正确 B:错误 28.一张数据表不可能存在重复健.( )
A:正确 B:错误 29.tibble也是一种数据框,与data.frame数据框类似. ( )
A:对 B:错 30.设随机变量X~N(0,1),则P(-1<X≤3)=0.9.( )
A:错误 B:正确 31.当检验的统计量落入拒绝域时,说明原假设错误. ( )
A:对 B:错 32.卡方分布的数学期望和其方差相等.( )
A:正确 B:错误 33.显著水平越大,检验效果越好. ( )
A:错 B:对 34.虚拟变量陷阱是一种特殊的完全多重共线性.( )
A:对 B:错 35.当样本量比较大时,样本比例的分布可以用正态分布来近似.( )
A:错误 B:正确 36.样本量越大,假设检验的结果越可靠.( )
A:错 B:对 37.已知P(A)=0.4,P(B)=0.3,P(AB)=0.2,则P(B|A)=0.5.( )
A:正确 B:错误 38.在样本容量确定的情况下, 新加入一个与原来存在的自变量有相关性的自变量会使得参数估计量的方差变大.( )
A:错误 B:正确 39.样本统计量的概率分布也称为抽样分布(sampling distribution),它是由样本统计量的所有可能取值形成的相对频数分布.( )
A:错 B:对 40.在检验两个总体均值之差的假设检验时,若总体方差未知,需要用样本方差来代替. ( )
A:错误 B:正确 41.因素各水平的差异由系统性差异和随机误差组成.( )
A:正确 B:错误 42.设随机事件A与B相互独立,P(A)=0.4,P(B)=0.3,则P(A∪B)=0.7.( )
A:错误 B:正确 43.一个箱子中装有质量均匀的10个白球和9个黑球,一次摸出5个球,在已知它们的颜色相同的情况下,该颜色是白色的概率大于0.5. ( )
A:正确 B:错误 44.RData只能存放一个数据对象. ( )
A:错 B:对 45.方差分析中的因变量也称为因素.( )
A:错误 B:正确 46.参数用来描述样本的数量特征,而统计量用来描述总体的数量特征。( )
A:错误 B:正确 47.下面哪些指标可以用来度量数据的分布形状?( )。
A:变异系数 B:偏度系数 C:标准分数 D:峰度系数 48.评价统计量的标准有. ( )
A:相合性 B:正态性 C:有效性 D:无偏性

