- 典型相关是简单相关、多重相关的推广;或者说简单相关系数、复相关系数是典型相关系数的特例( )
- 主成分分析能够用在任何场景下。( )
- 堆栈自编码器得网络层在训练过程中是依次训练的。( )
- 支持向量机(SVM)能够很方便地解决分类问题。( )
- 方差是对两个随机变量联合分布线性相关程度的一种度量( )
- 自编码器的编码器与解码器只能使用多层感知机(MLP)。( )
- 核函数的引入可以处理非线性可分问题。( )
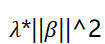
- 数据不进行数据清洗没有关系。( )
- 数据标准化会改变相关系数。( )
- 在聚类分析中,当聚类的数据量纲差异较大时,应先对数据进行标准化以消除计量单位对结果的影响。( )。
- 多元统计分析时,针对多个随机变量进行分析,不仅研究变量的波动,还要研究变量间的耦合性。( )
- 应用马氏距离时需要已知样本总体的分布情况。( )
- 决策树的模型可解释性较差。( )
- 多元统计的图表示法的难点在于,变量过多时难以可视化。( )
- 如果两个变量的相关系数为0,则说明两个变量是独立的。( )
- 可以借助拉格朗日乘数来求解典型相关分析问题( )
- 随机森林中树的数量对整体性能影响不大。( )
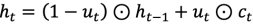
- CNN常用于序列数据的建模( )
- 维数灾难是指当变量指标、特征逐步增加时导致计算量、计算难度成指数爆炸性增长,而模型准确性却在降低的情况。。( )
- 费舍尔判别分析方法(FDA)旨在找到一条能够分隔不同类别样本的分界线。( )
- 变分自编码器的推导过程使用了样本的独立同分布假设,因此不能直接处理具有时序相关性的流数据( )
- 偏最小二乘法的潜变量提取要求潜变量之间的相关性尽可能大。( )
- 变量的随机程度越低,则信息熵越小。( )
- 最小二乘回归模型目标函数的几何意义就是在X(变量*样本)的行空间内找出一个向量,使得其与Y(1*样本)的距离最小。( )
- 主成分分析能够提升数据挖掘的效果。( )
- 神经网络是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。它通过训练调整内部节点之间相互连接的关系,从而达到处理信息的目的。( )
- 样本的顺序会影响K均值聚类算法的结果。( )
- 决策树需要从根节点到叶子结点一层一层构建。( )
- 下列哪些是神经网络中的“超参数”?( )
- 下列关于支持向量机说法正确的是( )
- 以下哪些神经网络结构会发生权重共享?( )
- 直接用OLS估计随机误差项存在序列相关性的线性回归模型的未知参数时,会产生下列问题:( )
- 会对K均值聚类算法结果产生影响的因素有( )
- 下面哪些任务可以用神经网络解决( )
- 简单相关系数描述两组变量的相关关系的缺点包括( )
- 关于主成分分析的应用场景,下列说法正确的是?( )
- 费舍尔判别分析的宗旨是( )。
- 欧氏距离的不足是( )。
- 以下哪些属于大数据的特点( )。
- 下列关于PCA和FDA方法的说法正确的是( )。
- 建立回归模型的过程中出现的拟合不佳的情况主要有。( )
- 下列关于去噪自编码器的叙述正确的是( )
- 下面哪些选项属于异常值检查方法?( )
- 下面哪些选项为数据清洗中的“脏数据”?( )
- “参数共享”是使用卷积网络的好处,关于参数共享,下列哪些说法是正确的?( )
- 多元统计分析的研究内容包括( )
- 关于偏最小二乘回归,下列说法正确的是:( )
- 下列选项中属于K均值聚类算法流程的有( )。
- PCA和CCA的相同点包括( )。
- 高斯混合模型中通过EM能够求得的参数有( )
- 下面关于KL散度的说法正确的是( )。
- 关于聚类算法,下列说法中正确的有( )。
- 一般来说,对样本数据进行降噪的主要目的有哪两方面( )。
- 构建决策树的过程中,子节点的熵比父结点的熵( )
- 对于两个一维变量,其简单线性相关系数的取值范围为( )
- 什么情况下协方差与相关系数相等( )
- 在利用连续性变量构建决策树时,除了确定在当前节点采用哪个变量,还需确定( )
- 贝叶斯是一种有概率描述的判别方法,使用( )进行判别。
- 监督算法和无监督算法的区别是( )。
- 利用bootstrapping采样技术,随机森林中的每一棵决策树大概有( )比例的样本始终未被采集到。
- 针对偏最小二乘法潜变量的确定,可以采用什么方法确定潜变量的个数。( )
- 检测异常值时,一般使用( )σ准则
- 对于分类任务,我们不是将神经网络中的权重随机初始化,而是将所有权重设为零。下面哪个说法是正确的?( )
- 以下哪一项在神经网络中引入了非线性( )
- 对于偏最小二乘回归,下列说法正确的是( )

- 对于主元分析,下列说法错误的是( )
- 你觉得LSTM为什么适合用于进行血糖预测( )。
- 关于主成分分析可以使用的场景。下列说法错误的是( )
- 当数据各个变量的方差差异较大时,采用哪种距离定义方法相对来说更合适:( )。
- 在双盲降噪自编码器实现降噪一节中,编码器中包含RNN和一维卷积,你觉得这么设计的初衷是什么( )。
- 切比雪夫距离、曼哈顿距离与欧式距离分别对应闵可夫斯基距离中q为几的情形( )
- SVM算法的性能取决于( )
- 异常值处理的3σ准则中,σ的含义为( )
- 与自编码器相比,变分自编码器的优势在于( )
- 用距离度量样本间相似性时,距离越____时样本越相似;用相似系数衡量变量间相似性时,相似系数越____时变量越相似。( )。
- 对数据进行归一化操作,( )影响典型相关分析的结果
- 变分自编码器中衡量分布之间差异的指标是( )。
- DBDAE降噪,训练过程中停止训练是因为( )。
- 工业蒸汽量预测是一个( )问题。
- 对于糖尿病的血糖预测,我们可以考虑使用( )方法。
- 一般情况下我们在模型训练及调参前要先进行数据分析预处理以及特征工程,这是十分必要的一环( )。
- 双盲降噪自编码器中的“双盲”是指( )。
- 关于变分自编码器VAE,以下说法正确的有:( )
- 下面哪一种算法属于生成式模型( )。
- 自编码器的训练属于半监督学习。( )
- 在稀疏自编码器中,假设神经元采用tanh作为激活函数,则:( )
- 关于去噪自编码器DAE,以下说法错误的是:( )
- 相较于传统RNN,LSTM引入了独特的门控机制。以下哪些是LSTM中包含的门结构:( )
- 关于卷积神经网络CNN与循环神经网络RNN,下面说法正确的有:( )
- 关于卷积神经网络CNN,以下说法错误的是:( )
- 下面哪个函数不是神经元的激活函数( )
- 为了提高预测结果的精度,网络结构设置得越复杂越好,不必考虑训练网络时所花费的时间。( )
- 关于典型相关分析CCA与主成分分析PCA,下面说法错误的是( )
- CCA算法在求解时,分别在两组变量中选取具有代表性的综合变量Ui,Vi,每个综合变量是原变量的线性组合,选择综合变量时的目标是( )
- 典型相关分析适用于分析两组变量之间的关系( )
- 传统典型相关分析的基本假设包括( )
- 相比于普通CCA算法,Kernel CCA( )
- 随机森林有哪些优点( )。
- 随机森林只能选择决策树作为基分类器。( )
- 随机森林的随机性体现在哪里( )
- 对于离散型随机变量X,它的熵取决于( )。
- 在Bootstrap自助采样法中,真实的情况是( )。
- 聚类算法是一种( )的学习方式。
- 理想情况下,K均值算法中确定类别个数的最佳方式为( )。
- 在利用EM算法估计高斯混合模型参数的时候,需要预先设定的参数有( )。
- 闵可夫斯基距离是一组距离的定义,下列距离中属于闵可夫斯基距离的有( )
- 在区分某个算法是否是聚类算法时,往往可以通过该算法是否需要预先设定明确的类中心来判断( )。
- 一元线性回归有哪些基本假定?( )
- 最小二乘方法的拟合程度衡量指标是( )。
- 岭回归适用于样本很少,但变量很多的回归问题。( )
- 最典型的两种拟合不佳的情况是( )。
- 关于最小二乘法,下列说法正确的是。( )
- 拉格朗日乘子法可用于线性可分SVM的模型求解。( )
- 以下说法正确的有哪些( )
- 下面哪个是SVM在实际生活中的应用( )
- SVM的中文全称叫什么?( )
- SVM算法的最小时间复杂度是O(n²),基于此,以下哪种规格的数据集并不适该算法?( )
- 少量的异常值完全不会影响数据分析。( )
- 一般常见的缺失值处理的方法有( )
- 下列哪种方法不是数据填补的手段 ( )
- 主成分分析的英文名是( )。
- 一般常见的数据归一化的方法有( )
- 多元统计分析的图表示法有( )
- 下列场景适用于回归分析的是 ( )
- 下列属于多元统计方法的为( )
- 完整的数据分析过程,包括数据采集、数据清洗和数据分析。( )
- 下面哪一句体现了主元分析的思想( )
答案:对
答案:错
答案:对
答案:对
答案:错
答案:错
答案:对
答案:错
答案:错
答案:错
答案:对
温馨提示支付 ¥5.00 元后可查看付费内容,请先翻页预览!

