提示:内容已经过期谨慎付费,点击上方查看最新答案
医药统计学
- 组间误差是衡量不同水平下各样本数据之间的误差,它( )。
- 设随机变量和相互独立,且X~N(3,4),Y~N(2,9),则Z=3X-Y ~( )。
- 从标号为1,2,…,101的101个灯泡中任取一个,则取得标号为偶数的灯泡的概率为( )。
- 针对差值总体服从正态分布的小样本配对设计资料,检验两种结果的差异是否有显著性,宜采用的检验法是( )。
- 10名工人生产同一零件,某天所生产的零件件数是:13,15,17,18,19,16,14,15,18,16,则该组数据的众数是( )。
- 某人射击三次,其命中率为0.7,则三次中至多击中一次的概率为( )。
- 已知随机变量X服从参数为2的泊松分布,则随机变量X的方差为( )。
- 三因素三水平的实验,全面设计的析因设计实验要m次,而正交设计的实验要n次,则m和n分别为( )。
- 一医生随机抽取10名患者测量舒张压与胆固醇,获得样本Spearman相关系数为0.676,(临界值rs=0.648),由此可知( )。
- 在散剂分装过程中,随机抽取200袋称重,获得分组资料,判断散剂重量是否服从正态分布应采用的检验方法是( )。
- 假设检验时,若增大样本容量,则犯两类错误的概率( )。
- 设离散型随机变量X的概率分布律为P(X=k)=(k+1)/10,k=0,1,2,3,则E(X)=( )。
- 已知一组数据为8,10,8,5,7,8,6,则该组数据的中位数与众数分别是( )。
- 参数的区间估计与假设检验法都是统计推断的重要内容,它们之间的关系是( )。
- 在假设检验的问题中,显著性水平α的意义是( )。
- 当四格表的周边合计不变时,如果实际频数有变化,则其理论频数( )。
- 设随机变量X~N(0,1),Y~N(0,1),且X与Y相互独立,则X2+Y2~( )。
- 单因素方差分析中,组间变异自由度为(k为组数,N为总例数)( )。
- 以下( )是评价估计量的标准。
- 下列说法正确的是( )。
- 下列关于回归系数和相关系数的说法不正确的是( )。
- 在进行成组比较两样本秩和检验时,以下检验假设不正确的是( )。
- 下列关于小概率事件的说法中不正确的是( )。
- 非参数检验的优点包括( )。
- 下列关于泊松分布的表述,正确的是( )。
- 以下关于Pearson相关系数和Spearman相关系数的说法正确的是( )。
- 关于样本标准差,以下说法正确的是( )。
- 秩的特点包括( )。
- 设总体X~N(μ,σ2),X1,X2,···,Xn(n≥3)是来自总体X的简单样本,则下列估计量中,( )是总体参数μ的无偏估计量。
- 关于矩估计法和最大似然估计法,下列说法正确的是( )。
- 可用于评价多元线性回归模型的拟合优劣程度的指标是( )。
- 下列说法不正确的是( )。
- 数据分布的形状包括( )。
- 若P(B|A)=1,那么以下命题不正确的是( )。
- 实验设计的基本原制是( )。
- 一盒产品中有7只正品,3只次品,无论有放回还是无放回地任取两次,第二次取到正品的概率均为7/10。( )
- 设A表示事件“甲种产品畅销,乙种产品滞销“,则其对立事件为“甲种产品滞销,乙种产品畅销“。( )
- 设A、B是样本空间Ω中的随机事件,则A-B=A-AB。( )
- 一元线性回归模型可以用于预测和控制。( )
- 正交试验设计中要考虑的因素及交互作用的自由度总和不可以大于所选正交表的总自由度。( )
- 方差分析的主要目的是判断各总体是否方差相等。( )
- F分布是围绕平均数μF=0的左右对称分布。( )
- 设总体X~N(μ,σ2), X1,X2,···,Xn为来自总体X的一个样本,则σ2的最大似然估计为
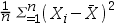 。 ( )
。 ( ) - 正交试验设计试验结果用直观分析法分析结果时,在作表头设计时都必须留有空白列。( )
- 设总体X~N(μ,σ2),其中μ,σ2为已知数,X1,X2,···,Xn为来自总体X的一个样本,
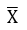 ,S2分别是样本均值和方差,且相互独立,要检验假设H0:σ2=σ02,H1:σ2≠σ02,对检验水平α,其接受域为
,S2分别是样本均值和方差,且相互独立,要检验假设H0:σ2=σ02,H1:σ2≠σ02,对检验水平α,其接受域为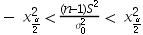 。( )
。( ) - 区间估计中,置信区间长度L与显著性水平是相互制约的,即显著性水平越小,置信区间长度L越大。( )
- 统计推断就是用样本信息推断总体的数量特征即统计规律性。( )
- 随机变量X的数学期望值不存在,则它的方差一定不存在。( )
- 均匀设计之所以能够大大减少试验次数,是因为只考虑试验点的“均匀分散”而不考虑“整齐可比”。( )
A:只包括随机误差 B:只包括系统误差 C:有时包括随机误差,有时包括系统误差 D:既包括随机误差,也包括系统误差
答案:既包括随机误差,也包括系统误差
A:N(11,45) B:N(7,45) C:N(7,21) D:N(7,27)
答案:Z~N(5,72)
A:51/100 B:50/101 C:50/100 D:51/101
AI参考:正确答案是C:50/100。题目要求从标号为1,2,…,101的101个灯泡中任取一个,取得标号为偶数的灯泡的概率,即求标号为偶数的灯泡的数量与总灯泡数量的比值。根据题意,标号为奇数的灯泡有51个,标号为偶数的灯泡有50个,因此取得标号为偶数的灯泡的概率是50/101。因此,选项C是正确答案。'
A:χ2检验 B:F检验 C:t检验 D:u检验
AI参考:正确答案是C:t检验。t检验适用于小样本配对设计资料,而且其假设检验的内容不涉及对比例数的变动率作统计推断。另外,检验的种类有多种,这里明确针对的是样本差异显著性的检验,因此应该选择C选项。而χ2检验和F检验属于独立样本或方差分析中的统计检验方法,u检验是用于两组均数差别的显著性检验,与本题无关。因此,本题答案为C。'
A:15,18 B:15,16,18 C:15 D:18
AI参考:正确答案是D:18。众数是一组数据中出现次数最多的数据,由此可知,该组数据的众数为18。'
A:0.027 B:0.189 C:0.216 D:0.081
答案:0.216
A:1/2 B:0 C:2 D:-2
答案:4
A:36,12 B:27,9 C:12,9 D:9,6
答案:27,9AI参考:正确答案是D。在三因素三水平的实验中,全面设计的析因设计实验需要进行的实验次数m=3×3×3=27次,而正交设计的实验只需要进行n=9次实验即可得到所有可能的组合。因此,正确选项为D:9,6。正交设计是一种特殊的析因设计,它通过选择合适的正交表来减少实验次数,从而节省时间和成本。'
A:舒张压与胆固醇的Spearman相关性较大 B:舒张压与胆固醇的Spearman相关性较小 C:舒张压与胆固醇的Spearman相关性显著 D:舒张压与胆固醇的Spearman相关性不显著
AI参考:答案:D。由题目中给出的信息可知,样本的Spearman相关系数为0.676,临界值为0.648,而样本数量只有10,小于临界值,因此可以判断舒张压与胆固醇的Spearman相关性不显著。故本题选D。注:本题中“显著性”一词在题目中并未提及,因此无需分析判断。'
A:秩和检验 B:t检验 C:χ2拟合优度检验 D:u检验
AI参考:正确答案是D:u检验。在散剂分装过程中,随机抽取200袋称重,获得分组资料,检验散剂重量是否服从正态分布时应该选择U检验,属于正态性检验,即观察计量资料的分布形状,分析是否服从正态分布。所以本题选择D选项。'
A:都减小 B:都不变 C:一个增大一个减小 D:都增大
A:2.2 B:2.4 C:2 D:1.8
AI参考:答案:C推理过程:E(X)=0×(k+1)/10+1×(k+2)/10+2×(k+3)/10+3×(k+4)/10,将k=0,1,2,3代入得E(X)=2。'
A:5,8 B:7,8 C:6,8 D:8,8
AI参考:正确答案是D。这组数据共有8个,按从小到大的顺序排列后,处于中间位置的是第4个数和第5个数,它们都是8,所以中位数是8;在数据8,8,6中,出现次数最多的是8,出现了两次,所以众数是8。因此,本题的正确答案为D。'
A:两种方法解决问题途径是相通的 B:没有任何相同之处 C:区间估计法隐含了假设检验法 D:假设检验法隐含了区间估计法
A:原假设H0不成立,经检验不能拒绝的概率 B:原假设H0成立,经检验不能拒绝的概率 C:原假设H0成立,经检验被拒绝的概率 D:原假设H0不成立,经检验被拒绝的概率
A:增大 B:减小 C:不变 D:不确定是否变化
A:χ2(2) B:t(2) C:N(0,2) D:F(1,1)
A:N-1 B:N-k-1 C:N-k D:k-1
AI参考:正确答案是C:N-K。单因素方差分析中,组间变异自由度为总例数N减去组数K,因此本题选择C。在方差分析中,自由度是统计学中的一个重要概念,它表示样本统计量可以自由取值的最大数量。在单因素方差分析中,组间变异自由度为总例数N减去组数K。因此,正确答案是N-K。'
A:一致性 B:有效性 C:无偏性 D:准确性
AI参考:正确选项为:A:一致性 C:无偏性。评价估计量的标准主要有一致性、有效性、无偏性、准确性等。其中,一致性和无偏性是最重要的标准。一致性是指估计量在样本空间的不同部分上具有相同的性质,即随着样本量的增加,估计量的偏差逐渐减小。无偏性是指估计量的数学期望等于被估计的参数的真实值,即估计量不偏向于高估或低估被估计的参数值。因此,选项A和C是正确的。有效性是指估计量能够尽可能准确地反映被估计的参数的真实值,而准确性则是指估计量在样本空间中的分布具有较好的正态性,能够更好地捕捉样本数据的分布特征。因此,选项B和D不是正确的标准。'
A:χ2分布、t分布、F分布均为连续型分布 B:t分布有两个自由度 C:2 分布和F分布有一个自由度 D:2 分布和F分布均为偏态分布
AI参考:正确答案是:C:2 分布和F分布有一个自由度。A项错误,χ2分布和t分布是连续型分布,而F分布则属于组配型分布,故排除;B项错误,t分布中一个自由度等于0;D项错误,偏态分布包括正偏和负偏两种情况,F分布为对称分布。C项符合χ2分布和F分布的特点。综上,本题答案为C。'
A:对于同一资料,回归系数和相关系数的符号相同 B:对于同一资料,回归系数和相关系数的符号不相同 C:对于同一资料,回归系数和相关系数没有关系 D:对于同一资料,回归系数和相关系数的大小相同
AI参考:正确答案是:B:对于同一资料,回归系数和相关系数的符号不相同。回归系数是模型中的解释变量x对预报变量y的影响大小的指标,它的符号决定模型拟合优劣。而相关系数r只能衡量两变量之间直线相关关系强弱,它不能解释自变量与因变量之间是否呈直线关系以及回归方程的显著性。所以对于同一资料,回归系数和相关系数的符号相同,故A、C正确;回归系数和相关系数的大小不能相同,故D正确;只有当两变量之间呈直线关系时,回归系数和相关系数的大小才相同,故B错误。因此,本题答案为B。'
A:两样本对应的总体均值相同 B:两样本中位数相同 C:两样本均值相同 D:两样本对应的总体分布相同
A:推断总体时可以不考虑的事件 B:基于“小概率事件”的原理可以对某一事件发生与否作出完全正确的判断 C:小概率事件就是不可能事件 D:小概率事件是指当一个事件的发生概率小于等于预先定义的很小的界值α(0<α<1)时,可认为该事件在一次试验中不可能发生
A:适用于未知分布型资料 B:适用于等级资料 C:不受总体分布的限制 D:适用于正态分布资料
AI参考:正确答案是:ABC。非参数检验适用于未知分布型资料、等级资料以及总体分布不明确的资料,故A、B、C选项正确。非参数检验不要求总体服从正态分布,故D选项错误。'
A:泊松分布的数学期望为 B:泊松分布是非对称的 C:泊松分布仅有一个参数 D:泊松分布的方差为
AI参考:正确答案是:A:泊松分布的数学期望为,C:泊松分布仅有一个参数。选项B和D说法不准确,泊松分布不是非对称的,方差不是固定的,与λ有关。所以B、D不正确。所以选择AC。'
A:计算Pearson相关系数时要求两个变量都服从正态分布 B:Pearson相关系数和Spearman相关系数的精确度一样 C:对于等级或相对数资料可以计算Spearman相关系数 D:总体分布类型不知道时可以计算Spearman相关系数
A:反映了样本观察值的离散程度 B:不会小于样本均值 C:度量了数据偏离样本均值的大小 D:反映了均值代表性的好坏
A:对分布形状差别不敏感 B:对中位数差别敏感 C:对中位数差别不敏感 D:对分布形状差别敏感
AI参考:正确答案是【D:对分布形状差别敏感】。秩的特点是对分布形状差别敏感,而不会对中位数差别敏感。这意味着秩更倾向于根据数据分布的整体形状来判断数据的顺序,而不是根据特定数值。因此,D选项“对分布形状差别敏感”是正确的。A、C选项描述的是正态分布的性质,B选项与秩的特征不符。'
A:X1+X2+···Xn B:0.1(6X1+4Xn) C:X1+X2-X3 D:
AI参考:答案为A,C根据正态分布的特点,对于一个简单随机样本,样本均值(即样本的平均数)是总体期望的无偏估计量。因此选项A正确。选项C也是正确的,因为样本中位数是总体中位数的一个无偏估计量。选项B和D都是错误的,因为它们不是无偏估计量。对于选项B,我们需要注意到其中的小数点和常数系数可能影响到该样本大小的比例和数据的不稳定性。选项D中并没有提供明确的样本量或者总体的期望,所以它也不是一个好的估计量。综上所述,正确答案是A和C。'
A:矩估计值与最大似然估计值不一定相同 B:矩估计法较最大似然估计法运算复杂 C:最大似然估计法的依据是最大似然思想 D:一般来说,矩估计法的精度较高
AI参考:关于矩估计法和最大似然估计法,以下说法正确的是:C:最大似然估计法的依据是最大似然思想,D:一般来说,矩估计法的精度较高。解释:A选项说法不准确,矩估计值与最大似然估计值不一定相同,它们在统计学中各有优势,并不完全相同。B选项中,矩估计法与最大似然估计法在复杂程度上没有明显差异,都需要一定的计算能力。C选项正确,最大似然估计法的依据是最大似然思想,也就是在给定数据下,选择一个模型使得样本数据与模型匹配的概率最大。D选项中,矩估计法基于样本数据的样本矩来估计总体参数,其精度相对较高。因此,选项C和D是正确的。'
A:调整决定系数 B:决定系数 C:剩余标准差 D:偏回归系数
AI参考:正确答案是:A:调整决定系数。回归模型的拟合优劣程度,一般通过一些评价指标来衡量,常用的评价指标有:决定系数、剩余标准差、可决系数(又叫R-squared)和调整决定系数(又叫adj.R-squared)。所以选项BCD都正确。本题选择A,即可决系数(又叫R-squared)或者调整决定系数(又叫adj.R-squared)。'
A:总体参数间差异越小,检验效能越大 B:显著性水平α定得越小,检验效能越大 C:个体差异(标准差)越大,检验效能越大 D:样本含量越大,检验效能越大
A:峰度 B:高度 C:偏度 D:宽度
AI参考:正确选项为:A:峰度 C:偏度。数据分布的形状通常用峰度和偏度这两个指标来描述。峰度描述的是数据分布的尖锐程度,即数据分布高峰与两侧的距离;偏度描述的是数据分布的不对称性,即数据分布相对于平均值的集中趋势。而数据分布的高度、宽度描述的是数据分布的离散程度,与峰度和偏度描述的数据分布形状相关,但不是形状本身。因此,本题选择A和C。'
A:P(A-B)=0 B:A-B=Ø C:B⊂A D:A⊂B
AI参考:答案是:D.A⊂B。根据条件概率的定义,若P(B|A)=1,说明事件A发生时,事件B必然发生,因此选项A、B、C都是正确的。选项D不正确,因为事件B发生时,事件A不一定发生,即A和B之间没有必然的包含关系。因此,本题选D。'
A:局部控制 B:配对 C:随机化 D:重复
AI参考:答案是ABCD。实验设计的基本原则包括:随机化、重复、配对或相互对照、局部控制和平衡。这些都是为了确保实验的可靠性和有效性,保证实验结果的客观性和普遍性。具体来说:1. 随机化:是指实验对象的分配是随机的,以便确保结果不受特定的个体差异影响,从而使结果更具客观性。2. 重复:是指在一个实验室或实验组中,需要有足够多的实验重复(例如,几十次或几百次),以确保实验结果的可靠性,降低偶然误差。3. 配对或相互对照:这是为了控制某些潜在的自变量差异对实验结果的影响,例如,可以将一个组内的个体配对,或者用不同的处理水平下的同一组对象进行比较。4. 局部控制:这是指在保证结果客观性的同时,尽可能减少无关变量的影响。这通常通过设立一些限制条件来实现,如限制实验者的参与等。综上所述,实验设计的基本原则都应该是符合要求的选项。所以选项ABCD都是正确的。'
A:对 B:错
AI参考:正确答案是A:对。 一盒产品中有7只正品,3只次品,无论有放回还是无放回地任取两次,第二次取到正品的概率均为7/10,这是因为每次取到正品的概率都是7/10,两次取到正品的概率就是两次各自的概率相乘。无论有放回还是无放回地任取两次,第二次取到正品的概率不受第一次取到什么的影响,因此第二次取到正品的概率均为7/10。所以这个判断题是正确的。"
A:对 B:错
A:对 B:错
AI参考:答案是B:错。 根据事件运算的规则,A-B表示的是发生A但不发生B的样本点,而A-AB表示的是发生A且发生B的样本点被剔除后的样本空间,两者不等价。因此,命题“设A、B是样本空间Ω中的随机事件,则A-B=A-AB”是错误的。"
A:错 B:对
AI参考:答案是B:对。一元线性回归模型可以用于预测,但不能用于控制。它是一种统计模型,用于描述两个变量之间的线性关系。通过使用一元线性回归模型,我们可以预测其中一个变量对于另一个变量的影响,但不能直接控制该变量。因此,这个说法是正确的。"
A:对 B:错
AI参考:答案:B:错。 正交试验设计中要考虑的因素及交互作用的自由度总和不可以大于所选正交表的总自由度。如果超过所选正交表的总自由度,就需要使用扩大试验设计的方法。因此,选项B是错误的。"
A:错 B:对
AI参考:答案是B:对。方差分析的主要目的是判断各总体是否方差相等。方差分析是一种统计方法,用于比较两个或多个样本的差异,其中一个重要的目的就是判断各总体是否方差相等。"
A:对 B:错
A:对 B:错
AI参考:答案:B。根据题目描述,设总体X服从正态分布N(μ,σ2),且有一样本X1,X2,···,Xn来自该总体,则σ2的最大似然估计应该为样本方差σ2的估计值,而不是总体标准差σ的估计值。因此,选项B“错”是正确的。"
A:错 B:对
AI参考:正确答案是B:对。 正交试验设计试验结果用直观分析法分析结果时,在作表头设计时都必须留有空白列。这样可以清楚地看出各因素的主次关系以及它们的交互作用。因此,本题说法正确。"
A:对 B:错
AI参考:正确答案是A。这是一个二项分布的正态性检验问题,由正态分布的性质可知,对于假设检验问题,样本均值的均值与原假设一致时,应接受原假设。在本题中,检验水平α对应的接受域是$[-z_{1-alpha/2}, z_{1-alpha/2}]$,选项中给出了这一正确的信息,所以应该选择A,即“对”。注意不要选择B选项,因为它给出的是一个错误的信息。"
A:错 B:对
AI参考:【答案】B.对。 在区间估计中,显著性水平越小,说明对参数的估计要求越精确,要求的估计误差就越小,即置信区间长度L就会越大。因此本题选择B。"
A:对 B:错
AI参考:统计推断的定义是通过收集样本信息对总体进行推断,以获得总体的数量特征和统计规律性。因此,答案是A:对。"
A:对 B:错
AI参考:答案:B。方差和数学期望是随机变量最重要的数字特征,二者都是描述随机变量取值的平均水平,不同的是一个度量取值偏离度的平均程度,一个度量这些离散程度的平均水平。所以数学期望不存在,不代表方差不存在。因此本题是错误的。"
A:对 B:错
AI参考:答案:B:错。 均匀设计是一种试验设计方法,通过合理安排试验指标的取值范围,使得试验点在试验空间中均匀分散,从而减少了试验次数,提高了试验效率。同时,均匀设计也考虑了试验的可比性,即试验结果的可比较性。因此,均匀设计既考虑了试验点的均匀分散,也考虑了整齐可比。所以,这个题目的说法是错误的。"
温馨提示支付 ¥1.20 元后可查看付费内容,请先翻页预览!

