- 以下关于pandas库描述正确的是( )。
答案:pandas库集成了数据处理与分析的函数方法###series是pandas库内置的数据类型###dataframe是pandas内置的数据类型
- csv库的read_csv()方法只能将csv格式文件读入dataframe。( )
答案:错
- dataframe的drop_duplicates()方法将返回删除重复行后的新dataframe。( )
答案:对
- 服务器的响应报文的状态行中包含了响应状态码。( )
答案:对
- dataframe的groupby()方法同时对多个字段分组时将返回具有多层索引的dataframe。( )
答案:对
- 与series不同的是dataframe没有行索引。( )
答案:错
- HTML主要用于描述网页的结构。( )
答案:对
- re库的findall()方法默认为正则表达式的贪婪模式。( )
答案:对
- dataframe的groupby()可以对多个字段进行不同函数的聚合运算。( )
答案:对
- beautifulsoup库可将html文档转换为标签树对象。( )
答案:对
- 网络爬虫能够模拟用户访问浏览器的行为。( )
答案:对
- dataframe的fillna()方法将返回填充缺失值后的新dataframe。( )
- pandas库的merge()方法可以将两个dataframe在任意列上对齐连接。( )
- 正则表达式是Python所有的。( )
- Json可以独立于网页的结构与样式传输数据。( )
- pandas库的concat()方法只能同时连接两个dataframe。( )
- 可以通过dataframe的columns属性修改列名。( )
- requests库是处理正则表达式的第三方库。( )
- 在网站的登陆页面,浏览器通过get()方法向服务器传输用户名和密码。( )
- series是pandas库内置的数据类型。( )
- Anaconda是Python的集成开发环境。( )
- 正则表达式由普通字符、元字符与预定义字符构成。( )
- csv库的to_csv()方法可以将dataframe写入到csv或txt格式的文本文件。( )
- dataframe的apply()方法能够将自定义函数应用到dataframe的所有元素。( )
- Jupyter notebook是Python的发行版本。( )
- 以下关于重复值的处理描述错误的是( )。
- 执行以下程序输出的结果是( C)。from bs4 import BeautifulSouphtml='<html>
ss内容已经隐藏,点击付费后查看
执行以下程序输出的结果是( )。from bs4 import BeautifulSouphtml='<html>ss内容已经隐藏,点击付费后查看
执行以下程序输出的结果是( A)。from bs4 import BeautifulSouphtml='<html>ss内容已经隐藏,点击付费后查看
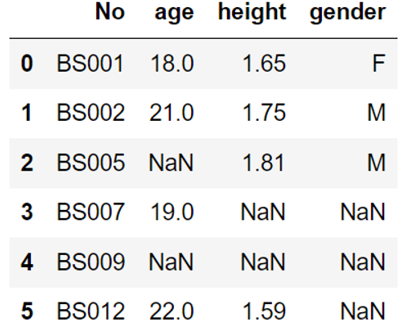 执行以下程序,输出的结果是( A)。from bs4 import BeautifulSouphtml='<html>
执行以下程序,输出的结果是( A)。from bs4 import BeautifulSouphtml='<html>ss内容已经隐藏,点击付费后查看
执行以下程序输出的结果是( B)。import pandas as pdd={'one':[1,3,5,7],'two':[2,4,6,8]}df=pd.DataFrame( )df['three']=df['two']-df['one']df.drop(2,inplace=True)print(df)
正则表达式中能够匹前面的字符或子表达式0次或多次的符号是( )。
运行以下程序后的结果是( )。
关于apply与applymap方法,以下描述错误的是( )。
执行以下程序输出的结果是( C)。import res='abc1234ABC45'a=re.findall('[a-zA-Z]{3}\d+?',s)print( )
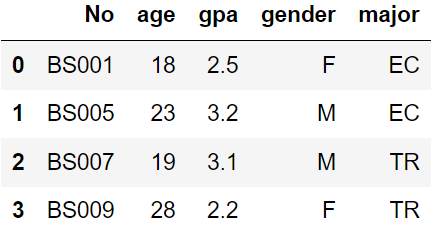
 以下关于dataframe的连接描述错误的是( )。
执行以下程序输出的结果是( D)。from bs4 import BeautifulSouphtml='<html>
以下关于dataframe的连接描述错误的是( )。
执行以下程序输出的结果是( D)。from bs4 import BeautifulSouphtml='<html>ss内容已经隐藏,点击付费后查看
用字典类型的数据来创建一个DataFrame时,它会自动的将以下哪一项作为列名( )。
以下关于时间序列dataframe描述错误的是( )。
使用以下哪一种方法,可以将字符串中的英文字符转换为小写字母( )。
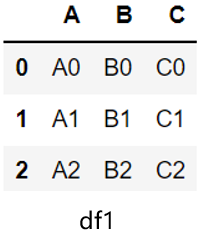
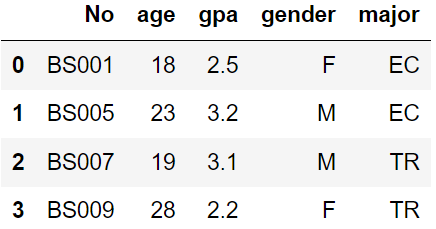 下列描述错误的是( )。
下列描述错误的是( )。

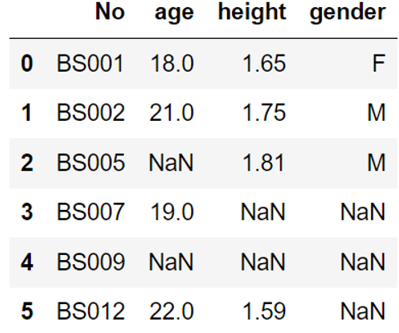
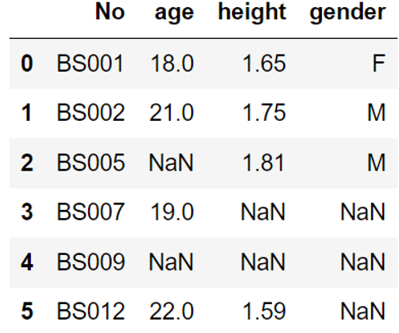 以下关于缺失值的处理描述错误的是( )。
以下关于缺失值的处理描述错误的是( )。
 关于pandas的merge方法描述错误的是( )。
关于pandas的merge方法描述错误的是( )。

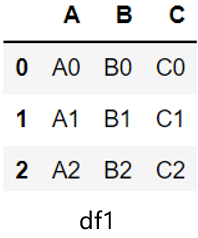 关于pandas的concat方法描述错误的是( )。
关于pandas的concat方法描述错误的是( )。
 Pandas提供的数据类型中,以下哪一项是带索引的一维数组( )。
执行以下程序输出的结果是( A )。import pandas as pdd={'one':[1,3,5,7],'two':[2,4,6,8]}df=pd.DataFrame( )df['three']=df['two']-df['one']df.drop(2)print(df)
执行以下程序输出的结果是( )。import pandas as pds=pd.Series([3,5,6,7,9],index=['a','b','c','d','e'])print(list(s[2:4]))
执行以下程序输出的结果是( A)。import pandas as pdd={'one':[1,3,5,7],'two':[2,4,6,8]}df=pd.DataFrame( )df['three']=df['two']-df['one']print(df[(df.one>3) & (df.two内容已经隐藏,点击付费后查看
执行以下程序输出的结果是( )。import pandas as pds1=pd.Series([3,5,6,7,9])s2=pd.Series([1,2,3,4,1])print((s1+s2).sum())
以下关于JSON模块描述错误的是( )。
以下关于Ajax技术描述错误的是( )
以下关于json数据的描述中,错误的是( )
表单登陆需要使用的请求方法是( )
执行以下程序输出的结果是( )。from bs4 import BeautifulSouphtml='<html>
Pandas提供的数据类型中,以下哪一项是带索引的一维数组( )。
执行以下程序输出的结果是( A )。import pandas as pdd={'one':[1,3,5,7],'two':[2,4,6,8]}df=pd.DataFrame( )df['three']=df['two']-df['one']df.drop(2)print(df)
执行以下程序输出的结果是( )。import pandas as pds=pd.Series([3,5,6,7,9],index=['a','b','c','d','e'])print(list(s[2:4]))
执行以下程序输出的结果是( A)。import pandas as pdd={'one':[1,3,5,7],'two':[2,4,6,8]}df=pd.DataFrame( )df['three']=df['two']-df['one']print(df[(df.one>3) & (df.two内容已经隐藏,点击付费后查看
执行以下程序输出的结果是( )。import pandas as pds1=pd.Series([3,5,6,7,9])s2=pd.Series([1,2,3,4,1])print((s1+s2).sum())
以下关于JSON模块描述错误的是( )。
以下关于Ajax技术描述错误的是( )
以下关于json数据的描述中,错误的是( )
表单登陆需要使用的请求方法是( )
执行以下程序输出的结果是( )。from bs4 import BeautifulSouphtml='<html>ss内容已经隐藏,点击付费后查看
执行以下程序输出的结果是( )。from bs4 import BeautifulSouphtml='<html>ss内容已经隐藏,点击付费后查看
HTML 是整个网页的结构,相当于整个网站的框架。带“<”、“>”符号的都是属于 HTML 的标签,并且标签都是成对出现的。下列说法中,错误的是( )。
下列关于BeautifulSoup中对象类型描述错误的是( )。
执行以下程序输出的结果是( )。from bs4 import BeautifulSouphtml='<html>ss内容已经隐藏,点击付费后查看
以下不能够匹配任意数字字符的正则表达式的是( )。
正则表达式中能够匹前面的字符或子表达式1次或多次的符号是( )。
执行以下程序输出的结果是( D)。import res='ABC123abc456'a=re.findall('[A-Za-z]{2}',s)print( )
以下关于re库的描述中,错误的是( )。
执行以下程序输出的结果是( B)。import res='Bob:12+Alex:23+Emily:33'a=re.findall('\+*(.+?)\+',s)print( )
以下关于实现网络爬虫程序的描述中,错误的是( )。
以下关于爬虫程序的描述中,正确的是( )。
下列选项哪不是爬虫程序的常见类型( )。
下列不属于常用反爬虫手段的是( )。
通过浏览器访问网站服务器的过程,描述错误的是( )。
以下关于数据科学的说法中,正确的是( )。
智能健康手环的运用了以下哪一项数据采集技术( )。
以下描述错误的是( C)。以下哪一项不属于数据科学的基本任务( )。
下列关于大数据特点的说法中,错误的是( ).
温馨提示支付
¥3.00 元后可查看付费内容,请先翻页预览!

