黑龙江八一农垦大学
- 关于聚类分析和判别分析叙述正确的是( )。
- 下列说法正确的是( )。
- 关于主成分分析,下列说法正确的是( )
- 关于拟合优度检验正确的是( )
- 下列说法正确的是( )
- 常见的计算类与类之间距离的方法有( )
- 下列关于绘制雷达图叙述不正确的是( )
- 关于Fisher判别法叙述正确的是( )
- 下列说法错误的是( )
- 残差是指( )
- 关于主成分分析的说法错误的是( )
- 在双因素多元方差分析中,总离差阵、因素A离差阵、因素B的离差阵、组内离差阵之间的关系是( )
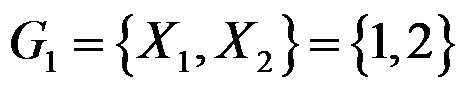 ,
,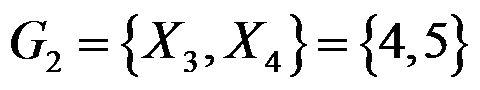 ,
,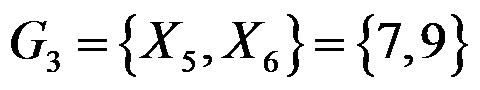 ,在用离差平方和法将这三类合并过程中,
,在用离差平方和法将这三类合并过程中,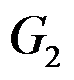 的离差平方和
的离差平方和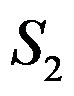
 为( )
为( )- 在主成分分析中,主成分的协方差阵为( )
- 出现下列哪些情况,有可能存在高度多重共线性( )
- 设某客观现象可用

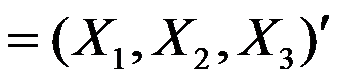 来描述,在因子分析时,从约相关阵出发计算出特征值为
来描述,在因子分析时,从约相关阵出发计算出特征值为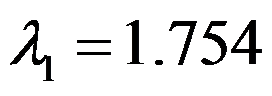 ,
,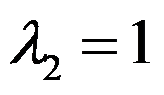 ,
,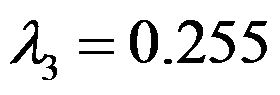 .则第一个公因子的贡献率为( )
.则第一个公因子的贡献率为( ) - 样本主成分的总方差等于( )
- 对A、B、C、D四个样品进行K均值聚类,分别测量两个变量
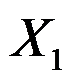 和
和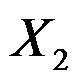 ,A(5,3), B(-1,1), C(1,-2) ,D(-3,-2) ,将样品随意分成(A、B)和(C、D)两类,则(A、B)的中心坐标为( )
,A(5,3), B(-1,1), C(1,-2) ,D(-3,-2) ,将样品随意分成(A、B)和(C、D)两类,则(A、B)的中心坐标为( ) - 在多元回归分析中,许多非线性回归可通过变量代换转化为多元线性回归。( )
- 在主成分分析中,只能基于相关系数矩阵计算主成分。( )
- 将表示
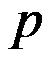 个变量取值的点连接成一条折线,可以得到一个样品观测数据的折线图。( )
个变量取值的点连接成一条折线,可以得到一个样品观测数据的折线图。( ) - 条形图是由若干平行条状的矩形所构成,但每一个矩形的宽度不相等。( )
- 在判别分析中,待判样本是指对于新给出的样本,如果判别函数效能较高,则计算出每一个样本的判别函数值,并根据判别准则对新样本进行归类判别。( )
- 多元线性回归方程的检验也利用平方和分解原理。( )
- 根据自变量的多少回归分析可分为线性回归和非线性回归。( )
- 将表示
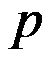 个变量
个变量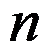 次观测取值的点连接成
次观测取值的点连接成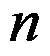 条折线,构成多变量折线图。( )
条折线,构成多变量折线图。( ) - 在主成分分析中,各个主成分的综合能力依次递减。 ( )
- 在Q型聚类中,常用“相似系数”度量变量间的相似性。( )
- 判别准则是根据样本的判别函数值进行分类的法则。( )
- 三维散点图是以立体图的形式展现多对变量的散点图。( )
- 在单因素多元方差分析中,总离差阵反映的是样本数据与其组平均值的差异。( )
- 多元回归分析是对一个因变量和一个自变量建立回归方程。( )
- 在因子分析中,变量共同度越接近于1,说明因子分析越有效。( )
- 主成分与原始变量的相关系数称为因子载荷量。 ( )
- 在聚类分析中,对变量的分类为Q聚类。( )
- 在判别分析中,回代样本是指计算出每一个样本的判别函数值,并根据判别准则将样本归类。( )
- 主成分的协方差矩阵为对称矩阵。( )
- 在R型聚类中,常用“距离”度量变量间的相似性。( )
- 因子分析是把每个原始变量分解为两部分因素,一部分是由所有变量共同具有的少数几个公共因子构成的;另一部分是每个原始变量独自具有的因素,即所谓的特殊因素部分或特殊因子部分。( )
- 系统聚类的基本思想是距离相近的样品(或变量)先聚成类,距离相远的后聚成类,每个样品(或变量)最终总能聚到合适的类中。( )
A:聚类分析事先对总体到底有几种类型无所知晓。
B:判别分析是根据一定的判别准则,判定一个样本归属于哪一类。
C:判别分析则是在总体类型划分已知前提下对新样品进行分类。
D:判别分析可以对样本或指标进行分类。
答案:判别分析是根据一定的判别准则,判定一个样本归属于哪一类。###判别分析则是在总体类型划分已知前提下对新样品进行分类。###聚类分析事先对总体到底有几种类型无所知晓。
A:R型聚类和Q型聚类在数学上不是对称的,各不相同。
B:在聚类分析中,按照变量对观测值(事件,样品)来分类,称为Q型聚类。
C:聚类分析按照分类对象在性质上的相似性或疏远程度进行科学的分类。
D:在聚类分析中,按照观测值对变量(或指标)进行分类,称为R型聚类。
答案:A: 错误 B: 正确 C: 正确 D: 错误
A:前k个主成分的累积贡献率反应了前k个主成分共有多大的综合能力。
B:主成分分析能降低所研究的数据空间的维数。
C:随机变量协方差矩阵的对角线上的元素之和等于特征根之和。
D:第i个主成分的贡献率反应了该主成分的方差在全部方差中所占比重。
答案:随机变量协方差矩阵的对角线上的元素之和等于特征根之和。###前k个主成分的累积贡献率反应了前k个主成分共有多大的综合能力。###第i个主成分的贡献率反应了该主成分的方差在全部方差中所占比重。###主成分分析能降低所研究的数据空间的维数。
A:一般采用调整的判定系数来进行拟合优度检验,以消除自变量的个数以及样本量的大小对判定系数的影响。
B:拟合优度检验主要通过判定系数来实现。
C:拟合优度检验可以评价回归方程对样本数据的代表程度。
D:回归方程的拟合优度检验就是要检验样本数据点聚集在回归直线周围的密集程度
答案:回归方程的拟合优度检验就是要检验样本数据点聚集在回归直线周围的密集程度###拟合优度检验主要通过判定系数来实现。###拟合优度检验可以评价回归方程对样本数据的代表程度。###一般采用调整的判定系数来进行拟合优度检验,以消除自变量的个数以及样本量的大小对判定系数的影响。
A:在聚类分析中,常用度量相似或疏远程度的指标有距离和相似系数。
B:聚类分析是将一批样品、变量(或指标),按照它们在性质上相似、疏远程度进行科学的分类。
C:K-均值聚类又称为快速聚类。
D:系统聚类又叫做分层聚类。
答案:在聚类分析中,距离越短,表明两样本点间相似程度越高###两点间距离公式可以从不同角度进行定义###在对多个指标进行聚类时,采用相似系数衡量变量间的关联程度
A:最短距离法。
B:重心法。
C:离差平方和法。
D:最长距离法。
答案:最长距离法。###重心法。###最短距离法。###离差平方和法。
A:按变量的个数
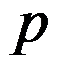 将圆周分成
将圆周分成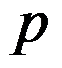 等分。
等分。B:根据各变量的取值对各坐标轴作适当刻度。
C:对给定的一次观测值,将每个变量值分别标在相应的坐标轴上,把
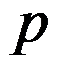 个点相连就形成了一个
个点相连就形成了一个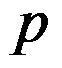 边形。
边形。D:连接圆心和各分点,将
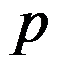 条半径连线依次定义为各变量的坐标轴。
条半径连线依次定义为各变量的坐标轴。答案:

A:Fisher判别法也叫线性判别法。
B:Fisher判别法对总体的分布不做任何要求。
C:Fisher判别法是根据方差分析的思想建立起来的。
D:Fisher判别法需要各总体的分布是已知的。
答案:Fisher判别法也叫线性判别法。###Fisher判别法对总体的分布不做任何要求。###Fisher判别法是根据方差分析的思想建立起来的。
A:常用的距离有明可夫斯基距离、马氏距离和兰氏距离等。
B:对样品进行聚类分析时,常用距离来测定样品之间的相似程度。
C:在用距离测定样品之间的相似程度时,把n个样本看作p维空间的n个点,点之间的距离即可代表样品间的相似度。
D:在对多个对变量进行聚类分析时,常用相关性衡量变量间的相似性。
答案:A、C
A:真实值与预测值之间的差。
B:观测值与拟合值之间的差。
C:预测值与估计值之间的差。
A:每个主成分的系数平方和为1。
B:主成分的方差依次递减,重要性依次递增。
C:主成分之间相互独立,即无重叠的信息。
D:主成分分析把n个随机变量的总方差分解成为n个不相关的随机变量的方差之和。
A:总离差阵=因素A离差阵+因素B的离差阵+组内离差阵 B:总离差阵=因素A离差阵+因素B的离差阵-组内离差阵 C:因素A离差阵=组间离差阵-总离差阵 D:因素B离差阵=组内离差阵-总离差阵
A:0
B:2
C:1
D:0.5
A:正定阵。
B:对角阵。
C:非正定阵。
D:非对角阵。
A:F检验显著,但所有回归系数的t检验却不显著
B:F检验不显著,但所有回归系数的t检验显著
C:F检验显著,所有回归系数的t检验也显著
D:F检验不显著,所有回归系数的t检验也不显著
A:58.3%
B:33.2%
C:1
D:91.5%
A:0。
B:1。
C:主成分个数m。
D:变量个数n。
A:(0,-0.5)
B:(-1,-2)
C:(2,2)
D:(3,0.5)
A:对 B:错
A:错 B:对
A:错 B:对
A:错 B:对
A:错 B:对
A:错 B:对
A:对 B:错
A:对 B:错
A:错 B:对
A:对 B:错
A:错 B:对
A:错 B:对
A:对 B:错
A:对 B:错
A:错 B:对
A:对 B:错
A:对 B:错
A:对 B:错
A:错 B:对
A:对 B:错
A:对 B:错
A:对 B:错
温馨提示支付 ¥5.00 元后可查看付费内容,请先翻页预览!



