提示:内容已经过期谨慎付费,点击上方查看最新答案
医学统计学(高级篇)
- K-均值聚类也称为动态聚类或逐步聚类。( )
- 方差分析(Analysis of Variance,ANOVA) 由英国统计学家 Fisher 于1918年提出。( )
- 主成分分析中各主成分的方差是依次递增。( )
- Fisher判别的思想是寻找类间变异小,类内变异大的最优投影方向。( )
- 一般情况下,采用逐步回归法选择变量与前进法和后退法选择变量所获得的结果相同。( )
- 因子分析中公共因子间是独立的,特殊因子间是独立的,公共因子与特殊因子间也是独立的。( )
- 各主成分的的方差之和小于原始变量的方差之和。( )
- 聚类分析需要研究者事先指定分类的数目。( )
- Logistic回归是研究分类反应变量与一些影响因素之间关系的一种多变量分析方法。( )
- 多重线性回归分析中,复相关系数反映了回归平方和在应变量Y的总离均差平方和中所占比重的大小。( )
- 判别效果一般用错判率或准确率来衡量。( )
- 多重线性回归分析要求资料满足线性、独立性、正态性和方差齐性条件。( )
- Logistic回归利用最小二乘法进行模型的参数估计。( )
- 在多个均数的比较中,若不采用方差分析,而用t检验对每两个均数作比较,会加大犯I型错误的概率。( )
- 生存率实质上是累积生存概率。( )
- 从各自变量偏回归系数的大小,可以反映出各自变量对应变量影响作用贡献的大小。( )
- LSD-t检验敏感度高,适用于探索性研究。( )
- Bayes判别中,若样本量大且代表性好,可由训练样本中各类的构成比作为先验概率的估计值。( )
- 因子分析(factor analysis)就是从相关的可观测指标中提炼出较少的几个共同指标,即公共因子(common factor),把实测变量表示成公共因子的线性函数与特殊因子(unique factor)之和。( )
- 四组均数比较,若F>F0.05(3,28),则可认为各总体均数间差别均有统计学意义。( )
- 距离判别的判别指标只能是定量指标。( )
- log-rank检验可以处理删失值,所以生存时间不必非常精确。( )
- 整体回归效应的假设检验中拒绝H0,表示引入回归方程中的每一个自变量都与因变量Y有线性回归关系。( )
- 设立平行对照的前后测量资料,对交互作用的检验等价于两独立样本差值比较的t检验。
- K-均值聚类和两步聚类既可以用于样品聚类,也可以用于变量聚类。( )
- Bayes判别中考虑先验概率一定能提高类别的敏感性。( )
- 抽样调查了某地四年级48名女大学生的肺活量与体重、胸围和肩宽的数据,如用体重、胸围和肩宽来预测肺活量的大小,应选用的统计分析方法是( )。
Cox回归与logistic回归比较( )。
- 多重线性回归分析中的共线性是指( )。
- 关于生存曲线正确的描述是( )。
- 多重线性回归分析中的应变量是( )。
- 16只体表接种绒癌的裸鼠随机分为2组,分别接受天花粉和对照药物注射,得到生存时间(天)如下:

适宜的统计描述与组间生存时间比较方法为( )。 - 有人对103例冠心病患者和100例正常对照者进行了多项指标的观测。指标有:性别、年龄、高血压史、吸烟史、胆固醇、甘油三酯、低密度脂蛋白、高密度脂蛋白、子蛋白
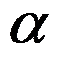 、载子蛋白As、载子蛋白B、基因型xbaI、基因型EcoRI和药物。对冠心病人而言,试对七项血脂指标间的内部从属性做客观评价,最好选用什么统计方法( )。
、载子蛋白As、载子蛋白B、基因型xbaI、基因型EcoRI和药物。对冠心病人而言,试对七项血脂指标间的内部从属性做客观评价,最好选用什么统计方法( )。 - 下列有关生存率估计的乘积极限法的描述中不正确的是( )。
- 在某项出生缺陷研究中,收集了几十个指标,希望把这些指标进行分类,每一类都可以用一个综合指标反映,可选用( )。
- 逐步回归分析中,若增加引入的自变量,则( )。
- 下表是急性白血病患者药物诱导后缓解至首次复发的随访记录。
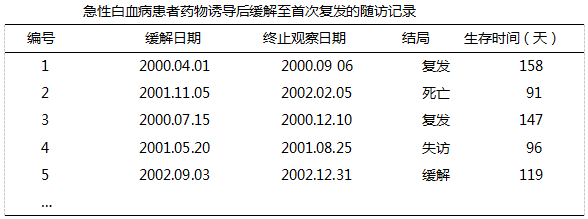
生存时间属删失数据的有( )。 - 多重线性回归分析中,若对某一自变量的值乘以一个不为零的常数K,则有( )。
- 完全随机设计资料的方差分析中,必然有( )。
- 为了评价各医院的医疗工作质量,每个医院按相同的10个指标评分,为了反映这10个指标的内在联系,如哪些指标关系密切、可否用少量综合指标反映这10个指标的大部分信息等,可选用的统计方法有( )。
- 方差分析的应用条件是( )。
- 关于Logistic回归的应用条件,以下说法正确的是( )。
- 以下关于主成分分析的表述正确的是( )。
- 主成分分析的目标有( )。
- 下面说法中正确的是( )。
- 以下关于主成分分析和因子分析的说法正确的是( )。
- 关于Logistic回归的用途,以下说法正确的是( )。
A:对 B:错
答案:对
A:对 B:错
答案:对
A:错 B:对
答案:错
A:错 B:对
答案:错
A:错 B:对
答案:错
A:对 B:错
AI参考:答案是B:错。在因子分析中,公共因子之间、特殊因子之间以及公共因子与特殊因子之间通常不是独立的,它们之间存在一定的关系和影响。通过因子分析,可以将原始变量分解为多个因子变量的线性组合,其中每个公共因子或特殊因子都对一组变量有影响,它们之间不是完全独立的。因此,这个判断题是错误的。'
A:错 B:对
A:对 B:错
A:对 B:错
A:错 B:对
A:错 B:对
AI参考:答案是B:对。判断题中描述的是正确的,因为判别效果一般用错判率或准确率来衡量,其中准确率是正确的,它指的是真正例数(True Positive)和假正例数(False Negative)的总和与真正例数的比例,而错判率是错误的,它指的是假正例数(False Positive)和假负例数(False Negative)的总和与假负例数的比例。因此,这个说法是正确的。'
A:错 B:对
A:对 B:错
A:错 B:对
AI参考:B:对。t检验主要用于配对设计或多个独立样本的比较,但它的本质仍然是基于两组的均值之差来比较不同组间的效果,所以在多个均数的比较中,若不采用方差分析,而用t检验对每两个均数作比较,会增加犯I型错误的概率(即错误地认为两个样本平均数差异显著,而实际上并无此差异)。'
A:对 B:错
AI参考:正确。生存率是指生存的个体在一段时间后的比例,实质上是累积生存概率。因此,答案为A:对。'
A:错 B:对
A:对 B:错
AI参考:答案是B:错。LSD-t检验是一种用于比较两组均值的检验方法,适用于配对设计或独立样本设计的数据分析。虽然LSD-t检验具有一定的敏感性,但其主要用于探索性研究的单因素分析,通常用于比较不同组之间的差异,而不是用于探索新的潜在变量或因素。探索性研究需要更多的方法和技术,如因子分析、结构方程模型等,以更好地探索数据中的潜在结构和关系。因此,LSD-t检验不适用于探索性研究。'
A:对 B:错
A:错 B:对
A:错 B:对
A:对 B:错
A:对 B:错
A:错 B:对
A:错 B:对
A:对 B:错
A:对 B:错
A:方差分析 B:多重线性回归分析 C:Cox回归分析 D:Logistic回归分析 E:t检验
AI参考:正确答案是B:多重线性回归分析。题目中描述的是通过观察体重、胸围和肩宽等指标来预测肺活量的大小,而体重、胸围和肩宽是连续变量,且它们之间可能存在一定的相关性,因此需要使用多重线性回归分析来进行统计分析。方差分析主要用于比较两个或多个样本之间的差异,不适用于本题。Cox回归分析是一种生存分析方法,适用于处理寿命数据,不适用于本题。Logistic回归分析主要用于处理分类变量,不适用于本题。t检验适用于两个独立样本的比较,也不适用于本题。因此,答案为B。'
A:Cox回归适用于长期随访研究 B:二者结果一致 C:二者的自变量都是连续变量 D:二者的因变量都是二分类变量 E:logistic回归更适用于长期随访研究
AI参考:正确答案是D.二者的因变量都是二分类变量。Cox回归与Logistic回归都是生存分析中的回归方法,用于分析生存时间(即事件发生的时间)和生存结局之间的关系。Cox回归适用于所有类型的数据,包括二分类变量和连续变量,而Logistic回归只能处理二分类因变量。因此,选项A、C、E错误。在生存分析中,二者的结果通常不一致,因此选项B错误。综上所述,选项D是正确的答案。'
A:Y与自变量间有较高的相关性 B:自变量间有较高的相关性 C:Y关于各个自变量的回归系数与截距都相同 D:Y与各个自变量的相关系数相同 E:Y关于各个自变量的回归系数相同
A:此曲线是严格下降的 B:纵坐标为生存概率 C:曲线平缓表示预后较好 D:横坐标中点为中位生存期 E:寿命表法生存曲线呈阶梯型
AI参考:关于生存曲线正确的描述是纵坐标为生存概率。生存曲线是一种表示个体在一定时间段内生存状态的方法,它描述了受试者在特定时间段内存活的可能性。纵坐标通常表示生存概率,即受试者在特定时间段内存活的可能性。选项A错误,因为生存曲线不一定是严格下降的。选项C错误,因为曲线平缓表示预后好坏并不是生存曲线的描述内容。选项D和E也与生存曲线的描述无关。因此,正确答案是B:纵坐标为生存概率。'
A:完全数据 B:生存时间和结局变量 C:正态的和方差齐性的 D:结局变量 E:生存时间
A:生存曲线与log-rank检验 B:算术均数与生存曲线 C:中位生存期与生存曲线 D:几何均数与秩和检验 E:算术均数与t检验
AI参考:正确答案是:C:中位生存期与生存曲线。题目中提到的是生存时间(天),即患者从开始治疗到疾病死亡的时间,因此应选用生存分析。故选用C项(中位生存期与生存曲线)作为统计描述方法,符合该情况的应为中位生存期为预后观察的较好指标。该研究中还用了D项作为统计学处理的方法(rank-sum test或Mann-Whitney U检验)组间生存时间的比较,但在没有分层或者具有相似或更优结果的队列的研究中比较统计方法和疗效比较研究有一定的混淆。BDE选项分别是数值变量组间比较常用的平均数比较、非参数样本的平均数比较及连续性变量参数化的计算指标(连续变量比值分布计算的描述方法)。综合而言,C项为最佳选项。故答案为C。'
A:典型相关分析 B:判别分析 C:多重线性回归 D:主成分分析
AI参考:正确答案是A:典型相关分析。典型相关分析是一种在两个变量集合之间寻找主要关系的方法,特别适合于两个变量间存在多重共线性的情况。对于冠心病患者和正常对照者的血脂指标,由于指标间存在多重共线性,因此选用典型相关分析可以更好地评价七项血脂指标间的内部从属性。而多重线性回归、主成分分析和判别分析等方法可能无法有效地处理这种情况。因此,答案为A。'
A:乘积极限法适用于大样本分组资料 B:乘积极限法适用于大样本未分组资料 C:乘积极限法利用概率乘法定理来计算生存率 D:乘积极限法适用于小样本未分组资料 E:乘积极限法即Kaplan-Meier法
A:聚类分析 B:多重回归分析 C:因子分析 D:logistic回归分析 E:cox回归分析
AI参考:正确答案是C:因子分析。因子分析是把一些具有错综复杂关系的变量综合为少数几个因子的一种多变量统计方法,这和题目中的需求是一致的。题中想要将指标分类并建立一个综合指标来反映每一类指标的特点,所以应选用因子分析。因此,答案为C。聚类分析是一种对事物进行分类的方法,和题意不符;多重回归分析、logistic回归分析、cox回归分析都是回归分析方法,虽然也可以用于分类,但不如因子分析全面;因此,BDE选项不符合题意。'
A:总平方和与回归平方和均增大 B:回归平方和增大,残差平方和减少 C:回归平方和与残差平方和均减少 D:总平方和与残差平方和均增大 E:总平方和与回归平方和均减少
A:1号和3号 B:2号、4号和5号 C:1号、2号和3号 D:2号、3号和4号 E:1号和2号
AI参考:正确答案是E。在表1中,数据描述了患者的生存时间(时间单位:月),各选项都与时间有关。只有E项是所有记录均含时间信息的描述性句子,是最佳答案。BCD三项描述了部分患者,不是所有患者,所以不正确。A项仅涉及了1号和3号,也未包含所有患者,所以也不正确。因此,正确答案是E。'
A:该偏回归系数值为原有偏回归系数值的1/K B:所有偏回归系数值均会改变 C:所有偏回归系数值均不会改变 D:该偏回归系数的值不变 E:该偏回归系数值会改变,但无规律
A:SS组间>SS组内 B:ν组内>ν组间 C:MS组间>MS组内 D:MS总=MS组间+MS组内 E:SS总=SS组间+SS组内
A:多重回归分析 B:Logistic回归 C:因子分析 D:主成分分析 E:主成分分析和因子分析均可
AI参考:正确答案是E:主成分分析和因子分析均可。为了评价各医院的医疗工作质量,每个医院按相同的10个指标评分,为了反映这10个指标的内在联系,如哪些指标关系密切、可否用少量综合指标反映这10个指标的大部分信息等,可以使用主成分分析和因子分析方法,因为这两种方法都能够从多个变量中提取主要成分或公因子,进而简化数据,更好地反映出数据的本质。所以选项E“主成分分析和因子分析均可”是正确的。选项A、B、D均不适用于此目的。'
A:各样本是随机样本 B:各样本的总体方差相等,即方差齐性 C:各样本的总体均数相等 D:各样本相互独立 E:各样本均服从正态分布
A:自变量必须是分类变量 B:反应变量与自变量的关系是曲线关系 C:要求观察对象间独立 D:logit(P)与自变量的关系是线性关系 E:反应变量是分类变量
AI参考:关于Logistic回归的应用条件,以下说法正确的是:Dlogit(P)与自变量的关系是线性关系 和 E:反应变量是分类变量。Logistic回归是一种用于分析二分类或多分类问题的统计方法,其应用条件包括:1. 反应变量是连续变量或分类变量;2. 自变量可以是连续变量或分类变量;3. 观察对象间存在一定的关联性,但不能要求独立;4. logit(P)与自变量的关系是线性关系,即P的对数与某个线性组合的关系。因此,选项A、B、C的说法是不正确的。'
A:各主成分的方差等于计算该主成分时所依据的原始变量的协差阵或相关阵的各特征根 B:各主成分的方差是依次递减(或不增)。 C:各个主成分之间相互相关, D:主成分是原变量的线性组合。 E:主成分分析多数是作为进一步分析的中间过程
A:找出主成分与原始变量的线性组合。 B:按各主成分方差大小排序(按“重要性”排序) C:主成分个数可以多于原始变量个数 D:利用主成分得分,可以对样品的特性进行推断和评价 E:各主成分之间互不相关(各主成分信息不重合)
A:方差分析可以用于两个样本均数的比较 B:完全随机设计更适合实验对象变异不太大的资料 C:在随机区组设计中,每一个区组内的例数都等于处理数 D:在随机区组设计中,区组内及区组间的差异都是越小越好
A:因子分析得到的因子是相关的 B:因子分析是把各变量表示成公共因子与特殊因子的线性组合 C:主成分分析中的主成分是综合指标且互相无关 D:主成分分析是把主成分表示成各变量的线性组合 E:因子分析得到的因子具有较强的可解释性
A:可以进行分类预测 B:可以用于影响因素分析 C:可以进行判别分析 D:只可以用影响因素分析 E:可以用于校正混杂因素
温馨提示支付 ¥1.75 元后可查看付费内容,请先翻页预览!

