提示:内容已经过期谨慎付费,点击上方查看最新答案
网络数据爬取与处理
- 用字典类型的数据来创建一个DataFrame时,它会自动的将以下哪一项作为列名( )。
- 执行以下程序输出的结果是( )。
import pandas as pd
s=pd.Series([3,5,6,7,9],index=['a','b','c','d','e'])
print(list(s[['d','a']])) - 变量df的值如图所示,执行以下代码后输出的结果是( )。
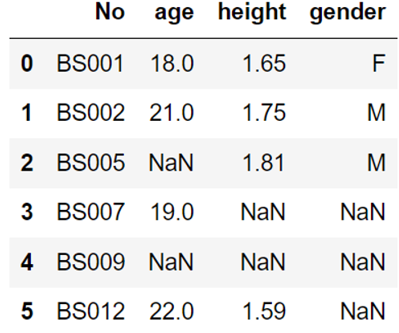
print(df['gender'].isnull().sum() - 以下关于dataframe的连接描述错误的是( )。
- 以下关于重复值的处理描述错误的是( )。
- 以下关于时间序列dataframe描述错误的是( )。
执行以下程序输出的结果是( D)。
from bs4 import BeautifulSoup
html='<html><p>ss<a id="name1">Alice</a></p><a id="name2">Amy</a></html>'
soup=BeautifulSoup(html,'html.parser')
soup.select('#name2')
- 使用以下哪一种方法,可以将字符串中的英文字符转换为小写字母( )。
- 执行以下程序输出的结果是( )。
from bs4 import BeautifulSoup
html='<html><p class="story">ss<a id="name1">Alice</a></p><a id="name2">Amy</a></html>'
soup=BeautifulSoup(html,'html.parser')
print(soup.a.attrs) 以下关于dataframe描述错误的是(C)。
- 下列第三方库中,哪个库可以用于从HTML或XML文件中提取数据( )。
- 下列描述错误的是( )。
- 关于groupby方法,以下描述错误的是( )。
- 变量df的值如图所示,执行以下代码后返回的结果是( )。

df[df.duplicated() - 运行以下程序后的结果是( )。
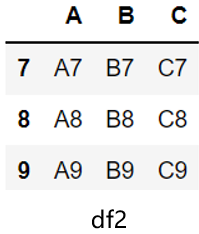
- 变量df1与df2的值如下图所示,执行以下程序后,变量df的值为( )。
df=pd.concat([df1,df2])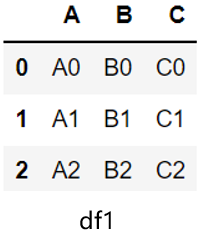
- 以下关于实现网络爬虫的描述中,错误的是( )。
- 执行以下程序输出的结果是( D)。
import pandas as pd
d={'one':[1,3,5,7],'two':[2,4,6,8]}
df=pd.DataFrame( )
df['three']=df['two']-df['one']
df.index=['a','b','c','d']
print(df.loc[['a','d']]) 执行以下程序输出的结果是( C)。
from bs4 import BeautifulSoup
html='<html><p>ss<a id="name1">Alice</a></p><a id="name2">Amy</a></html>'
soup=BeautifulSoup(html,'html.parser')
soup.select('p a')
- 以下关于requests的描述中,正确的是( )。
- 时间序列变量df的值如图所示,执行以下代码后返回的结果是( )。
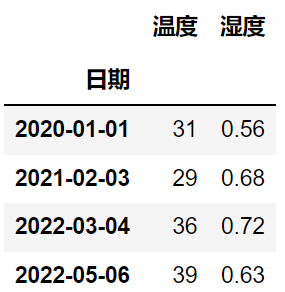
df[(df.index.month==2)|(df.index.year==2022)] - 执行以下程序输出的结果是( )。
from bs4 import BeautifulSoup
html='<html><p class="story">ss<a id="name1">Alice</a></p><a id="name2">Amy</a></html>'
soup=BeautifulSoup(html,'html.parser')
soup.select('p') - 可以通过.iloc()方法按dataframe的自定义索引引用行。( )
- pandas库的concat()方法可以将两个dataframe在任意列上对齐连接。( )
- pandas库的concat()方法只能同时连接两个dataframe。( )
- dataframe的groupby()方法同时对多个字段分组时将返回具有多层索引的dataframe。( )
- CSS主要用于描述网页的样式。( )
- dataframe的fillna()方法将返回填充缺失值后的新dataframe。( )
- dataframe的isnull()方法可以查询缺失值。( )
- 与series不同的是dataframe没有行索引。( )
- 正则表达式+表示其前一个字符重复1次或多次。( )
- requests库是处理正则表达式的第三方库。( )
- 正则表达式是Python所有的。( )
- re库的findall()方法默认只从原字符串中返回第一个匹配的子串。( )
- pandas库的merge()方法可以将两个dataframe在任意列上对齐连接。( )
- json库的dumps()方法可将python对象转换为json字符串。( )
- dataframe的drop_duplicates()方法将返回删除重复行后的新dataframe。( )
- Json可以独立于网页的结构与样式传输数据。( )
- 正则表达式由普通字符、元字符与预定义字符构成。( )
- dataframe的drop()默认在原对象上删除行或类。( )
- dataframe的apply()方法能够将自定义函数应用到dataframe的所有元素。( )
- csv库的to_csv()方法可以将dataframe写入到csv或txt格式的文本文件。( )
- 网络爬虫可以自动获取互联网数据。( )
- dataframe的apply()方法不能将python的标准函数应用到行或列。( )
- dataframe的dropna()方法将返回删除包含缺失值行后的新dataframe。( )
- 可以通过dataframe的index属性修改行索引。( )
- 关于re.findall()方法描述正确的是( )。
- 关于标签树与标签描述正确的是( )。
A:字典的键 B:字典的键值对 C:字典的值 D:字典的索引
答案:字典的键
A:[5,6] B:[7,3] C:[3,5] D:[6,7]
答案:
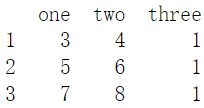
A: B: C:3 D:7
答案:7
A:merge()能够在行索引上对齐连接 B:merge()能够在任意列上对齐连接 C:concat()可以同时连接2个以上的dataframe D:concat()只能在行索引或列索引上对齐连接
答案:等价于二维的ndarray对象AI参考:选项B关于merge()能够在任意列上对齐连接描述错误。merge()函数只能在指定的行索引或列上进行对齐连接。它不支持在任意列上对齐连接。选项D是正确的,因为concat()函数只能在对齐行索引或列索引的情况下进行连接。而选项A和C在描述merge()和concat()的功能时是正确的。因此,答案是B:merge()能够在任意列上对齐连接。'
A:通过dataframe的duplicated()方法查询每一行是否重复 B:通过dataframe的drop_duplicates()方法可删除重复行 C:通过drop_duplicates()执行删除重复行操作,默认保留最后一条重复行 D:对于dataframe的重复行一般进行删除处理
答案:在重复博弈中,每次博弈的条件.规则和内容可以是不同的.AI参考:描述错误的是:C: 通过drop_duplicates()执行删除重复行操作,默认保留最后一条重复行。drop_duplicates()方法用于删除dataframe中的重复行,默认情况下是删除所有重复行,而不是只保留最后一条重复行。所以描述是错误的。其他选项均是正确的。A选项,通过dataframe的duplicated()方法可以查询每一行是否重复。B选项,通过dataframe的drop_duplicates()方法可以删除重复行。D选项,对于dataframe的重复行一般进行删除处理,这是数据分析中常见的方法。'
A:时间序列dataframe没有自动索引 B:行索引为datetime类型的dataframe可以进行时间序列操作 C:时间序列dataframe可以按年月日切片引用 D:时间序列dataframe的行索引具有weekofyear属性
AI参考:答案:D:时间序列dataframe的行索引具有weekofyear属性。解释:A选项正确,时间序列dataframe没有自动索引,需要手动创建索引。B选项正确,行索引为datetime类型的dataframe可以进行时间序列操作。C选项正确,时间序列dataframe可以按年月日切片引用。D选项错误,时间序列dataframe的行索引没有weekofyear属性,一般使用pandas库中的date_range函数生成的时间序列数据才有weekofyear属性。本题为选是题,故本题答案为D。'
A:[Amy] B:[Alice, Amy] C:[
ssAlice
] D:[Alice]A:upper( ) B:lower( ) C:replace( ) D:split( )
AI参考:正确答案是 B:lower( )。lower() 方法可以将字符串中的英文字符转换为小写字母。upper() 方法可以将字符串中的英文字符转换为大写字母。replace() 方法用于替换字符串中的特定字符或字符串。split() 方法用于将字符串按指定的分隔符拆分成多个子字符串。因此,正确答案为 B。'
A: dataframe每一列都有一个列名 B:dataframe没有行索引 C:dataframe的每一列就是一个series D:dataframe可以看成是一个由行列构成的二维表
AI参考:错误选项是(B):dataframe没有行索引。DataFrame是一种数据结构,它由行和列组成,每一列都有一个列名,每一行对应一个元素,并且可以看成是一个由行列构成的二维表。因此,它是有行索引的。所以,答案为(B):dataframe没有行索引。'
A:matplotlib B:urllib C:requests D:BeautifulSoup
AI参考:正确答案是D:BeautifulSoup。BeautifulSoup是一个用于从HTML或XML文件中提取数据的Python库,它可以解析HTML或XML文档并提取所需的数据。其他选项中,matplotlib是一个用于绘制图表的库,urllib是一个用于处理URL的库,requests是一个用于发送HTTP请求的库。因此,只有BeautifulSoup可以用于从HTML或XML文件中提取数据。'
A:Dom Tree是以树形结构的方式表示HTML或XML文档中标签的层次关系的数据类型 B:Tag对应标签树中的标签节点 C:BeautifulSoup库能够将HTML或XML文件解析为Dom Tree对象 D:BeautifulSoup内置的选择器语法中“#”指定标签的class属性
A:通过设置groupby方法的as_index参数,可以舍去分组后的行索引 B:groupby方法可对分组后的同一字段进行不同函数的聚合运算 C:groupby方法可对dataframe的多个字段分组 D:groupby方法不能对分组后的多个字段进行聚合运算
A: B: C:4 D:2
A:d B:{0123456789} C:[0-9] D:[0123456789]
AI参考:程序本身没有输出结果,因为它是一个空程序。因此,正确选项应该是D:【0123456789】。这个选项中的字符串"[0123456789]"是一个合法的字符序列,表示数字的集合。另外,由于该程序本身没有任何执行的操作,因此也无法得出任何特定的运行结果。值得注意的是,D选项是合理的答案,因为"[0123456789]"这个字符串在很多上下文中表示的是一个数字集合。但是,如果程序本身有特定的逻辑或操作,那么结果可能会有所不同。因此,无法根据空程序得出确切的结果。'
A: B: C: D:
A:通用爬虫爬取的数据量大,对爬取速度敏感 B:可通过Python的requests库实现聚焦爬虫 C:搜索引擎为通用爬虫 D:可通过Python的Scrapy库实现通用爬虫
A: B: C: D:
A: [Alice] B:[
ssAlice
] C:[Alice, Amy] D:[Amy]A:requests库可以处理HTTP协议 B:可通过requests库实现绘图功能 C:requests库是Python的标准库 D:可通过requests库实现字符串的正则表达式匹配
AI参考:正确答案是A:requests库可以处理HTTP协议。requests库是一个用于发送HTTP请求的库,可以处理HTTP协议,因此A选项是正确的。B选项关于绘图功能,需要使用其他的库,如matplotlib;C选项是Python的标准库的列表,requests库并不在其中;D选项关于字符串的正则表达式匹配,需要使用re模块,而不是requests库。'
A:空 B: C: D:
A:[Alice, Amy] B:[Amy] C:[Alice] D:[
ssAlice
]A:对 B:错
AI参考:正确答案是【对】。可以使用.iloc()方法按DataFrame的自定义索引引用行。'
A:对 B:错
AI参考:答案是B:错。pandas库的concat()方法可以将两个dataframe在指定列上对齐连接,而不是任意列。如果要连接两个dataframe在任意列上,可以使用merge()方法。因此,这个说法是错误的。'
A:对 B:错
AI参考:答案是B:错。pandas库的concat()方法可以同时连接多个dataframe。该方法用于将两个或更多DataFrame连接在一起,形成一个新的DataFrame。因此,这个判断题是错误的。'
A:错 B:对
AI参考:答案是B:对。在Python的Pandas库中,DataFrame的groupby()方法可以对多个字段进行分组,返回的结果是一个具有多层索引的DataFrame。因此,这个判断题是正确的。'
A:错 B:对
AI参考:答案是B:对。CSS主要用于描述网页的样式。CSS是一种用于描述HTML文档样式的语言,它可以帮助开发者控制网页的布局、颜色、字体等视觉元素,使网页更加美观和易于维护。因此,这个问题的答案是肯定的,即CSS主要用于描述网页的样式。'
A:对 B:错
AI参考:答案是A:对。根据Python pandas库中DataFrame的fillna()方法,它会将DataFrame中的缺失值(NaN)替换为指定的值,并返回填充后的新DataFrame。因此,该方法将返回填充缺失值后的新DataFrame。'
A:对 B:错
AI参考:正确答案是A:对。在Python的Pandas库中,DataFrame的isnull()方法可以用于查询DataFrame中的缺失值。该方法返回一个布尔型DataFrame,其中缺失值为True,非缺失值为False。因此,这个判断题的答案是A,即“对”。'
A:对 B:错
AI参考:答案是B:错。Series和DataFrame都是pandas库中的数据结构,Series只有一个索引,而DataFrame有行索引和列索引。因此,与Series不同的是,DataFrame有行索引。所以这个说法是错误的。'
A:错 B:对
AI参考:答案是B:对。+表示其前面的字符可以出现一次或多次,是正则表达式的常用语法。'
A:对 B:错
AI参考:答案是B:错。requests库是用于发送HTTP请求的第三方库,它并不处理正则表达式。要处理正则表达式,需要使用其他的第三方库,如re库。'
A:错 B:对
AI参考:答案是A:错。虽然Python中可以使用正则表达式模块re来处理正则表达式,但是正则表达式并不是Python的全部功能,它只是Python中处理字符串的一种工具。Python还提供了其他字符串处理方法,如字符串连接、替换、分割等。因此,这个说法是错误的。'
A:错 B:对
AI参考:答案:A:错。re库的findall()方法会返回所有匹配的子串,并不会只返回第一个匹配的子串。findall()方法会按照正则表达式的匹配规则,返回所有匹配的子串列表。如果需要获取第一个匹配的子串,可以使用find()方法。'
A:错 B:对
AI参考:答案是B:对。Pandas库的merge()方法可以将两个dataframe在指定的列上对齐连接,而不是在任意列上。需要指定连接的列,可以选择按照某一列进行连接,也可以按照多列进行连接。所以这个说法是正确的。'
A:错 B:对
AI参考:答案是B:对。json库的dumps()方法可以将Python对象转换为JSON字符串。这个方法可以将Python对象(如字典、列表、字符串等)转换为JSON格式的字符串,以便于在网络中传输或存储到文件中。'
A:错 B:对
AI参考:答案是B:对。在Python的pandas库中,DataFrame的drop_duplicates()方法用于删除重复的行,并返回一个新的DataFrame对象,因此这个判断题是正确的。'
A:对 B:错
AI参考:答案:A。Json是一种数据交换格式,它可以独立于网页的结构与样式传输数据。因此,答案为A,表示正确。'
A:对 B:错
AI参考:答案是A:对。正则表达式是由普通字符(称为元字符)和特殊字符(称为正则表达式元字符)组成的,用于描述或匹配一些文本模式。这些普通字符和预定义字符共同构成了正则表达式的语法。因此,这个判断题的答案是肯定的,即正则表达式由普通字符、元字符与预定义字符构成。'
A:对 B:错
AI参考:答案是B:错。在Pandas库中,DataFrame的drop()函数可以删除指定的行或列,但是它并不会在原对象上进行删除,而是返回一个新的DataFrame对象。原对象并不会发生改变。因此,这个判断题是错误的。'
A:对 B:错
AI参考:正确答案是A:对。在Python的Pandas库中,DataFrame的apply()方法可以将自定义函数应用到DataFrame的所有元素上。因此,这个判断题的答案是A,即“对”。'
A:对 B:错
AI参考:答案是A:对。根据题目描述,csv库的to_csv()方法可以将dataframe写入到csv或txt格式的文本文件。因此,该方法可以将dataframe写入到csv或txt格式的文件中,答案为A。'
A:错 B:对
AI参考:答案是B:对。网络爬虫是一种自动化的网络数据抓取工具,可以自动获取互联网上的数据。它可以按照一定的规则和算法,自动从网站上提取指定信息或数据,以实现数据的收集和分析。因此,网络爬虫可以自动获取互联网数据。'
A:对 B:错
AI参考:正确答案是B:错。DataFrame的apply()方法可以将Python的标准函数应用到行或列。在Python中,使用apply()方法可以将任何函数应用到DataFrame的行或列上,包括Python的标准函数。因此,这个说法是错误的。'
A:错 B:对
AI参考:答案是B:对。在Python的pandas库中,DataFrame的dropna()方法用于删除包含缺失值的行。该方法会返回一个新的DataFrame,其中包含删除缺失值后的有效数据。因此,判断题中的陈述是正确的。'
A:对 B:错
AI参考:答案是A:对。在Python的pandas库中,DataFrame对象的index属性可以用来修改行索引。可以通过设置新的索引值来改变DataFrame的行索引。'
A:该方法将返回所有符合正则表达式的子串 B:该方法将返回一个列表 C:该方法将返回第一个符合正则表达式的子串 D:该方法至少包含两个参数:正则表达式与原字符串
AI参考:关于re.findall()方法描述正确的是(B:该方法将返回一个列表)。re.findall()方法是Python正则表达式模块re中的一个方法,它会在给定的正则表达式匹配的字符串中查找所有匹配的子串,并返回一个列表。因此,选项B是正确的。选项A、C、D虽然部分正确,但并不是re.findall()方法的最准确描述。'
A:text是标签的基本元素之一 B:标签是标签树的基本单元 C:标签树以树形结构表示标签之间的层次关系 D:name是标签的基本元素之一
AI参考:关于标签树与标签描述正确的是:C:标签树以树形结构表示标签之间的层次关系。标签树是一种用于表示标签之间层次关系的图形结构,通常以树形结构表示。标签是标签树的基本单元,每个标签都代表一个特定的概念或实体。文本(text)和名称(name)是标签的属性,但不是标签树的基本元素。因此,选项C是正确的。'
温馨提示支付 ¥1.30 元后可查看付费内容,请先翻页预览!

